Home
PiTubeDirect is a simple, cheap, and compact way to add a second processor to your BBC or Master micro. It's the lowest cost way to run a Tube-enhanced Elite on a fast 6502, or CP/M, DOS+, or Panos on the relevant CPU type, or a gigahertz of Native ARM. It's the fastest 6502 you're likely to see, and the highest performance coprocessor.
Second processors used to cost hundreds or thousands, and some are very rare and still expensive. With PiTubeDirect you just add a simple interface to a Raspberry Pi and connect directly to the Tube socket. It can be fitted under a Beeb or inside a Master, or just cable-connected.
The minimal DIY configuration would use:
- a 40 pin IDC cable
- a pair of 74LVC245A level shifters which change the tube interface from 5V to 3.3V levels
- a Raspberry Pi Zero or any Raspberry Pi you already have
- a micro SD card with the PiTubeDirect package on it
The bill-of-materials for this is approximately ten pounds. But for a little more money you can buy one ready made: see Level Shifter Options.
With this project you will have a choice of many different Co Processor:
n Processor - *FX 151,230,n
0 * 65C02 (fast)
1 65C02 (3MHz, for games compatbility)
2 65C102 (fast)
3 65C102 (4MHz, for games compatbility)
4 Z80 (1.21)
5 Z80 (2.00)
6 Z80 (2.2c)
7 Z80 (2.30)
8 80286
9 MC6809
11 PDP-11
12 ARM2
13 32016
14 Disable
15 ARM Native
16 LIB65C02 64K
17 LIB65C02 256K Turbo
18 65C816 (Dossy)
19 65C816 (ReCo)
20 OPC5LS
21 OPC6
22 OPC7
24 65C02 (JIT)
28 Ferranti F100-L
Equivalent speeds are approximate. Generally a Pi 3 will run faster than a Pi 1. For ideas to exercise each of the CPU models, see Examples for each CoPro core.
Here's the minimal configuration, using a Pi Zero and a DIY two-chip level shifter:
 A closer view of the level shifter (a PCB design for this is in progress):
A closer view of the level shifter (a PCB design for this is in progress):
