TCMalloc #23
Description
TCmalloc
TCMalloc 优势
Golang的内存分配是基于TCMalloc来实现的,TCMalloc相较于传统的Ptmalloc,性能提升了很多。根据文章来看,主要的优化有几点:
- 小对象无锁,每个
thread有自己的cache,分配更快 - 大对象使用自旋锁,每个
thread都可以重用这部分的空间。Ptmalloc为每个thread分配的arena对其他thread都是不可见的,会导致内存浪费。 - 占用更少的空间,
TCmalloc分配N个8字节对象可能要使用大约8N * 1.01字节的空间,Ptmalloc使用4byte的header来描述一个对象,一共需要16N字节。
TCMalloc介绍
TCMalloc的介绍可以参考
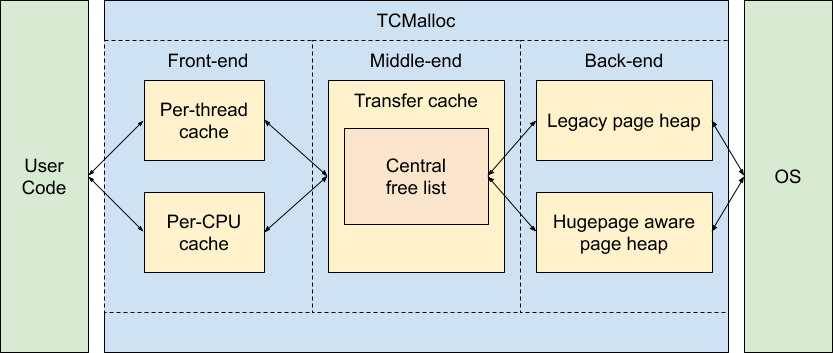
这里主要把TCMalloc分为了3个部分:
front-end让用户代码可以更快的分配和释放内存,这里可以理解为ThreadCachemiddle-end用来刷新front-endcache,这里可以理解为CentralCacheback-end从os获取内存,这里可以理解为PageHeap
几个概念先介绍下,方便后面更容易理解
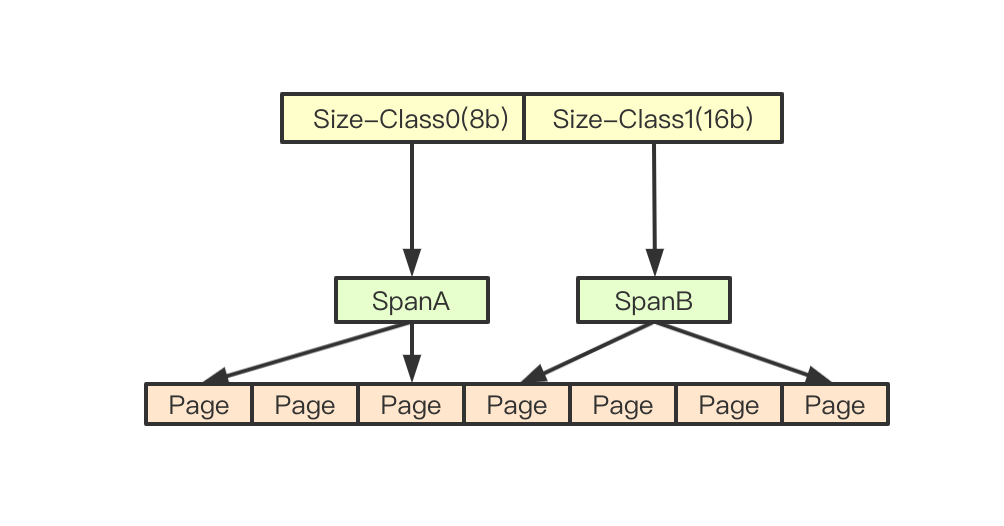
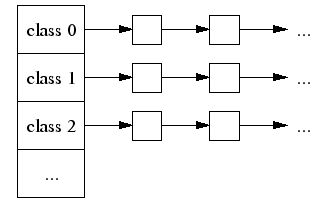
- size-class 表示的是ThreadCache里面的不同大小的链表,里面存放的是object数组
- object size-class里面存储的对象
- page TCmalloc里面一个Page为自定义(比如4K),所有的分配操作都是基于page
- span 一个span包含多个page
Front-end
Front-end 是用来处理那些申请内存的请求的,里面的内存同一时间只能给一个线程使用,分配操作是无锁的。
申请内存的操作很简单,根据对象的大小判断,小对象的分配直接从ThreadCache里面获取,拿不到的话就从middle-end获取,middle-end也没有的话就直接从back-end获取。大对象的获取则是直接从back-end一侧获取,大对象不会在middle-end中去cache。
对象的释放也是根据大小来判断,小对象放回front-end, 大对象放回back-end。
