|
| 1 | +# 30. 串联所有单词的子串 |
| 2 | + |
| 3 | +https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/ |
| 4 | + |
| 5 | +- [30. 串联所有单词的子串](#30-串联所有单词的子串) |
| 6 | + - [题目描述](#题目描述) |
| 7 | + - [方法 1: 哈希表](#方法-1-哈希表) |
| 8 | + - [思路](#思路) |
| 9 | + - [复杂度分析](#复杂度分析) |
| 10 | + - [代码](#代码) |
| 11 | + |
| 12 | +## 题目描述 |
| 13 | + |
| 14 | +``` |
| 15 | +给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。 |
| 16 | +
|
| 17 | +注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。 |
| 18 | +
|
| 19 | + |
| 20 | +
|
| 21 | +示例 1: |
| 22 | +
|
| 23 | +输入: |
| 24 | + s = "barfoothefoobarman", |
| 25 | + words = ["foo","bar"] |
| 26 | +输出:[0,9] |
| 27 | +解释: |
| 28 | +从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。 |
| 29 | +输出的顺序不重要, [9,0] 也是有效答案。 |
| 30 | +示例 2: |
| 31 | +
|
| 32 | +输入: |
| 33 | + s = "wordgoodgoodgoodbestword", |
| 34 | + words = ["word","good","best","word"] |
| 35 | +输出:[] |
| 36 | +
|
| 37 | +来源:力扣(LeetCode) |
| 38 | +链接:https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words |
| 39 | +著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。 |
| 40 | +``` |
| 41 | + |
| 42 | +## 方法 1: 哈希表 |
| 43 | + |
| 44 | +### 思路 |
| 45 | + |
| 46 | +naive 的想法是,将 words 里面的单词组合成字符串,然后到 s 里面去找有没有跟它一样的子串。但是,这样子时间复杂度太高了,因为 words 的组合有 `words.length!` 种,总复杂度差不多就是 `s.length * words.length!` 了。 |
| 47 | + |
| 48 | +那我们反过来想,s 的子串最多只有 `s.length` 个,那我们只要判断 s 的每个子串是不是刚好由 words 数组里面的所有单词组成的就可以了。所以说,如果子串是刚好匹配 words 的单词的话,说明子串和 words 组成的字符串是两种组合情况,虽然排序不同,但包含的单词种类和数量是一样的。 |
| 49 | + |
| 50 | +所以解决方法就很明显了: |
| 51 | + |
| 52 | +- 我们可以用哈希表来记录 words 里面有哪些单词,以及它们分别出现过几次(注意检查每个 s 子串时,哈希表都是新的)。 |
