Add new console frontend to initial model selection, and other model mgmt improvements #2644
Conversation
…ements 1. The invokeai-configure script has now been refactored. The work of selecting and downloading initial models at install time is now done by a script named invokeai-initial-models (module name is ldm.invoke.config.initial_model_select) The calling arguments for invokeai-configure have not changed, so nothing should break. After initializing the root directory, the script calls invokeai-initial-models to let the user select the starting models to install. 2. invokeai-initial-models puts up a console GUI with checkboxes to indicate which models to install. It respects the --default_only and --yes arguments so that CI will continue to work. 3. User can now edit the VAE assigned to diffusers models in the CLI. 4. Fixed a bug that caused a crash during model loading when the VAE is set to None, rather than being empty.
|
I've decided to turn this into a full-featured interface for importing models from the Internet. I'm turning it into a draft while working out the bugs. Currently it is nonfunctional. |
…po_ids - Ability to scan directory not yet implemented - Can't download from Civitai due to incomplete URL download implementation
- quashed multiple bugs in model conversion and importing - found old issue in handling of resume of interrupted downloads - will require extensive testing
- Corrected error that caused --full-precision argument to be ignored when models downloaded using the --yes argument. - Improved autodetection of v1 inpainting files; no longer relies on the file having 'inpaint' in the name.
|
Sorry for the late review. I had tried to review a few days ago but I couldn't get it to run; I think you were in the middle of changes. First impression - a thing of beauty! Running the script, I had a few hiccups:
None of these were picked up as installed - I suppose the script looks at After selecting I did not select
This is a very nice user experience for a shell script, great work! Love it. |
Changes implemented:
|
The script only works off of what's in
The autoencoder is no longer an option to install. Both the legacy and the diffusers versions are now installed behind the scenes for use in later model importation.
See above. The question is what to do when the user has a
You found a bug. Fixed.
Very high praise coming from you! Thanks. |
I have fixed the issue of empty |
Enhancements: 1. Directory-based imports will not attempt to import components of diffusers models. 2. Diffuser directory imports now supported 3. Files that end with .ckpt that are not Stable Diffusion models (such as VAEs) are skipped during import. Bugs identified in Psychedelicious's review: 1. The invokeai-configure form now tracks the current contents of `invokeai.init` correctly. 2. The autoencoders are no longer treated like installable models, but instead are mandatory support models. They will no longer appear in `models.yaml` Bugs identified in Damian's review: 1. If invokeai-model-install is started before the root directory is initialized, it will call invokeai-configure to fix the matter. 2. Fix bug that was causing empty `models.yaml` under certain conditions. 3. Made import textbox smaller 4. Hide the "convert to diffusers" options if nothing to import.
1. Fixed display crash when the number of installed models is less than the number of desired columns to display them. 2. Added --ckpt_convert option to init file.
|
@psychedelicious @damian0815 Thank you for your reviews. I have addressed your concerns and would welcome another round of reviews. |
This should no longer be necessary. If the model installer finds that there is no root
This bug is fixed. |
There was a problem hiding this comment.
- Resizing works, but did crash on me. I ran the script having enlarged my terminal window. Then shrunk it down a bit and it crashed due to not enough window space. If disabling the responsive will prevent crashes, I think that's better than introducing a failure condition. If resizing too small was already a failure condition then responsive is fine.
- NSFW option is detected ✔️
- Unfortunately there is a new bug, appears to be related to the responsive feature. Often (but not always), the last few settings never appear and I just get a blank UI. I didn't catch it on the video, but in this state, when resizing my terminal, the missing settings briefly flash on the screen as the UI resizes. Furthermore, when this is occurring, resizing can cause a different error:
A problem occurred during initialization.
The error was: "list index out of range"
Traceback (most recent call last):
File "/home/bat/Documents/Code/InvokeAI/ldm/invoke/config/invokeai_configure.py", line 828, in main
init_options, models_to_download = run_console_ui(opt, init_file)
File "/home/bat/Documents/Code/InvokeAI/ldm/invoke/config/invokeai_configure.py", line 683, in run_console_ui
editApp.run()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/apNPSApplication.py", line 30, in run
return npyssafewrapper.wrapper(self.__remove_argument_call_main)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/npyssafewrapper.py", line 41, in wrapper
wrapper_no_fork(call_function)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/npyssafewrapper.py", line 97, in wrapper_no_fork
return_code = call_function(_SCREEN)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/apNPSApplication.py", line 25, in __remove_argument_call_main
return self.main()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/apNPSApplicationManaged.py", line 172, in main
self._THISFORM.edit()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/fm_form_edit_loop.py", line 47, in edit
self.edit_loop()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/fm_form_edit_loop.py", line 38, in edit_loop
self._widgets__[self.editw].edit()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 458, in edit
self._edit_loop()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 474, in _edit_loop
self.get_and_use_key_press()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 610, in get_and_use_key_press
self.handle_input(ch)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 95, in handle_input
if self.parent.handle_input(_input):
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 71, in handle_input
self.handlers[_input](_input)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/fmFormMultiPage.py", line 34, in _resize
w._resize()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 326, in _resize
self.resize()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgtitlefield.py", line 82, in resize
self.entry_widget._resize()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 326, in _resize
self.resize()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgmultiline.py", line 105, in resize
self.display()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgwidget.py", line 429, in display
self.update()
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgselectone.py", line 18, in update
super(SelectOne, self).update(clear=clear)
File "/home/bat/invokeai/.venv/lib/python3.10/site-packages/npyscreen/wgmultiline.py", line 220, in update
line = self._my_widgets[-1]
IndexError: list index out of range
Video of missing settings:
Screencast from 22-02-23 18:55:21.webm
If the cause isn't clear, maybe we should skip the resizing for this release, in which case I am happy to approve this.
|
Also, somehow while testing this I ended up with a wonky |
- Disable responsive resizing below starting dimensions (you can make form larger, but not smaller than what it was at startup) - Fix bug that caused multiple --ckpt_convert entries (and similar) to be written to init file.