 A closer view of the Pi Zero:
A closer view of the Pi Zero:
 The 65C02 Co Processor running the CLOCKSP benchmark:
The 65C02 Co Processor running the CLOCKSP benchmark:
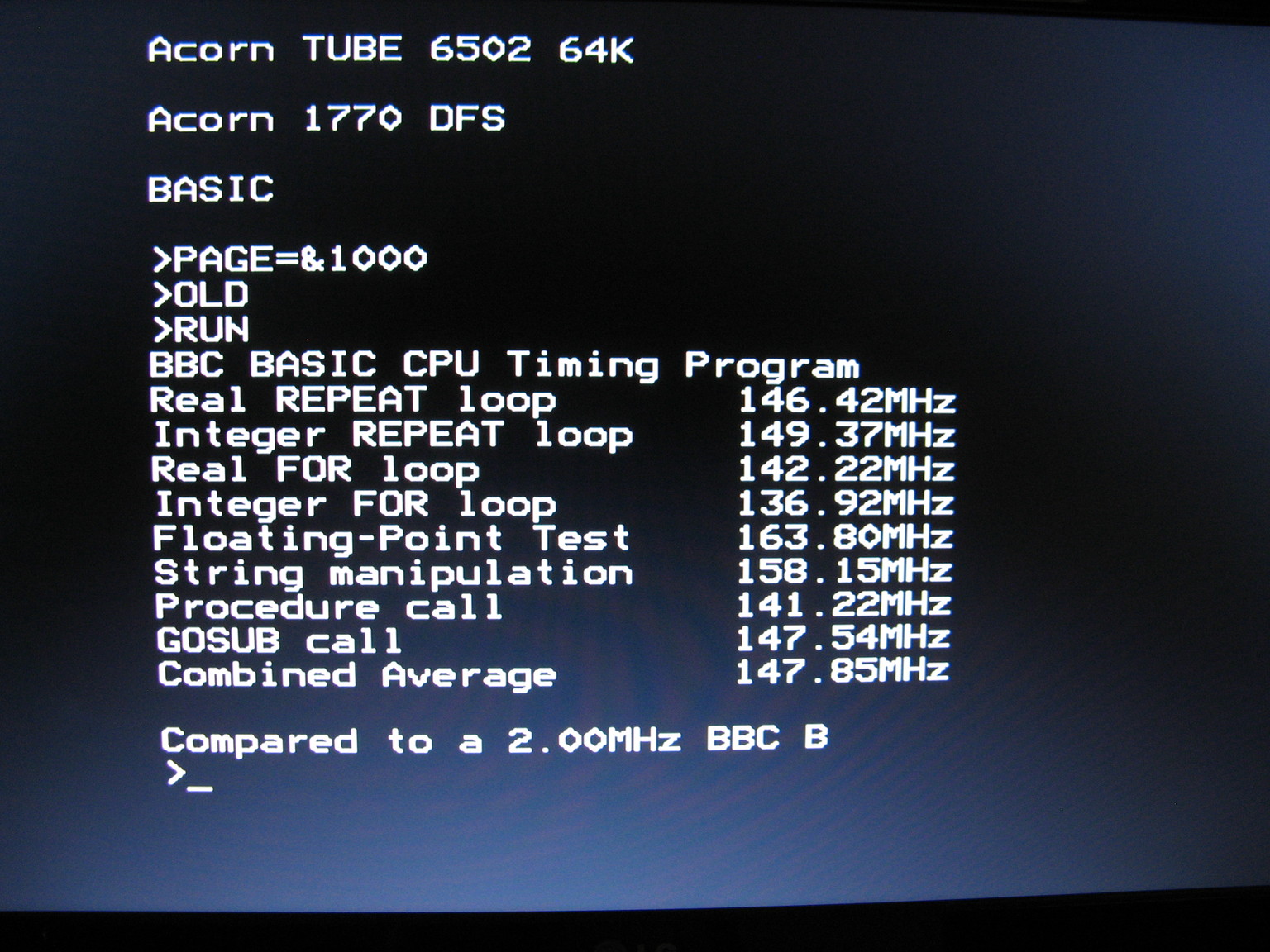 The 65C02 Co Processor running the Tube Elite:
The 65C02 Co Processor running the Tube Elite:
 The ARM Co Processor running the CLOCKSP benchmark:
The ARM Co Processor running the CLOCKSP benchmark:
 The most complex / desirable / expensive Beeb Co Processor was the 32016:
The most complex / desirable / expensive Beeb Co Processor was the 32016:
 This runs an operating system called Panos:
This runs an operating system called Panos:
 And was aimed at the scientific market:
And was aimed at the scientific market:
 It's possible to dynamically switch between Co Processors using *FX 151,230,N (same mechanism the Matchbox Co Processor uses if you are familiar with that):
It's possible to dynamically switch between Co Processors using *FX 151,230,N (same mechanism the Matchbox Co Processor uses if you are familiar with that):
 After hitting BREAK, the Pi has reconfigured itself as an 80x86:
After hitting BREAK, the Pi has reconfigured itself as an 80x86:
 This runs Digital Research DOSPlus 2.1:
This runs Digital Research DOSPlus 2.1:
 Which in turn runs an early graphical windowing system called GEM:
Which in turn runs an early graphical windowing system called GEM:
 Here's the iconic Paint paint program from circa 1986 (30 years ago!):
Here's the iconic Paint paint program from circa 1986 (30 years ago!):
 Finally, the whole system, including an old Atari trackball converted to look like an AMX Mouse:
Finally, the whole system, including an old Atari trackball converted to look like an AMX Mouse:
 You can see the Pi is now a Pi 3, which helps with the larger/more complex emulators (more below).
