Add an XLMRobertaMaskedLM task model #950
Conversation
|
Hey @mattdangerw @chenmoneygithub this PR ready for review. |
|
/gcbrun |
|
This is weird, my black is upto date, and even after running
Further, black version 22.6.0, tf 2.12.0 (bumped up) |

|
PR looks great but I had one comment that might help if you would like to read it. take a look at this table and the implementation: and this will create a sentencepiece tokenizer with only three special tokens like what is in the mentioned table. thank you. |
|
@shivance Missed your earlier comment. It seems that black is not working properly, could you try adding a dummy line which is long enough to break black style and rerun the formatting script? If it's not getting formatted, maybe your virtual environment has some conflict. |
|
@abuelnasr0 has a good point! We may want to look through the original code on fairseq and see how they handle the mask token. Ideally we can use the same ID that they used for pre-training, that will give us better out of box results for this task. @abheesht17 helped figure out a similar issue for DebertaV3, so I'll tag him to see if he has thoughts! |
@chenmoneygithub I figured out the reason of black's behaviour is python 3.10 environment which I started using lately, weird thing is none of the imports are working, I've fixed it by creating a new python 3.9 environment. Code format CI test pass now. |
|
@mattdangerw FairSeq XLM Roberta is using same interface as roberta.
I just observed that all of our other tokenizers don't hard code the special token ids, except XLM roberta And probably this is what @abuelnasr0 wanted to point out in #930? following the format like other tokenizers do like
|
|
@shivance, we should keep the hardcoded special tokens. For the mask token, i.e., Inside Inside Inside Inside Inside (I've identified an issue with how OOV tokens are handled here, will open a PR, but this shouldn't block your work. Edit: Here is the PR.) For |
|
Still WIP |
|
Hi @abheesht17 , |
keras_nlp/models/xlm_roberta/xlm_roberta_masked_lm_preprocessor.py
Outdated
Show resolved
Hide resolved
| sequence_length=512, | ||
| truncate="round_robin", | ||
| mask_selection_rate=0.15, | ||
| mask_selection_length=96, |
There was a problem hiding this comment.
I am not sure, is 96 a good default for XLM-R MLM? @abheesht17
There was a problem hiding this comment.
Should be good! Max sequence length of the model is 512, mask rate above is 0.15, so 76 average. 96 should cover almost all samples.
| self.pad_token_id = 1 # <pad> | ||
| self.end_token_id = 2 # </s> | ||
| self.unk_token_id = 3 # <unk> | ||
| self.mask_token_id = self.vocabulary_size() - 1 # <mask> |
There was a problem hiding this comment.
I did not carefully read XLM-R tokenization part, will let Matt check this. @mattdangerw
|
Addressed all the comments except ones left for @mattdangerw and @abheesht17 's review. |
There was a problem hiding this comment.
Thanks! This looks good to me. Have we checked that we are using the same index for the mask token that fairseq is doing.
Also, do we have a colab testing if this works end to end? Something like https://gist.github.com/mattdangerw/b16c257973762a0b4ab9a34f6a932cc1
| generates label weights. | ||
| Examples: | ||
| ```python |
There was a problem hiding this comment.
nit: we have this style elsewhere (just add one empty line and the sentence below)...
Examples:
Directly calling the layer on data.
...example code block here...
There was a problem hiding this comment.
I didn't get that, all other files have similar formatting
https://github.com/keras-team/keras-nlp/blob/aaa6d230a42783eae6d9d695e1cc5de2c3b68f8b/keras_nlp/models/deberta_v3/deberta_v3_masked_lm_preprocessor.py#L73-L80
There was a problem hiding this comment.
I guess I was thinking this, but we still aren't consistent in the new style...
Indeed the fairseq & HF implementation of XLMRoberta have mask as last token in vocab |
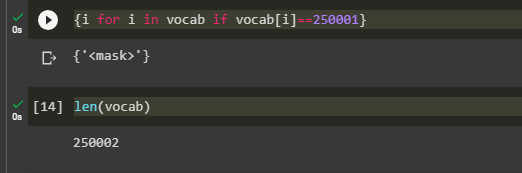
|
Hey @mattdangerw regarding the colab, it's going out of memory for xlm roberta base multi, even with the 1% of training set, memory is not able to hold it up. |
Got it! Thanks for letting me know. We probably should run some sort of test here to sanity check before we merge. I will look into doing it on GCP. |
|
Actually was able to test this out via a "colab pro" GPU. And it works great! https://colab.research.google.com/gist/mattdangerw/ec3cf790c11773ed5f5e335df47480b1/xlmr-mlm.ipynb |
|
/gcbrun |
|
Actually, the training flow works great, but there is a still an error during |
|
@shivance we probably want to copy these lines for now... https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/deberta_v3/deberta_v3_tokenizer.py#L125-L127 |
|
WIP |
|
Please review |
|
/gcbrun |
Closes #720