Turns a document that describes your article — a full manuscript, an abstract, or a proposal — into a deduplicated, relevance-ranked bibliography in which every entry has been confirmed to exist in a scholarly index. One command runs the whole pipeline: extract a search plan from the document, search several deep-research engines at once, merge and deduplicate, drop anything that cannot be verified, and screen what remains for relevance.
A literature search built on language models has one failure mode that ordinary search engines do not: the model can return a reference that reads perfectly — plausible authors, a plausible title, a plausible year, even a syntactically valid DOI — for a paper that was never written. Deep-research agents that summarise the literature in prose are especially prone to this, because the citation is generated rather than retrieved. A bibliography that contains three fabricated entries among two hundred real ones is worse than no bibliography, since the fabrications are indistinguishable from the rest until a reader tries to follow one.
lit-review-orchestrator is built around removing that failure mode. It draws on
several search channels for breadth, then puts every candidate through a
verification pass (Stage 5b) that confirms the paper exists in OpenAlex, Crossref,
or Semantic Scholar before it is allowed into the final list. A reference that no
index can confirm is dropped and recorded in a separate audit file rather than
silently kept. The DOI check is guarded against the subtle case of a fabricated
title carrying a real-but-unrelated DOI, and the whole pass is designed to fail
safe when an index is merely unreachable rather than the paper being absent.
The pipeline is driven by a document rather than a bare query. Given a .tex or
.docx file, it reads the text and derives the research question, an Undermind
brief, a Scholar Labs question, and a set of Google Scholar queries, so the search
reflects what the article is actually about instead of a hand-typed keyword string.
Several deep-search channels then run concurrently and their results are fused into
one master list. Every reasoning step in the default mode runs at the agent layer
with no Anthropic API key required, split across two keyless models — Claude Opus 4.8
orchestrates, extracts the search plan, runs the keyless web search, and re-ranks the
results, while Sonnet 4.6 subagents handle the remaining steps (a GUI toggle puts
everything on Opus). An
autonomous fallback on the Sonnet/DeepSeek API exists for unattended runs.
- Document-driven search planning. The search plan is extracted from your manuscript or abstract, so you do not have to translate your article into search terms; Stage 0 produces the research question, channel-specific briefs, and a query list from the text itself.
- Several deep-search engines fused into one list. Undermind, Gemini Deep Research, Google Scholar (SearchAPI), and the opt-in Google Scholar Labs each contribute candidates that are merged, enriched, and deduplicated, so coverage does not depend on any single engine's recall.
- Verification by default. Stage 5b cross-checks every candidate against three
scholarly indexes and drops what none can confirm. This is on unless you explicitly
pass
--no-verify. - Reasoning on Opus and Sonnet with no Anthropic API. The LLM steps (plan extraction, dedup judgments, relevance screening, the keyless web search, even Undermind's clarifying answers) are handed to the agent through an emit/ingest seam, so the default run consumes no Anthropic tokens. Work is routed by model: Opus 4.8 orchestrates, extracts the search plan, runs the keyless web search, and re-ranks, while Sonnet 4.6 subagents handle the rest; a Use Opus for all tasks toggle promotes everything to Opus. The API path survives only as an unattended fallback.
- Ranked, screened output. What survives verification is scored for relevance against the research question and delivered as a ranked spreadsheet alongside RIS and BibTeX.
- Requirements
- Quick start
- Using the skill
- Architecture
- Pipeline stages
- The verification guarantee in detail
- Search channels
- CLI flags
- Output
- Skill structure
Python 3.10+ and the packages in requirements.txt (pip install -r requirements.txt,
then playwright install chromium for the Undermind and Scholar Labs browser drivers).