| 53 | +- 然后开始遍历一个 s 的子串,将它截成一个个单词的长度,去哈希表中查询。 |
| 54 | +- 如果出现在子串中的单词能在哈希表中找到,就将它的数量 -1,对消掉一个。 |
| 55 | +- 如果这个单词在哈希表中找不到,或者数量已经变成了 0,就说明这个子串已经不符合我们的要求了,可以停止之后的比较了。 |
| 56 | +- 如果子串的单词都比较完毕,然后哈希表中所有单词的数量也都刚好变成 0,就说明这个子串就是我们要找的。(这里到判断可以有多种,比如在开始子串比较之前用一个 count 变量来进行计数,如果子串比较结束后 count 刚好等于 words 的长度,就说明找到了符合要求的子串) |
| 57 | +- 接着换另一个子串,继续上述步骤。 |
| 58 | + |
| 59 | +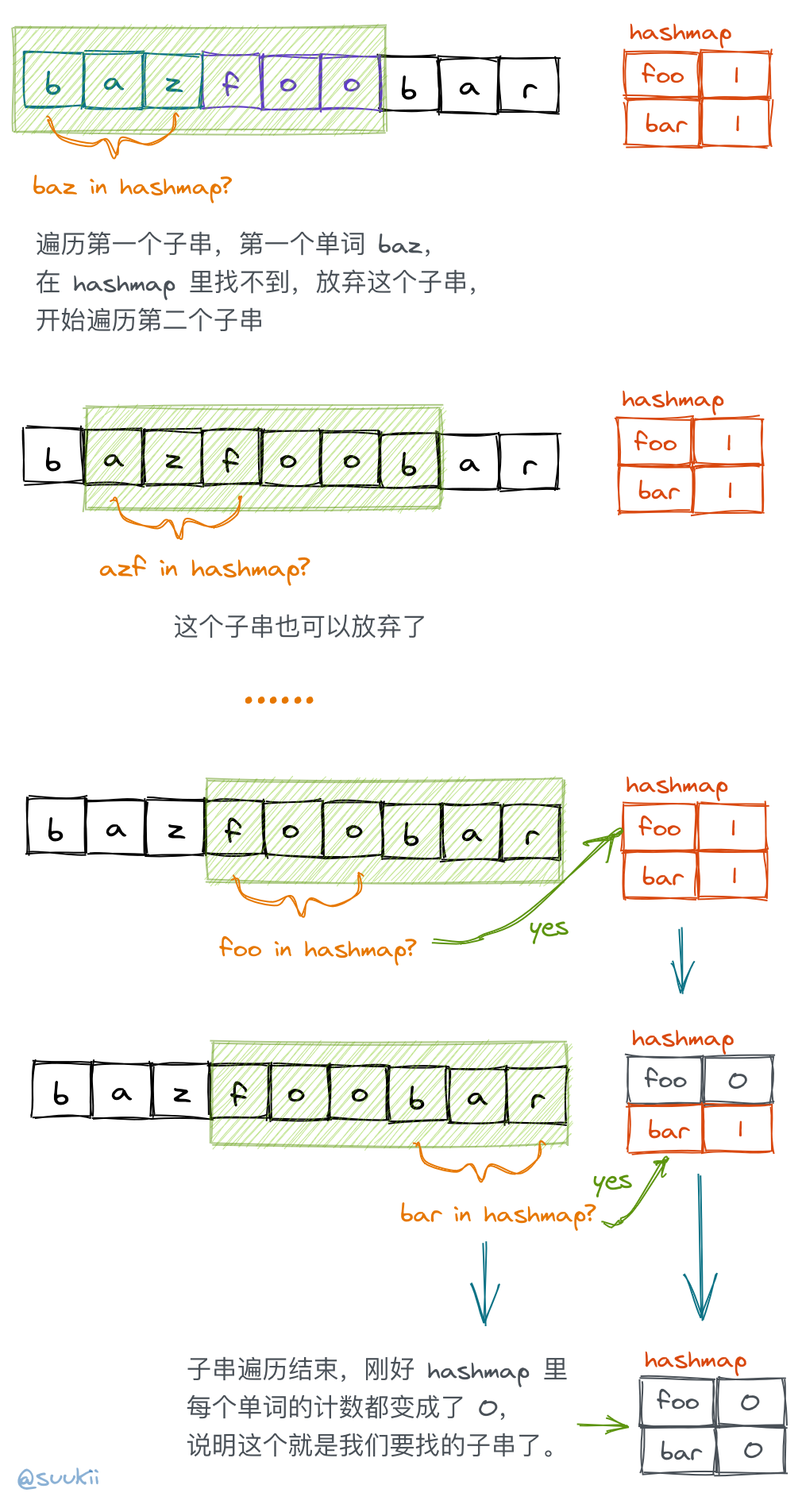 |
| 60 | + |
| 61 | +### 复杂度分析 |
| 62 | + |
| 63 | +- 时间复杂度:$(n-k)*k$,n 是字符串 s 的长度,k 是单词的长度。 |
| 64 | +- 空间复杂度:$m$,m 是 words 数组的长度,哈希表的空间。 |
| 65 | + |
| 66 | +### 代码 |
| 67 | + |
| 68 | +JavaScript Code |
| 69 | + |
| 70 | +```js |
| 71 | +/** |
| 72 | + * @param {string} s |
| 73 | + * @param {string[]} words |
| 74 | + * @return {number[]} |
| 75 | + */ |
| 76 | +var findSubstring = function (s, words) { |
| 77 | + const wordSize = words[0].length; |
| 78 | + const substringLen = wordSize * words.length; |
| 79 | + |
| 80 | + const wordsCount = {}; |
| 81 | + words.forEach(w => (wordsCount[w] = (wordsCount[w] || 0) + 1)); |
| 82 | + |
| 83 | + const res = []; |
| 84 | + for (let i = 0; i <= s.length - substringLen; i++) { |
| 85 | + const tempCount = { ...wordsCount }; |
| 86 | + let count = words.length; |
| 87 | + |
| 88 | + for (let j = i; j < i + substringLen; j += wordSize) { |
| 89 | + const word = s.slice(j, j + wordSize); |
| 90 | + |
| 91 | + if (!(word in tempCount) || tempCount[word] <= 0) break; |
| 92 | + |
| 93 | + tempCount[word]--; |
| 94 | + count--; |
| 95 | + } |
| 96 | + |
| 97 | + if (count === 0) res.push(i); |
| 98 | + } |
| 99 | + return res; |
| 100 | +}; |
| 101 | +``` |
0 commit comments