You can see the Pi is now a Pi 3, which helps with the larger/more complex emulators (more below).
The Tube chip in an original BBC Co Processor is a custom ULA (Uncommitted Logic Array) that provides four bidirectional FIFOs, allowing the BBC Micro (host) and the Co Processor (parasite) to reliably exchange messages with full flow control.
In PiTubeDirect, the functionality of the Tube chip is emulated in software on the Raspberry Pi, and the Tube host interface on the BBC micro is connected to the Raspberry Pi's GPIO header via a pair of 74LVC245A level shifter chips.
The level shifters are necessary because the Tube interface uses 5V levels, where as the Raspberry Pi's GPIO signals use 3.3V levels. Omitting the level shifters would likely damage the Raspberry Pi, so please don't try!
The Tube host interface is simply an extension of the 6502 bus and operates at 2MHz. The nTUBE signal (indicating an access to one of eight host-side tube registers) becomes active ~100ns into the 6502 bus signal. This generates an interrupt on the Pi, which then has about ~400ns (at most) to service the access in real time.
Clearly minimizing interrupt latency is crucial to reliable operation, and we use several techniques here:
- dispense with an operating system - PiTubeDirect is a bare metal system were we control everything
- use a FIQ interrupt (so registers don't have to be stacked)
- carefully hand optimize the FIQ handler
- avoid cache misses within the FIQ handler by locking critical code and data into the cache
- if multiple cores are available, dedicate an entire core to the FIQ handler
Doing all this, it's just possible to achieve the required performance.
For more information, see the FIQ interrupt handler walkthrough
The PiTubeDirect firmware currently includes emulations of the following Beeb Co Processors:
- 65C102 (using 65tube - the fastest known native ARM 65C02 emulation)
- 65C102 (using lib6502 - written in C)
- 80x86 (using Fake86 - written in C)
- ARM2 (using MAME's ARM 2/3/6 emulation - written in C)
- 32016 (using a 32016 emulation that started life in B-Em, and was resurrected earlier this year)
- Z80
- 6809
See Credits and Acknowledgements for who we have to thank for each of these emulations.
Several Pi Models are supported, but within the team we are concentrating on the two extremes:
- the £4.00 Pi Zero (BCM2835/ARM1176) which has a single ARM core that runs at up to 1.0GHz
- the £30.00 Pi 3 (BCM2837/ARM Cortex A53) which has four ARM cores running at up to 1.2GHz
On the Pi Zero, the challenge is reducing interrupt latency, regardless of what the main emulator is doing, as they are both sharing on the same ARM core. The typical interrupt latency we observe is 80ns. However, if the main emulator has a cache miss at exactly the same time as the host attempts to read a tube register, this can increase to 300ns, which means the read data arrives marginally late.
We have focused on the 6502 emulation using 65tube, which has been reduced in size to ~9KB. In theory this should fit inside the 16KB L1 cache. But in practice we still observe occasional late reads (on a scope). That said, Tube Elite does run reasonably reliably. But we are close to the edge here, and this is best viewed as an experiment that's still in process.
We now use the GPU to handle the time critical requests from the host. This now means we don't miss a request.
On the Pi 3, we dedicate one of the cores to interrupt handling, and doing this results in an interrupt latency that is very tightly controlled, and varies between 100ns and 120ns. This provides ample time to reliably service 6502 reads and writes, regardless how large the main emulator is, and what it is doing.
The above has now been moved over to the GPU for increased performance.
PiTubeDirect is closely related, but distinct from, two earlier Beeb Co Processor projects:
- the Matchbox Co Processor (see github and stardot) implements multiple Co Processors using a Xilinx XC6SLX9 FPGA. More than 50 of these have been built and distributed through the stardot forums. The cost is about £50.
- the PiTubeClient project (see github and stardot) is an extension to the Matchbox Co Processor that allows a range of Co Processors to be emulated in software on a Raspberry Pi.