API keys live in ~/.lit-review-pipeline.env (auto-loaded via python-dotenv; copy
lit-review-pipeline.env.example), and a real shell environment variable always wins over
the file. The default agent-driven flow runs the reasoning stages — Stage 0 extraction,
dedup judgments, and screening — at the agent layer inside the conversation, so no
Anthropic key is needed; the work is split between Opus 4.8 (orchestration, Stage 0
plan extraction, the keyless web search, and the relevance re-ranking) and Sonnet 4.6
subagents (everything else), with a GUI toggle to put it all on Opus, and verification and
enrichment draw on the free OpenAlex / Crossref / Semantic Scholar pools.
In the agent-driven flow you can run with zero search accounts: two keyless fallback channels (agent web search, using the agent's own WebSearch/WebFetch, and free index search over OpenAlex / Crossref / Semantic Scholar) find real papers with no key, and Stage 5b verifies them. The keyed channels below are recommended for broader, higher-quality coverage; add whichever you have.
| Variable | Search channel it unlocks |
|---|---|
| (none) | Web search (Stage 4d) + free index search (Stage 4e) — keyless; the "only Claude Code" fallback |
SEARCHAPI_API_KEY |
Google Scholar (Stage 4a) — the default keyed channel and the only one in --quick; also the engine behind SSRN / HeinOnline / forthcoming |
GEMINI_API_KEY |
Gemini Deep Research (Stage 2b) — default-on |
UNDERMIND_EMAIL / UNDERMIND_PASSWORD |
Undermind deep search (Stage 1) — default-on; captured on first run via --login |
Everything runs without these; each adds source coverage, metadata quality, or the no-agent mode.
| Variable | What it adds |
|---|---|
DEEPSEEK_API_KEY |
Fuzzy title-matching when resolving DOIs during enrichment (any path), plus the LLM dedup pass in the autonomous fallback. Without it, enrichment falls back to exact title matches. |
OPENALEX_API_KEY |
OpenAlex Premium enrichment (higher rate limits) |
SCHOLAR_EMAIL / SCHOLAR_PASSWORD |
Google Scholar Labs deep search (Stage 2, opt-in via --scholarlabs); captured on first run via --login |
ANTHROPIC_API_KEY |
Autonomous fallback only (orchestrator.py run unattended): Stage 0, dedup, screening, and Undermind clarifying answers. The agent-driven default needs no Anthropic key. |
Install as a Claude Code skill (recommended). Clone the repo into your Claude Code skills directory and Claude Code auto-discovers it:
git clone https://github.com/kennethkhoocy/lit-review-orchestrator.git ~/.claude/skills/lit-review-orchestrator
pip install -r ~/.claude/skills/lit-review-orchestrator/requirements.txt
cp ~/.claude/skills/lit-review-orchestrator/lit-review-pipeline.env.example ~/.lit-review-pipeline.envThen ask Claude Code for a literature review (or hand it a manuscript): the skill triggers, the settings dialog opens, and the agent-driven pipeline runs from your choices.
Or run it from the command line. Clone it anywhere, install the dependencies, and call the orchestrator directly:
git clone https://github.com/kennethkhoocy/lit-review-orchestrator.git
cd lit-review-orchestrator
pip install -r requirements.txt # one-time
cp lit-review-pipeline.env.example ~/.lit-review-pipeline.env # then fill in keysThe commands below are the autonomous fallback — they run every stage end-to-end as subprocesses with the reasoning steps on the Sonnet/DeepSeek API:
# From a full manuscript
python scripts/orchestrator.py paper.docx --output-dir ~/lit-reviews/mypaper
# From just an abstract (any .tex/.docx describing the article works)
python scripts/orchestrator.py abstract.tex --output-dir ~/lit-reviews/mypaper
# Add opt-in sources; DOI-only dedup
python scripts/orchestrator.py paper.tex --ssrn --nber --no-llm --output-dir out
# Escape hatch: run from a raw query string (skips Stage 0 extraction)
python scripts/orchestrator.py --query "dual-class shares cost of equity" --output-dir outWhen the skill is triggered interactively, a Tkinter settings dialog opens first and hands your choices back to the Claude Code session. It runs nothing itself and calls no API; it is a settings collector.