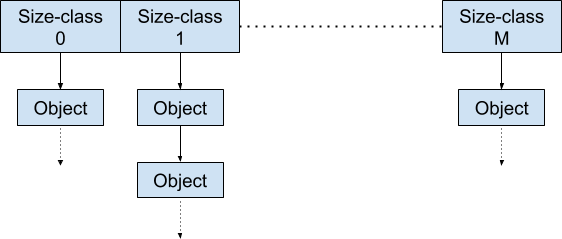
ThreadCache 结构如下:
Threadcache维护的是一个free list链表的集合。不同的class的大小块不一样,分别为8byte、16byte、32byte、48byte...... 这样可以针对不同的size class将其取整分配到对应的free list的链表上,有效避免了内存碎片化。
Middle-end
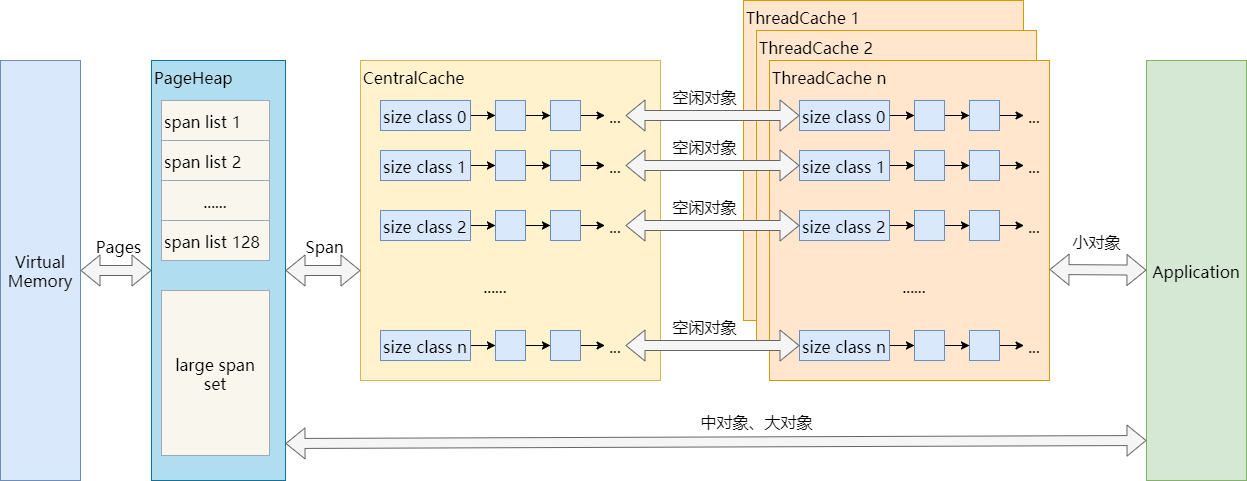
Middle-end有一个承上启下的作用,把不用的内存归还给OS以及提供内存给front-end。主要由两部分构成:Transfer Cache和Central Free List,通常我们把他理解为一个概念即CentralCache。所有的线程都会共享一个CentralCache,所以这里的操作是需要加锁的。
Transfer cache
这个概念比较有意思,是多个Thread公用的cache,当thread1不再使用的内存返回时,如果thread2正在申请相同的内存,这时候Transfer cache会把这部分内存直接给Thread2。如果Transfer cache无法命中才会去CentralFreeList里面查找。
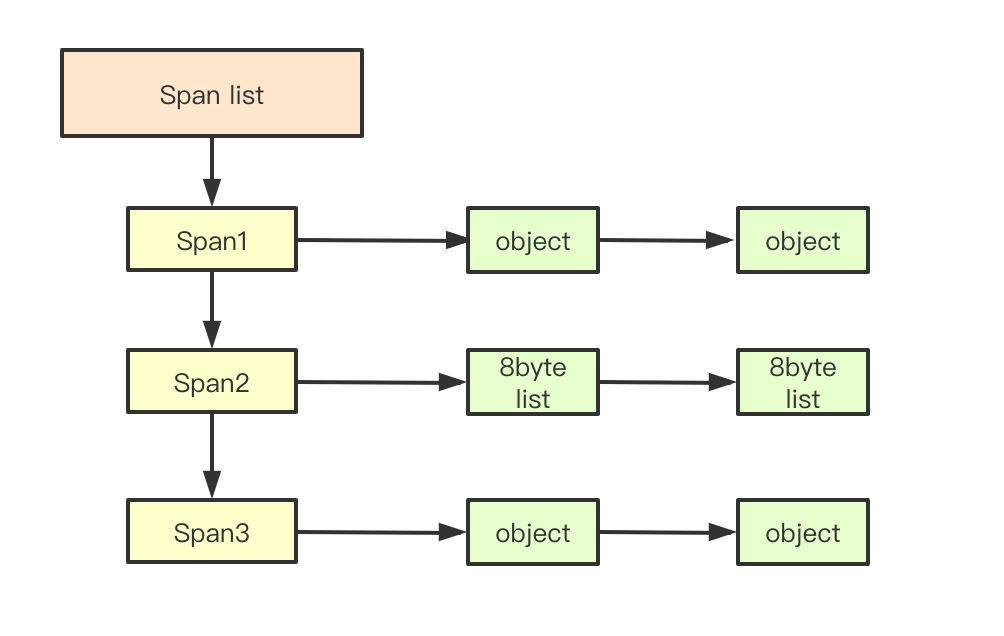
Central Free List
Central Free List 里面管理的是一堆span,span里面映射的就是size class list。span 是由一组连续的page组成的。它可以用来管理大对象,同时也可以将其拆分为多个小对象,当管理的是小对象的时候,span里面记录的就是一系列的size-class。
每个回收回来的object都需要寻找自己所属的span,然后才能挂进freelist
TCMalloc Backend
back-end也可以理解为PageHeap, 它的主要工作有三个:
- 管理大块未使用的内存
- 当Memory不够的时候从OS去拿内存
- 把不需要的内存返回给OS
TCMalloc的backend工作模式有两种
-
Legacy Pageheap管理把Memory划分为对应size的chunk
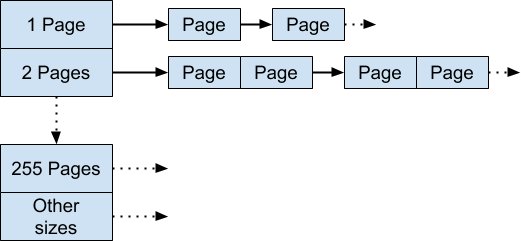