One of the designs in the Matchbox Co Processor is an "SPI Co Processor" containing an VHDL implementation of the Acorn Tube chip together with an SPI slave interface. A software emulation of a Co Processor, running on the Raspberry Pi, can use SPI to read/write the tube registers. The Raspberry Pi firmware to do all this is PiTubeClient.
PiTubeDirect is an evolution of PiTubeClient that avoids the need to use a Matchbox Co Processor. It does this by emulating the Acorn Tube chip itself in software on the Raspberry Pi. This introduces some very hard real time constraints on the Raspberry Pi, and the fun of this project was/is overcoming these.
If you connect a serial cable to the Pi, you will get some diagnostic logging:
FIRMWARE_VERSION : 572ca1d3
BOARD_MODEL : 00000000
BOARD_REVISION : 00a02082
BOARD_MAC_ADDRESS : 5ceb27b8 17d73569
BOARD_SERIAL : ce5c6935 00000000
EMMC_FREQ : 250.000 MHz 250.000 MHz 250.000 MHz
UART_FREQ : 48.000 MHz 1000.000 MHz 1000.000 MHz
ARM_FREQ : 1000.000 MHz 1000.000 MHz 1000.000 MHz
CORE_FREQ : 400.000 MHz 400.000 MHz 400.000 MHz
V3D_FREQ : 300.000 MHz 300.000 MHz 300.000 MHz
H264_FREQ : 300.000 MHz 300.000 MHz 300.000 MHz
ISP_FREQ : 300.000 MHz 300.000 MHz 300.000 MHz
SDRAM_FREQ : 450.000 MHz 450.000 MHz 450.000 MHz
PIXEL_FREQ : 0.000 MHz -1894.967 MHz -1894.967 MHz
PWM_FREQ : 0.000 MHz 500.000 MHz 500.000 MHz
CORE TEMP : 52.08 °C
CORE VOLTAGE : 1.32 V
SDRAM_C VOLTAGE : 1.20 V
SDRAM_P VOLTAGE : 1.20 V
SDRAM_I VOLTAGE : 1.20 V
CMD_LINE : dma.dmachans=0x7f35 bcm2708_fb.fbwidth=656 bcm2708_fb.fbheight=416 bcm2709.boardrev=0xa02082 bcm2709.serial=0xce5c6935 smsc95xx.macaddr=B8:27:EB:5C:69:35 bcm2708_fb.fbswap=1 bcm2709.uart_clock=48000000 vc_mem.mem_base=0x3dc00000 vc_mem.mem_size=0x3f000000 dwc_otg.lpm_enable=0 console=ttyS0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline copro=0 fsck.repair=no rootwait
COPRO : 0
0 0000000000 1100000000
1 0000220000 0000220011
2 0000000010 0000111110
A0 = GPIO27 = mask 08000000
A1 = GPIO02 = mask 00000004
A2 = GPIO03 = mask 00000008
enable_MMU_and_IDCaches
cpsr = 600001d3
extctrl = 00000000 00000040
ttbcr = 00000000
ttbr0 = 01fac04a
sctrl = 00c5183d
ctype = 84448004
On power up, after the MMU, I and D caches are enabled, a short benchmark is run on Core 0:
benchmarking core....
cycle counter = 4000192
L1I_CACHE = 4000013
L1I_CACHE_REFILL = 2
L1D_CACHE = 2
L1D_CACHE_REFILL = 0
L2D_CACHE_REFILL = 2
INST_RETIRED = 6000026
benchmarking io toggling....
cycle counter = 63203584
L1I_CACHE = 3000029
L1I_CACHE_REFILL = 4
L1D_CACHE = 2000002
L1D_CACHE_REFILL = 1
L2D_CACHE_REFILL = 4
INST_RETIRED = 6000028
benchmarking 1KB memory copy....
cycle counter = 3904
L1I_CACHE = 446
L1I_CACHE_REFILL = 5
L1D_CACHE = 520
L1D_CACHE_REFILL = 10
L2D_CACHE_REFILL = 31
INST_RETIRED = 824
benchmarking 2KB memory copy....
