
The most powerful, flexible open-source AI voice agent for Asterisk/FreePBX. Featuring a modular pipeline architecture that lets you mix and match STT, LLM, and TTS providers, plus 6 production-ready golden baselines validated for enterprise deployment.
- 🚀 Quick Start
- 🎉 What's New
- 🌟 Why Asterisk AI Voice Agent?
- ✨ Features
- 🎥 Demo
- 🛠️ AI-Powered Actions
- 🩺 Agent CLI Tools
- ⚙️ Configuration
- 🏗️ Project Architecture
- 📊 Requirements
- 🗺️ Documentation
- 🤝 Contributing
- 💬 Community
- 📝 License
Get the Admin UI running in 2 minutes.
For a complete first successful call walkthrough (dialplan + transport selection + verification), see:
# Clone repository
git clone https://github.com/hkjarral/Asterisk-AI-Voice-Agent.git
cd Asterisk-AI-Voice-Agent
# Run preflight with auto-fix (creates .env, generates JWT_SECRET)
sudo ./preflight.sh --apply-fixesImportant: Preflight creates your
.envfile and generates a secureJWT_SECRET. Always run this first!
# Start the Admin UI container
docker compose -p asterisk-ai-voice-agent up -d --build --force-recreate admin_uiOpen in your browser:
- Local:
http://localhost:3003 - Remote server:
http://<server-ip>:3003
Default Login: admin / admin
Follow the Setup Wizard to configure your providers and make a test call.
⚠️ Security: The Admin UI is accessible on the network. Change the default password immediately and restrict port 3003 via firewall, VPN, or reverse proxy for production use.
GPU users: If you have an NVIDIA GPU for local AI inference, see docs/LOCAL_ONLY_SETUP.md for the GPU compose overlay (
docker-compose.gpu.yml) before building.
# Start ai_engine (required for health checks)
docker compose -p asterisk-ai-voice-agent up -d --build ai_engine
# Check ai_engine health
curl http://localhost:15000/health
# Expected: {"status":"healthy"}
# View logs for any errors
docker compose -p asterisk-ai-voice-agent logs ai_engine | tail -20The wizard will generate the necessary dialplan configuration for your Asterisk server.
Transport selection is configuration-dependent (not strictly “pipelines vs full agents”). Use the validated matrix in:
For users who prefer the command line or need headless setup.
./install.sh
agent setupNote: Legacy commands
agent init,agent doctor, andagent troubleshootremain available as hidden aliases in CLI v6.3.1.
# Configure environment
cp .env.example .env
# Edit .env with your API keys
# Start services
docker compose -p asterisk-ai-voice-agent up -dAdd this to your FreePBX (extensions_custom.conf):
[from-ai-agent]
exten => s,1,NoOp(Asterisk AI Voice Agent)
; Optional per-call overrides:
; - AI_PROVIDER selects a provider/pipeline (otherwise uses default_provider from ai-agent.yaml)
; - AI_CONTEXT selects a context/persona (otherwise uses default context)
same => n,Set(AI_PROVIDER=google_live)
same => n,Set(AI_CONTEXT=sales-agent)
same => n,Stasis(asterisk-ai-voice-agent)
same => n,Hangup()
Notes:
AI_PROVIDERis optional. If unset, the engine follows normal precedence (context provider → default_provider).AI_CONTEXTis optional. Use it to change greeting/persona without changing your default provider/pipeline.- See
docs/FreePBX-Integration-Guide.mdfor channel variable precedence and examples.