python scripts/lit_review_gui.py --config-out OUT/gui_config.json # blocks until Run/CancelThe dialog has a Browse field for the document, an output folder that defaults to
the document's own directory, an optional raw-query box, the search channels as
checkboxes — keyed (Undermind, Deep Research, and Google Scholar checked; Scholar Labs
unchecked, since it is opt-in) and keyless (free index search and web search, both on) —
supplementary sources (SSRN on by default, NBER and HeinOnline off) with citation
chaining, a Processing group (Deduplicate, Verify sources, Screen, DOI-only), and an
Advanced group (Quick mode, Max chars, and a Use Opus for all tasks toggle, off by
default). On Run it writes the chosen configuration to --config-out and echoes it to
stdout between ===LITREVIEW_CONFIG_BEGIN=== and ===LITREVIEW_CONFIG_END===, exiting 0;
Cancel or closing the window exits 2 and the run is aborted. The configuration is JSON:
{"document":"…","query":"","output_dir":"…",
"channels":{"undermind":true,"deepresearch":true,"scholar":true,"scholarlabs":false,"freesearch":true,"websearch":true},
"supplementary":{"ssrn":true,"nber":false,"heinonline":false},
"citation_chain":false,"top_seeds":20,
"dedup":true,"verify":true,"screen":true,"no_llm":false,"quick":false,"max_chars":30000,"all_opus":false}Claude parses that JSON and maps it onto the stages: a channel set false is skipped,
output_dir is honoured, Scholar Labs / supplementary / citation run when true,
--no-verify is passed to dedup when verify is false, --no-llm when no_llm is
true, dedup and screen are skipped when false, max_chars is passed to extraction, and
when all_opus is true every subagent is dispatched on Opus instead of the default
Opus/Sonnet split (see The agent-driven run below).
This is the default. Every deterministic stage runs as a subprocess, and the reasoning
stages (plan extraction, dedup judgments, relevance screening, the keyless web search, and
Undermind's clarifying answers) are performed by the agent — the orchestrator and the
subagents it spawns — with no Anthropic API key. The work is routed by model: Opus 4.8
orchestrates the run, extracts the search plan (Stage 0), drives the keyless web search
(Stage 4d), and re-ranks the results (Stage 6 screening), while Sonnet 4.6 subagents
handle the rest (Stage 4a query writing, Stage 5 dedup judgments, and Undermind's
clarifying answers).
Checking Use Opus for all tasks in the GUI ("all_opus": true) promotes every subagent
to Opus, reproducing the original all-Opus behavior; both models run keyless either way. A
Python subprocess cannot spawn subagents, so each reasoning script exposes an
emit/ingest seam: the script does the deterministic work (parsing, candidate-pair
generation, validation, enrichment, merge, and all file output) and hands only the LLM step
out to the agent in the middle, reading the agent's answer back to finish. The full
stage-by-stage commands are in SKILL.md.
python scripts/orchestrator.py <doc> --output-dir OUTRuns every stage end-to-end as subprocesses, with the reasoning stages calling the Anthropic API on Sonnet (DeepSeek for dedup). Use it for unattended runs or when no agent is driving. It is the fallback, retained so nothing is lost when no agent is present.
The diagrams below are hosted PNGs, rendered from the Excalidraw sources in
docs/images/. Node fill colour encodes role: blue = input or
Claude (Opus/Sonnet) reasoning, gray = deterministic (non-LLM) stages and drivers,
yellow = artefacts (prompt/result files, the dropped-papers audit), purple =
data (papers), green = terminal output, and a peach diamond = a decision. A
dashed border marks an opt-in source, a fallback path, or an abort.