cycle counter = 1920
L1I_CACHE = 840
L1I_CACHE_REFILL = 0
L1D_CACHE = 1032
L1D_CACHE_REFILL = 11
L2D_CACHE_REFILL = 19
INST_RETIRED = 1593
benchmarking 4KB memory copy....
cycle counter = 4160
L1I_CACHE = 1597
L1I_CACHE_REFILL = 0
L1D_CACHE = 2056
L1D_CACHE_REFILL = 11
L2D_CACHE_REFILL = 35
INST_RETIRED = 3128
benchmarking 8KB memory copy....
cycle counter = 8960
L1I_CACHE = 3131
L1I_CACHE_REFILL = 0
L1D_CACHE = 4104
L1D_CACHE_REFILL = 26
L2D_CACHE_REFILL = 69
INST_RETIRED = 6200
benchmarking 16KB memory copy....
cycle counter = 15104
L1I_CACHE = 6182
L1I_CACHE_REFILL = 0
L1D_CACHE = 8200
L1D_CACHE_REFILL = 14
L2D_CACHE_REFILL = 132
INST_RETIRED = 12342
benchmarking 32KB memory copy....
cycle counter = 37376
L1I_CACHE = 12325
L1I_CACHE_REFILL = 0
L1D_CACHE = 16392
L1D_CACHE_REFILL = 119
L2D_CACHE_REFILL = 260
INST_RETIRED = 24630
benchmarking 64KB memory copy....
cycle counter = 99200
L1I_CACHE = 24633
L1I_CACHE_REFILL = 0
L1D_CACHE = 32776
L1D_CACHE_REFILL = 189
L2D_CACHE_REFILL = 512
INST_RETIRED = 49208
benchmarking 128KB memory copy....
cycle counter = 224832
L1I_CACHE = 49190
L1I_CACHE_REFILL = 0
L1D_CACHE = 65544
L1D_CACHE_REFILL = 175
L2D_CACHE_REFILL = 1024
INST_RETIRED = 98358
benchmarking 256KB memory copy....
cycle counter = 422272
L1I_CACHE = 98343
L1I_CACHE_REFILL = 0
L1D_CACHE = 131080
L1D_CACHE_REFILL = 264
L2D_CACHE_REFILL = 2048
INST_RETIRED = 196662
benchmarking 512KB memory copy....
cycle counter = 875136
L1I_CACHE = 196647
L1I_CACHE_REFILL = 0
L1D_CACHE = 262152
L1D_CACHE_REFILL = 557
L2D_CACHE_REFILL = 4099
INST_RETIRED = 393270
benchmarking 1024KB memory copy....
cycle counter = 1901376
L1I_CACHE = 393256
L1I_CACHE_REFILL = 0
L1D_CACHE = 524296
L1D_CACHE_REFILL = 268
L2D_CACHE_REFILL = 9069
INST_RETIRED = 786486
The cycle counter is in 1GHz ARM clock cycles.
Then, if there are multiple cores, these are started, and finally the emulator is started:
Raspberry Pi Direct 65C02 (65tube) Client
main running on core 0
starting core 1
SPIN1
starting core 2
SPIN2
starting core 3
CORE3
enable_MMU_and_IDCaches
cpsr = 600001d3
extctrl = 00000000 00000040
ttbcr = 00000000
ttbr0 = 01fac04a
sctrl = 00c5183d
ctype = 84448004
emulator running on core 3
Each time the Co Processor is reset (by hitting BREAK on the Beeb), ARM performance stats can be logged:
cycle counter = 244349525184
L1I_CACHE = 3928583582
L1I_CACHE_REFILL = 79
L1D_CACHE = 123315172
L1D_CACHE_REFILL = 26
L2D_CACHE_REFILL = 113
INST_RETIRED = 26060255
tube reset - copro 0