Health check:
agent checkView logs:
docker compose -p asterisk-ai-voice-agent logs -f ai_engineLatest Updates
- Backend enable/rebuild flow: One-click backend enable with progress tracking for optional backends (Faster-Whisper, Whisper.cpp, MeloTTS)
- Model lifecycle UX: Expanded model catalog, safer archive extraction, GGUF magic-byte validation, checksum sidecars
- GPU ergonomics:
LOCAL_LLM_GPU_LAYERS=-1auto-detection, preflight warnings, GPU compose overlay improvements - CPU-first onboarding: Defaults to
runtime_mode=minimalon CPU-only hosts - Security hardening: Path traversal protection on all model paths, concurrent rebuild race condition fix, active-call guard on model switch
- Structured local tool gateway: Allowlist-driven tool execution with repair/structured-decision fallbacks
- Hangup guardrails: Blocks hallucinated
hangup_callwithout end-of-call intent (configurable policy modes) - Tool-call parsing robustness: Hardened extraction against malformed wrappers/markdown/control-token leaks
agent check --local/--remotefor Local AI Server STT/LLM/TTS validation- WS protocol contract + smoke test utilities
For full release notes and migration guide, see CHANGELOG.md.
Previous Versions
- Operator config overrides (
ai-agent.local.yaml), live agent transfer tool - ViciDial compatibility, Asterisk config discovery in Admin UI
- OpenAI Realtime GA API, Email system overhaul, NAT/GPU support
- Pre-call HTTP lookups, in-call HTTP tools, and post-call webhooks (Milestone 24)
- Deepgram Voice Agent language configuration
- ExternalMedia RTP greeting cutoff fix
- 🌍 Pre-flight Script: System compatibility checker with auto-fix mode.
- 🔧 Admin UI Fixes: Models page, providers page, dashboard improvements.
- 🛠️ Developer Experience: Code splitting, ESLint + Prettier.
- 🎤 New STT Backends: Kroko ASR, Sherpa-ONNX.
- 🔊 Kokoro TTS: High-quality neural TTS.
- 🔄 Model Management: Dynamic backend switching from Dashboard.
- 📚 Documentation: LOCAL_ONLY_SETUP.md guide.
- 🖥️ Admin UI: Modern web interface (http://localhost:3003).
- 🎙️ ElevenLabs Conversational AI: Premium voice quality provider.
- 🎵 Background Music: Ambient music during AI calls.
- 🔧 Complete Tool Support: Works across ALL pipeline types.
- 📚 Documentation Overhaul: Reorganized structure.
- 💬 Discord Community: Official server integration.
- 🤖 Google Live API: Gemini 2.0 Flash integration.
- 🚀 Interactive Setup:
agent initwizard (agent quickstartremains available for backward compatibility).
- 🔧 Tool Calling System: Transfer calls, send emails.
- 🩺 Agent CLI Tools:
doctor,troubleshoot,demo.
| Feature | Benefit |
|---|---|
| Asterisk-Native | Works directly with your existing Asterisk/FreePBX - no external telephony providers required. |
| Truly Open Source | MIT licensed with complete transparency and control. |
| Modular Architecture | Choose cloud, local, or hybrid - mix providers as needed. |
| Production-Ready | Battle-tested baselines with Call History-first debugging. |
| Cost-Effective | Local Hybrid costs ~$0.001-0.003/minute (LLM only). |
| Privacy-First | Keep audio local while using cloud intelligence. |
-
OpenAI Realtime (Recommended for Quick Start)
- Modern cloud AI with natural conversations (<2s response).
- Config:
config/ai-agent.golden-openai.yaml - Best for: Enterprise deployments, quick setup.
-
Deepgram Voice Agent (Enterprise Cloud)
- Advanced Think stage for complex reasoning (<3s response).
- Config:
config/ai-agent.golden-deepgram.yaml - Best for: Deepgram ecosystem, advanced features.
-
Google Live API (Multimodal AI)
- Gemini Live (Flash) with multimodal capabilities (<2s response).
- Config:
config/ai-agent.golden-google-live.yaml - Best for: Google ecosystem, advanced AI features.
-
ElevenLabs Agent (Premium Voice Quality)
- ElevenLabs Conversational AI with premium voices (<2s response).
- Config:
config/ai-agent.golden-elevenlabs.yaml - Best for: Voice quality priority, natural conversations.
-
Local Hybrid (Privacy-Focused)
- Local STT/TTS + Cloud LLM (OpenAI). Audio stays on-premises.
- Config:
config/ai-agent.golden-local-hybrid.yaml - Best for: Audio privacy, cost control, compliance.