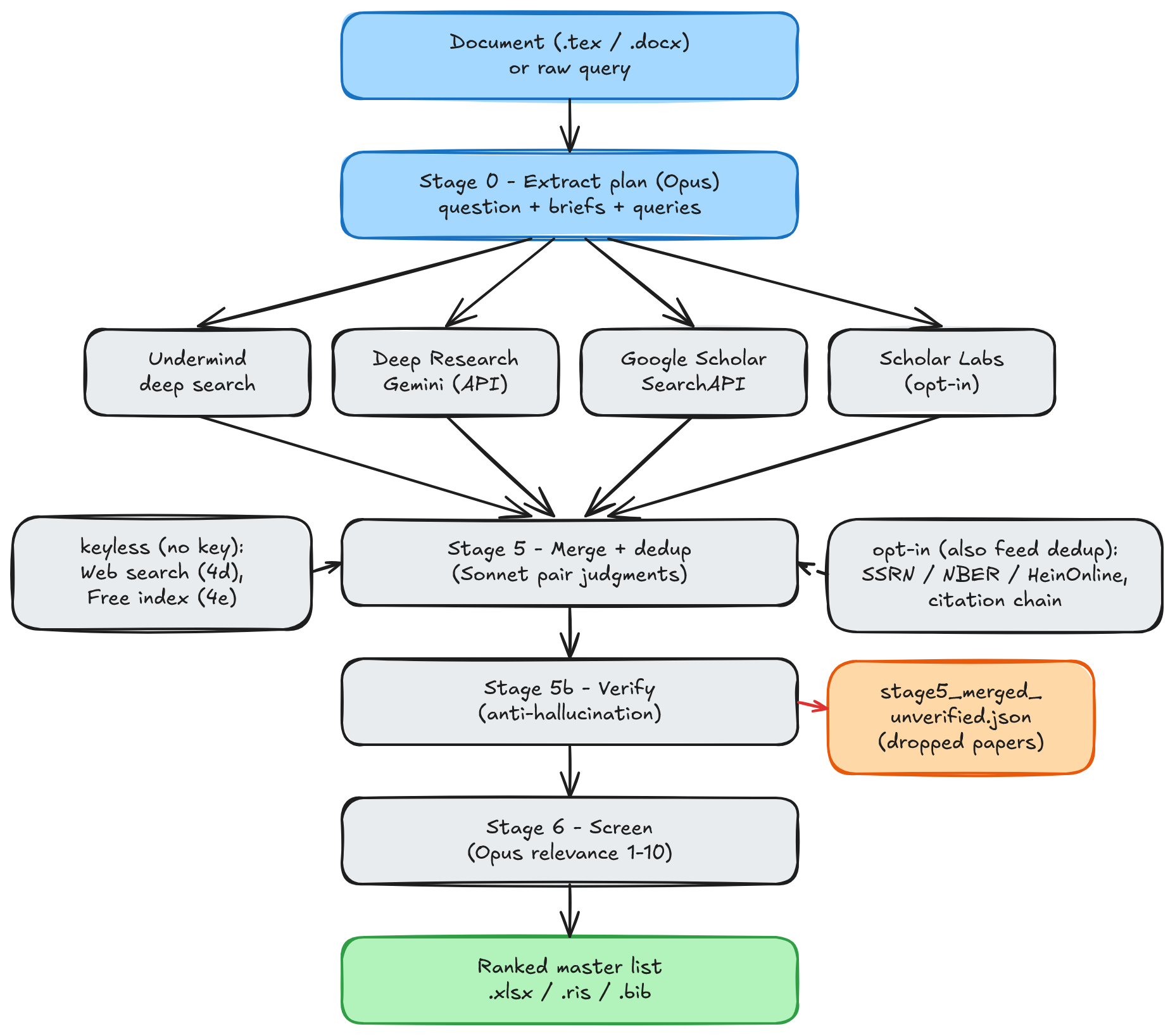
Stage 0 reads the document and derives the search plan. Stages 1, 2b, and 4a (Undermind,
Deep Research, and Google Scholar) run concurrently; Scholar Labs joins them only when
opted in, and supplementary sources and citation chaining feed the merge when enabled.