比如一次请求三个page的话,会从3pages里面的free list查找合适的对象。如果当前的free list为空则从下一个free list里面去拿,再拿不到的话则从系统的mmap里面去拿。当内存返回给Pageheap的时候也会根据size插入到对应的free list里面去。图中的Other sizes里面包含的对象是大于255pages的free list。 -
Hugepage Aware Allocator 管理大页面的chunk,可以减少TLB的miss提升相应的性能。
在x86上一页为4KB,超过255pages就是2MB,这个时候就可以认为是huge size, 有三个cache用来实现这部分的功能。- filler cache 这部分里面存放的是小于huge size的cache,当请求的内存小于huge size的时候直接从这里拿,如果拿不到则再从huge page里面拿。
- region cache 处理的是大于 huge size的分配,它支持将跨页面的内存合并打包到一起变成连续的内存块,这对于稍微超过大页面大小的分配(例如2.1 MiB)特别有用。
- huge cache 处理的是至少大于一个huge page的分配,由于region cache是在runtime期间进行分配的,当只有系统认为region cache比较高效才会使用region cache,否则使用huge cache。
Small Object Allocation
通过size得到对应的class,先尝试在Threadcache里面的freelist分配,分配成功就会返回。为空的话再从central cache里面找,找不到再从pageheap申请一个span,拿到span之后将其拆分成N个object。pageheap没有的话则向kernel去申请。
Big Object Allocation
大块内存直接向PageHeap申请对应的的span,没有的话再去向kernel去申请。对于大于256k的内存申请,使用全局内存来分配。全局内存的组织也是单链表数组,数组长度为256,分别对用1 page大小, 2 page大小(1 page=4k)

小结
TCmalloc的整体流程图可以参考这个,总结的很好,可以参考
另外Tcmalloc的内存分配其实是一个懒加载的过程,在向OS申请了内存之后并不会马上使用,而是挂在内存池里,这里也是需要注意下的。