-
Telnyx AI Inference (Cost-Effective Multi-Model)
- Local STT/TTS + Telnyx LLM with 53+ models (GPT-4o, Claude, Llama).
- OpenAI-compatible API with competitive pricing.
- Config:
config/ai-agent.golden-telnyx.yaml - Best for: Model flexibility, cost optimization, multi-provider access.
- MiniMax LLM (High-Performance Cost-Effective)
- Local STT/TTS + MiniMax M2.5 LLM with 204K context window.
- OpenAI-compatible API with tool-calling support.
- Models:
MiniMax-M2.5(peak performance) andMiniMax-M2.5-highspeed(faster). - Activate: set
MINIMAX_API_KEYin.env, then configureproviders.minimax_llminconfig/ai-agent.yaml(see theminimax_llmsection withenabled: true). - Best for: Long-context conversations, cost-effective high-performance LLM.
AVA also supports a Fully Local mode (100% on-premises, no cloud APIs). Three topologies are supported:
| Topology | Latency | Best For |
|---|---|---|
| CPU-Only | 5-15s/turn | Privacy, testing |
| GPU (same box) | 0.5-2s/turn | Production local |
| Split-Server (remote GPU) | 1-3s/turn | PBX on VPS + GPU box |
GPU setup uses docker-compose.gpu.yml overlay with CUDA-enabled llama.cpp. Community-validated: RTX 4090 achieves ~1.0s E2E.
- See: docs/LOCAL_ONLY_SETUP.md (canonical guide for all local topologies)
- Hardware guidance: docs/HARDWARE_REQUIREMENTS.md
Run your own local LLM using Ollama - perfect for privacy-focused deployments:
# In ai-agent.yaml
active_pipeline: local_hybrid
pipelines:
local_hybrid:
stt: local_stt
llm: ollama_llm
tts: local_ttsFeatures:
- No API key required - fully self-hosted on your network
- Tool calling support with compatible models (Llama 3.2, Mistral, Qwen)
- Local Vosk STT + Your Ollama LLM + Local Piper TTS
- Complete privacy - all processing stays on-premises
Requirements:
- Mac Mini, gaming PC, or server with Ollama installed
- 8GB+ RAM (16GB+ recommended for larger models)
- See docs/OLLAMA_SETUP.md for setup guide
Recommended Models:
| Model | Size | Tool Calling |
|---|---|---|
llama3.2 |
2GB | ✅ Yes |
mistral |
4GB | ✅ Yes |
qwen2.5 |
4.7GB | ✅ Yes |
- Tool Calling System: AI-powered actions (transfers, emails) work with any provider.
- Agent CLI Tools:
setup,check,rca,update,versioncommands (legacy aliases:init,doctor,troubleshoot). - Modular Pipeline System: Independent STT, LLM, and TTS provider selection.
- Dual Transport Support: AudioSocket (default in
config/ai-agent.yaml) and ExternalMedia RTP (both supported — see the transport matrix). - Streaming-First Downstream: Streaming playback when possible, with automatic fallback to file playback for robustness.
- High-Performance Architecture: Separate
ai_engineandlocal_ai_servercontainers. - Observability: Built-in Call History for per-call debugging + optional
/metricsscraping. - State Management: SessionStore for centralized, typed call state.
- Barge-In Support: Interrupt handling with configurable gating.
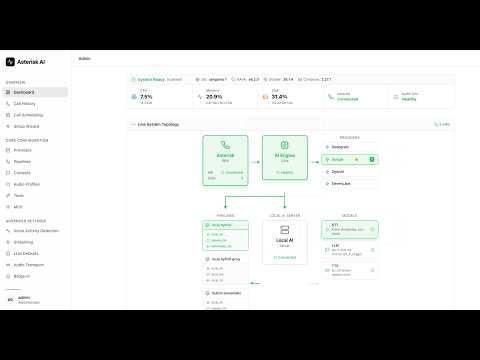
Modern web interface for configuration and system management.
Quick Start:
docker compose -p asterisk-ai-voice-agent up -d --build --force-recreate admin_ui
# Access at: http://localhost:3003
# Login: admin / admin (change immediately!)Key Features:
- Setup Wizard: Visual provider configuration.
