-
Notifications
You must be signed in to change notification settings - Fork 30
Queries
Queries are used to read various performance counters, implement occlusion query and other gl queries, etc.
The core driver implements various sw queries, to track number of draw calls, number of batches, etc.
Hardware queries typically involve emitting cmdstream to read various counters. In concept, the application starts and stops various different queries in between draw calls:
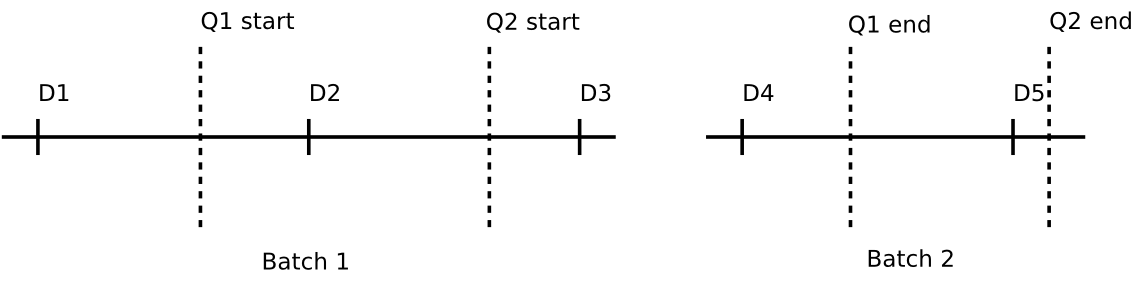In this example, the application starts query Q1 after draw D1, ending it after draw D4, and so on.
A traditional driver, inserts commands into the cmdstream to enable (if necessary) and read whatever counters and the start/stop points. When the application wants to read back the query results, the driver would wait until results are ready, and then calculate the difference between the start and stop counter values.
Typically the driver would also need to insert additional stop/start points at the end/start of batches for queries that span more than one batch/submit.
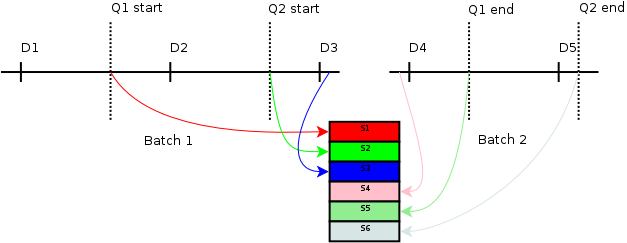This is the view the typical driver has of the example query. The query results would be:
Q1 := (S5 - S4) + (S3 - S1);
Q2 := (S6 - S4) + (S3 - S2);
With adreno, because of the tiling, things get a little more messy, because we need to snapshot sample values per tile, keeping in mind that the # of tiles can differ across batches (due to scissor and/or render target change):
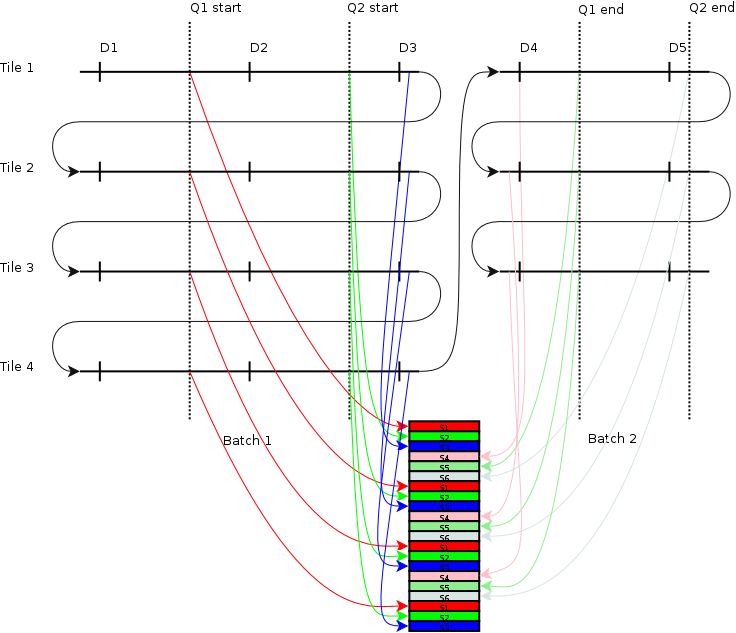The diagram is slightly simplified in that it omits gmem restore/save (which would be after samples S3 and before samples S4).
When the application requests results, the driver must sum the results across all tiles for all batches that the query is part of:
Q1 := tile1(S5 - S4) + tile2(S5 - S4) + tile3(S5 - S4) +
tile1(S3 - S1) + tile2(S3 - S1) + tile3(S3 - S1) + tile4(S3 - S1);
Q2 := tile1(S6 - S4) + tile2(S6 - S4) + tile3(S6 - S4) +
tile1(S3 - S2) + tile2(S3 - S2) + tile3(S3 - S2) + tile4(S3 - S2);
Note that a single cmdstream buffer containing the draw calls is executed for each tile. Therefore to write samples to unique addresses per tile a variant of CP_SET_CONSTANT is used which adds the value of an immediate (in the pm4 packet) to the value of a register specified in the pm4 packet. A scratch register can be used for the per-tile base address, but to have multiple base addresses (for multiple different queries) multiple different scratch registers would be needed. There are a limited number, some of which are already used for other purposes. So it is preferable to interleave all sample values for different queries in a single buffer.