The keyless channels — web search (Stage 4d) and free index search (Stage 4e) — feed the
merge as well and are the no-key fallback that needs no search account. Stage 5 fuses
everything and deduplicates by DOI and by an LLM fuzzy pass. Stage 5b
verifies what survives, dropping any paper no index can confirm into
stage5_merged_unverified.json. Stage 6 scores the remainder for relevance, and the
ranked list is written in three formats.
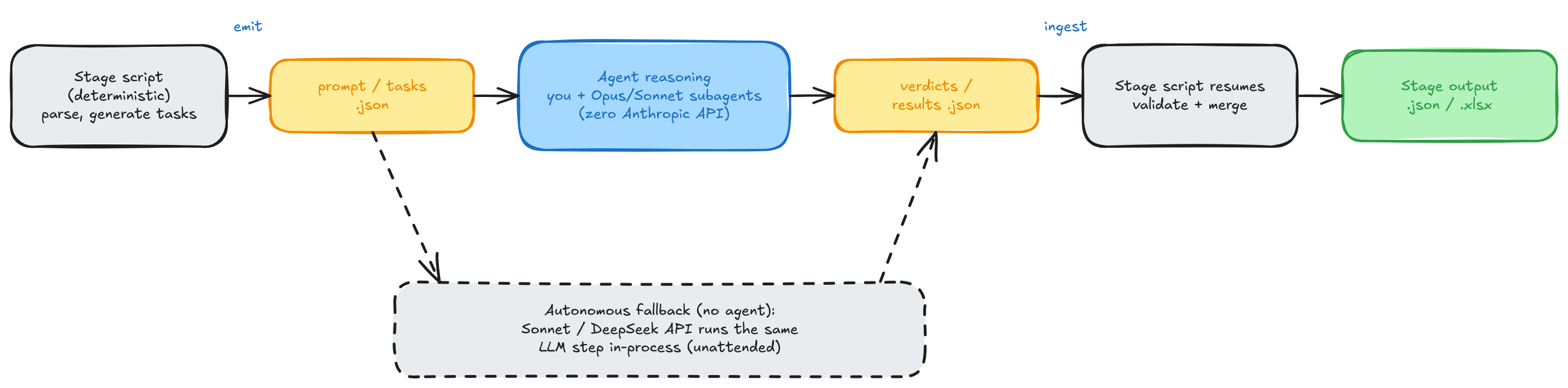
Each reasoning stage is split at the point where judgment is needed. The script handles
everything deterministic and writes a tasks file (extract_prompt.txt,
dedup_pairs.json, screen_tasks.json); the agent reads it, performs the reasoning on
the routed model — fanning out across parallel subagents for large task sets (Sonnet by
default; Opus for Stage 0 extraction, the keyless web search, and the re-ranker, or for
everything when all_opus is set) — and writes the
results back (plan.json, dedup_verdicts.json, screen_results.json); the script
then ingests the results and produces the stage output. Because the seam is a pair of
files, the same scripts support the autonomous fallback unchanged: when no agent is
present, the in-script Sonnet/DeepSeek path fills the seam instead.