- Dashboard: Real-time system metrics, container status, and Asterisk connection indicator.
- Asterisk Setup: Live ARI status, module checklist, config audit with guided fix commands.
- Live Logs: WebSocket-based log streaming.
- YAML Editor: Monaco-based editor with validation.
{kind=link}
Experience our production-ready configurations with a single phone call:
Dial: (925) 736-6718
- Press 5 → Google Live API (Multimodal AI with Gemini 2.0)
- Press 6 → Deepgram Voice Agent (Enterprise cloud with Think stage)
- Press 7 → OpenAI Realtime API (Modern cloud AI, most natural)
- Press 8 → Local Hybrid Pipeline (Privacy-focused, audio stays local)
- Press 9 → ElevenLabs Agent (Santa voice with background music)
- Press 10 → Fully Local Pipeline (100% on-premises, CPU-based)
Your AI agent can perform real-world telephony actions through tool calling.
Caller: "Transfer me to the sales team"
Agent: "I'll connect you to our sales team right away."
[Transfer to sales queue with queue music]
Supported Destinations:
- Extensions: Direct SIP/PJSIP endpoint transfers.
- Queues: ACD queue transfers with position announcements.
- Ring Groups: Multiple agents ring simultaneously.
- Cancel Transfer: "Actually, cancel that" (during ring).
- Hangup Call: Ends call gracefully with farewell.
- Voicemail: Routes to voicemail box.
- Automatic Call Summaries: Admins receive full transcripts and metadata.
- Caller-Requested Transcripts: "Email me a transcript of this call."
| Tool | Description | Status |
|---|---|---|
transfer |
Transfer to extensions, queues, or ring groups | ✅ |
cancel_transfer |
Cancel in-progress transfer (during ring) | ✅ |
hangup_call |
End call gracefully with farewell message | ✅ |
leave_voicemail |
Route caller to voicemail extension | ✅ |
send_email_summary |
Auto-send call summaries to admins | ⚙️ Disabled by default |
request_transcript |
Caller-initiated email transcripts | ⚙️ Disabled by default |
# In ai-agent.yaml
tools:
pre_call_lookup:
kind: generic_http_lookup
phase: pre_call
enabled: true
is_global: false
post_call_webhook:
kind: generic_webhook
phase: post_call
enabled: true
is_global: false
in_call_tools:
intent_router:
kind: in_call_http_lookup
enabled: true
is_global: false
contexts:
default:
pre_call_tools:
- pre_call_lookup
tools:
- intent_router
- hangup_call
post_call_tools:
- post_call_webhookProduction-ready CLI for operations and setup.
Installation:
curl -sSL https://raw.githubusercontent.com/hkjarral/Asterisk-AI-Voice-Agent/main/scripts/install-cli.sh | bashCommands:
agent setup # Interactive setup wizard (recommended)
agent check # Standard diagnostics report (share this output when asking for help)
agent check --local # Verify local AI server (STT, LLM, TTS) on this host
agent check --remote <ip> # Verify local AI server on a remote GPU machine
agent update # Pull latest code + rebuild/restart as needed
agent rca --call <call_id> # Post-call RCA (use Call History to find call_id)
agent version # Version informationconfig/ai-agent.yaml- Golden baseline configs (git-tracked, upstream-managed).config/ai-agent.local.yaml- Operator overrides (git-ignored). Any keys here are deep-merged on top of the base file at startup; all Admin UI and CLI writes go here so upstream updates never conflict..env- Secrets and API keys (git-ignored).
Example .env:
OPENAI_API_KEY=sk-your-key-here
DEEPGRAM_API_KEY=your-key-here
ASTERISK_ARI_USERNAME=asterisk
ASTERISK_ARI_PASSWORD=your-passwordThe engine exposes Prometheus-format metrics at http://<engine-host>:15000/metrics.
Per-call debugging is handled via Admin UI → Call History.