- The configure script was misnaming the directory for text-inversion-output. - Now fixed.
Major Changes
The invokeai-configure script has now been refactored. The work of selecting and downloading initial models at install time is now done by a script named
invokeai-model-install(module name isldm.invoke.config.model_install)Screen 1 - adjust startup options:

Screen 2 - select SD models:
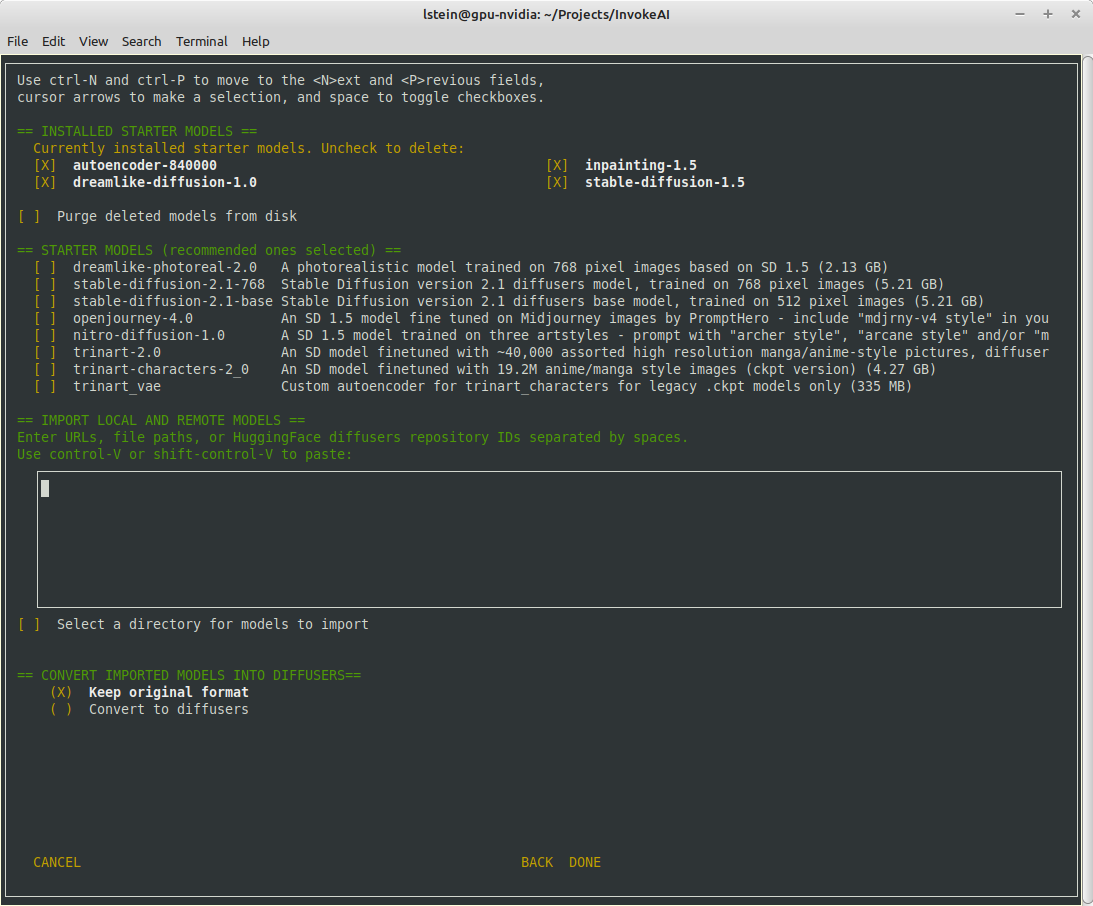
The calling arguments for
invokeai-configurehave not changed, so nothing should break. After initializing the root directory, the script callsinvokeai-model-installto let the user select the starting models to install.invokeai-model-install puts up a console GUI with checkboxes to indicate which models to install. It respects the--default_onlyand--yes` arguments so that CI will continue to work. Here are the various effects you can achieve:invokeai-configureThis will use console-based UI to initialize invokeai.init,
download support models, and choose and download SD models
invokeai-configure --yesWithout activating the GUI, populate invokeai.init with default values,
download support models and download the "recommended" SD models
invokeai-configure --default_onlyActivate the GUI for changing init options, but don't show the SD download
form, and automatically download the default SD model (currently SD-1.5)
invokeai-model-installSelect and install models. This can be used to download arbitrary
models from the Internet, install HuggingFace models using their repo_id,
or watch a directory for models to load at startup time
invokeai-model-install --yesImport the recommended SD models without a GUI
invokeai-model-install --default_onlyAs above, but only import the default model
Flexible Model Imports
The console GUI allows the user to import arbitrary models into InvokeAI using:
The UI allows the user to specify multiple models to bulk import. The user can specify whether to import the ckpt/safetensors as-is, or convert to
diffusers. The user can also designate a directory to be scanned at startup time for checkpoint/safetensors files.Backend Changes
To support the model selection GUI PR introduces a new method in
ldm.invoke.model_managercalled `heuristic_import(). This accepts a string-like object which can be a repo_id, URL, local path or directory. It will figure out what the object is and import it. It interrogates the contents of checkpoint and safetensors files to determine what type of SD model they are -- v1.x, v2.x or v1.x inpainting.Installer
I am attaching a zip file of the installer if you would like to try the process from end to end.
InvokeAI-installer-v2.3.0.zip