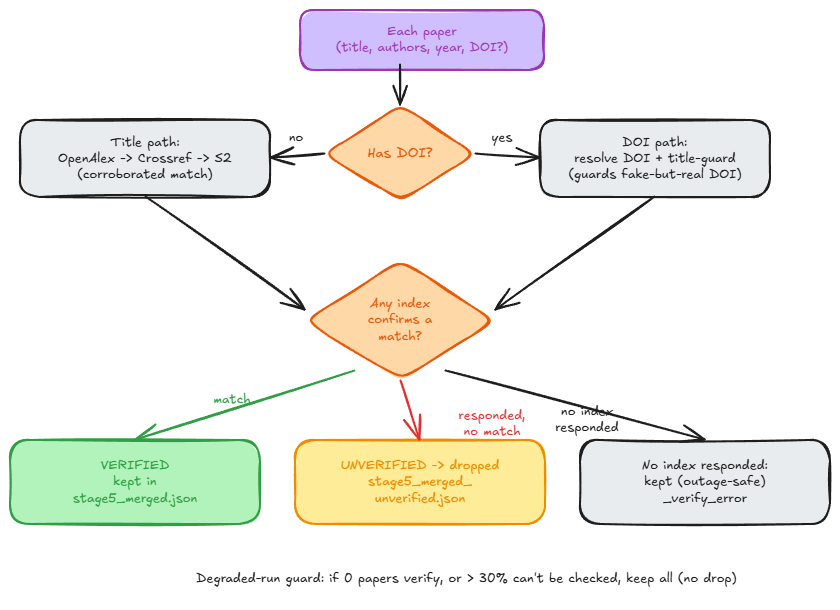
Verification runs over every paper before DOI deduplication, so it covers both the autonomous and the agent-driven paths. A paper with a DOI is confirmed by resolving the DOI and checking that the resolved record's title matches the paper, which is what catches a fabricated title that happens to carry a real DOI. A paper without a DOI is confirmed only by a corroborated title match — a near-exact title, or a strong title backed by author-surname overlap, since a common title and a plausible year alone are not enough. The three outcomes are kept distinct so that an index outage is never mistaken for a missing paper: a paper an index actively reports as absent is dropped, while a paper no index could answer for is tagged and kept. The degraded-run guard is a final safety net — if nothing verifies, or more than thirty percent of papers could not be checked, the run keeps everything rather than emptying the list.
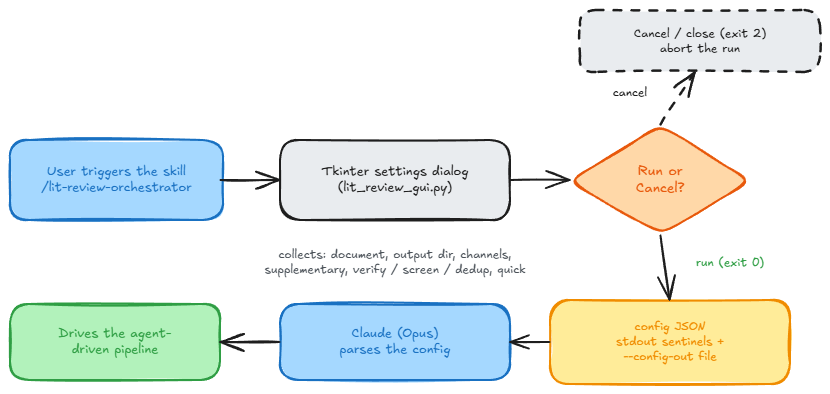
The GUI is a front door that collects settings and returns them to the session. On Run it emits the configuration both to a file and to stdout between sentinel markers, exiting 0; on Cancel or close it exits 2 and the run is aborted. Claude reads the JSON and drives the agent-driven stages accordingly. The dialog itself performs no search and calls no API.
| Stage | Name | Default | What it does |
|---|---|---|---|
| 0 | Extract | on | Parse the document; Claude derives the research question, an Undermind brief, a Scholar Labs question, and Google Scholar queries |
| 1 | Undermind | on | Automated Undermind.ai Classic deep search from the brief (Playwright; signs in with stored credentials) |
| 2 | Scholar Labs | opt-in | Google Scholar Labs deep search via --scholarlabs (Playwright; stored Google login). Off by default — Google rate-limits its Cite/BibTeX export under automation |
| 2b | Deep Research | on | Gemini Deep Research Agent (Interactions API; GEMINI_API_KEY) — an API-driven deep search |
| 4a | Google Scholar | on | SearchAPI.io Google Scholar, driven by the extracted queries |
| 4b | Supplementary | off | SSRN / NBER / HeinOnline / forthcoming (--ssrn --nber --heinonline --forthcoming) |
| 4c | Citation chain | off | Semantic Scholar (--citation-chain; needs DOI-bearing seeds) |
| 5 | Dedup | on | Merge all outputs; metadata enrichment plus DOI and LLM fuzzy deduplication |
| 5b | Verify | on | Cross-check every paper against OpenAlex / Crossref / Semantic Scholar and drop any none can confirm; if an index outage leaves >30% of papers uncheckable, it keeps everything and warns instead of dropping. --no-verify keeps all; dropped papers are saved to stage5_merged_unverified.json |
| 6 | Screen | on | Abstract relevance screening against the research question, with a 1–10 score and structured fields |
Stage 0 runs first; Stages 1, 2b, and 4a run concurrently (Scholar Labs joins them only
with --scholarlabs, supplementary only when opted in); 4c follows; then 5, 5b, and 6.