Two-container architecture for performance and scalability:
ai_engine(Lightweight orchestrator): Connects to Asterisk via ARI, manages call lifecycle.local_ai_server(Optional): Runs local STT/LLM/TTS models (Vosk, Faster Whisper, Whisper.cpp, Sherpa, Kroko, Piper, Kokoro, MeloTTS, llama.cpp).
graph LR
A[Asterisk Server] <-->|ARI, RTP| B[ai_engine]
B <-->|API| C[AI Provider]
B <-->|WS| D[local_ai_server]
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#bfb,stroke:#333,stroke-width:2px
style D fill:#fbf,stroke:#333,stroke-width:2px
| Requirement | Details |
|---|---|
| Architecture | x86_64 (AMD64) only |
| OS | Linux with systemd |
| Supported Distros | Ubuntu 20.04+, Debian 11+, RHEL/Rocky/Alma 8+, Fedora 38+, Sangoma Linux |
Note: ARM64 (Apple Silicon, Raspberry Pi) is not currently supported. See Supported Platforms for the full compatibility matrix.
| Type | CPU | RAM | GPU | Disk |
|---|---|---|---|---|
| Cloud (OpenAI/Deepgram) | 2+ cores | 4GB | None | 1GB |
| Local Hybrid (cloud LLM) | 4+ cores | 8GB+ | None | 2GB |
| Fully Local (CPU) | 4+ cores (2020+) | 8-16GB | None | 5GB |
| Fully Local (GPU) | 4+ cores | 8-16GB | RTX 3060+ | 10GB |
- Docker + Docker Compose v2
- Asterisk 18+ with ARI enabled
- FreePBX (recommended) or vanilla Asterisk
The preflight.sh script handles initial setup:
- Seeds
.envfrom.env.examplewith your settings - Prompts for Asterisk config directory location
- Sets
ASTERISK_UID/ASTERISK_GIDto match host permissions (fixes media access issues) - Re-running preflight often resolves permission problems
- Configuration Reference
- Transport Compatibility
- Tuning Recipes
- Supported Platforms
- Local Profiles
- Monitoring Guide
- Roadmap - What's next, planned milestones, and how to get involved
- Developer Documentation
- Architecture Deep Dive
- Contributing Guide
- Milestone History - Completed milestones 1-24
You don't need to know how to code. Our AI assistant AVA writes the code for you — just describe what you want to build.
git clone -b develop https://github.com/hkjarral/Asterisk-AI-Voice-Agent.git
cd Asterisk-AI-Voice-Agent
./scripts/setup-contributor.shThen open in Windsurf and type: "I want to contribute"
| Guide | For |
|---|---|
| Operator Contributor Guide | First-time contributors (no GitHub experience needed) |
| Contributing Guide | Full contribution guidelines and workflow |
| Coding Guidelines | Code standards for all contributions |
| Roadmap | What to work on next (13+ beginner-friendly tasks) |
| Area | Guide | Template |
|---|---|---|
| Full Agent Provider | Guide | Template |
| Pipeline Adapter (STT/LLM/TTS) | Guide | Templates |
| Pre-Call Hook | Guide | Template |
| In-Call Hook | Guide | Template |
| Post-Call Hook | Guide | Template |
- Developer Onboarding - Project overview and first tasks
- Developer Quickstart - Set up your dev environment
- Developer Documentation - Full contributor docs
 hkjarral Architecture, Code |
 Abhishek Telnyx LLM Provider |
 turgutguvercin NumPy Resampler |
 Scarjit Code |
 egorky Bug Fix |
 alemstrom Docs — PBX Setup |
 gcsuri Code — Google Calendar |
See CONTRIBUTORS.md for the full list and Recognition Program for how we recognize contributions.
- Discord Server - Support and discussions
- GitHub Issues - Bug reports
- GitHub Discussions - General chat
This project is licensed under the MIT License. See the LICENSE file for details.
Asterisk AI Voice Agent is free and open source. If it's saving you money, consider supporting development:
Your support funds:
- 🐛 Faster bug fixes and issue responses
- ✨ New provider integrations and features
- 📚 Better documentation and tutorials
If you find this project useful, please also give it a ⭐️!