Stage 5b lives in lit-dedup/scripts/lit_dedup.py and is gated by --verify/--no-verify
(default on; the orchestrator threads the flag through). Its contract:
- A paper is kept only if an index confirms it. Confirmation is either a DOI that resolves to a record whose title matches the paper, or a corroborated title-search match in OpenAlex, Crossref, or Semantic Scholar.
- The DOI path is title-guarded. Resolving a DOI is not sufficient on its own; the resolved record's title must plausibly match the paper. A fabricated title that carries a real-but-unrelated DOI therefore fails verification.
- Title corroboration is strict. A title match requires high string similarity, or a strong-but-not-exact title together with author-surname overlap. A matching year on its own does not corroborate.
- Outage is distinguished from absence. A paper that an index answers for and reports
as absent is dropped (recorded in
stage5_merged_unverified.json). A paper that no index could answer for — every request errored — is tagged_verify_errorand kept, so a network or index outage never quietly deletes real work. - Only an index outage keeps everything. When more than thirty percent of papers could not be checked at all, the pass treats the run as a likely index outage, keeps the full set, and warns instead of dropping. Where the indexes respond and confirm nothing, those papers are dropped like any other unconfirmed result.
- The audit trail is preserved. Every dropped paper is written to
stage5_merged_unverified.json, and the decisions are logged toverification.log.
Both the verification pass and the GUI were reviewed with an independent Codex audit, and the findings — the DOI title-guard, the tightened title corroboration, the outage-versus-absence distinction, and the field carry-forward — were fixed and tested.
- Undermind (Stage 1) drives the Undermind.ai Classic deep search through Playwright,
signing in with stored credentials, answering the clarifying questions with a Sonnet
subagent (Opus when
all_opus) through a file handshake, generating the report, and exporting the references. If login or export fails it degrades gracefully (UNDERMIND_DEFERRED, empty results) and the pipeline continues. - Deep Research (Stage 2b) is the Gemini Deep Research Agent via the Interactions API,
a pure subprocess that needs only
GEMINI_API_KEY. It is the dependable API-driven deep channel and is on by default. - Google Scholar (Stage 4a) is SearchAPI.io Google Scholar driven by the extracted queries; passing your own queries bypasses the Sonnet condense step.
- Scholar Labs (Stage 2) is opt-in (
--scholarlabs). It runs a real headed Chrome positioned off-screen, because Google serves automated/headless Scholar an "unusual traffic" CAPTCHA that a genuine headed window passes. Google rate-limits its Cite/BibTeX export under automation, so it frequently defers, which is why it is off by default. - Supplementary (Stage 4b) — SSRN, HeinOnline, and forthcoming are Google Scholar
searches with a
site:/source:filter, so they mainly force those venues to surface; NBER (thenber.orgAPI) and citation chaining (Semantic Scholar) hit independent indexes and add genuine coverage. - Web search (Stage 4d, keyless) discovers papers on the open web — both the "only
Claude Code" fallback and an add-on alongside the keyed channels. It fans out:
websearch_ingest.py --emit-taskswrites a batched task plan, one Opus subagent per batch runs WebSearch/WebFetch and writes a partial candidates file (so the raw web text stays out of the orchestrator's context), andwebsearch_ingest.py --resultsmerges and dedups them into the pipeline (source="websearch"). It needs no search account or API key, relying only on the agent's web tools plus the free OpenAlex / Crossref / Semantic Scholar verification that follows; keep verification on, since web hits still need confirming. For a few queries you can skip the fan-out and ingest a single results file. Seewebsearch-search/SKILL.md. - Free index search (Stage 4e, keyless) runs the extracted queries against the free
OpenAlex / Crossref / Semantic Scholar keyword-search endpoints and normalizes the real
records into the pipeline. No key needed (optional keys only raise rate limits). It is the
keyless backbone of the "only Claude Code" mode and pairs with web search; unlike web
search, it also runs in the autonomous orchestrator (on by default;
--no-freesearchto skip). Seefreesearch-search/SKILL.md.
| Flag | Default | Description |
|---|---|---|
document |
— | Path to a .tex/.docx document (positional) |
--query |
— | Run from a raw query instead of a document (skips Stage 0) |
--output-dir |
./lit-review-output |
Output directory |
--max-chars |
30000 |
Max document characters sent to the extractor |
--skip |
none | Skip default stages: undermind, deepresearch, scholar, dedup, screen |
--quick |
off | Fast run: SearchAPI Google Scholar only (skips the deep-search stages) |
--scholarlabs |
off | Opt in to the Google Scholar Labs deep search (Stage 2) |
--ssrn --nber --heinonline --forthcoming |
off | Opt-in supplementary sources |
--citation-chain |
off | Opt-in Semantic Scholar citation chaining |
--freesearch / --no-freesearch |
on | Keyless free-index search (Stage 4e); web search (Stage 4d) is agent-only, not in this runner |
--no-llm |
off | DOI-only dedup (skip the LLM pass) |
--verify / --no-verify |
on | Cross-check papers and drop those none can confirm; --no-verify keeps all |
--top-seeds |
20 |
Seeds for citation chaining |
{output-dir}/
├── search_plan.json / .md # research question, Undermind brief, queries, themes
├── scholar_queries.json # the Google Scholar query list
├── undermind_brief.txt # the Undermind brief
├── scholarlabs_query.txt # the Scholar Labs research question
├── stage1_undermind.json / .bib # Undermind results (enriched)
├── stage2_scholarlabs.json / .bib # Scholar Labs results (enriched)
├── stage2b_deepresearch.json / .bib # Gemini Deep Research results
├── stage4a_scholar.json / .ris
├── stage5_merged.json / .ris # deduplicated, verified master list
├── stage5_merged_unverified.json # papers dropped by verification (audit trail)
├── stage6_screened.json/.xlsx/.ris # ALL screened papers, scored & ranked (no score filter)
├── stage6_screened.bib # screened papers (BibTeX), score >= 4 only
├── stage6_filtered.json/.xlsx # score >= 4 subset (the shortlist)
├── dedup_log.json / dedup_report.md / verification.log
└── pipeline.log
lit-review-orchestrator/
├── SKILL.md # canonical invocation reference
├── README.md # this document
├── docs/images/ # Excalidraw diagram sources (.png + .excalidraw.json)
├── requirements.txt
├── lit-review-pipeline.env.example
├── scripts/
│ ├── orchestrator.py # the controller (autonomous fallback)
│ ├── lit_review_gui.py # interactive settings dialog (GUI front door)
│ ├── manuscript_parser.py # bundled .docx/.tex parser
│ └── extract_search_plan.py # Stage 0 (Claude)
├── undermind-search/ # Stage 1 (Playwright driver + ingest)
├── scholarlabs-search/ # Stage 2 (Playwright driver + ingest)
├── deepresearch-search/ # Stage 2b (Gemini Deep Research API)
├── supplementary-search/ # Google Scholar + opt-in sources
├── lit-dedup/ # Stage 5 + 5b verification
├── lit-screen/ # Stage 6
├── examples/sample_manuscript.tex
└── _legacy/ # previous Undermind Playwright automation
The four architecture diagrams above are hosted at
https://kennethkhoocy.github.io/files/lit-review-orchestrator/, with editable
Excalidraw sources in docs/images/.