Sound Event Classification for DESED Dataset and Activities of Daily Living Dataset with Deep Learning Models (Conv1D, Conv2D, LSTM) This code is based on YOUTUBE video
There are two datasets used in the project
Domestic Environment Sound Event Detection Dataset is provided by DCASE for evaluating systems for the detection of sound events using weakly labeled data. DESED consists of 10 different classes: alarm_bell_ringing, blender, cat, dishes, dog, electric_shaver_toothbrush, frying, running_water, speech, vacuum_cleaner. You can download DESED from this website.
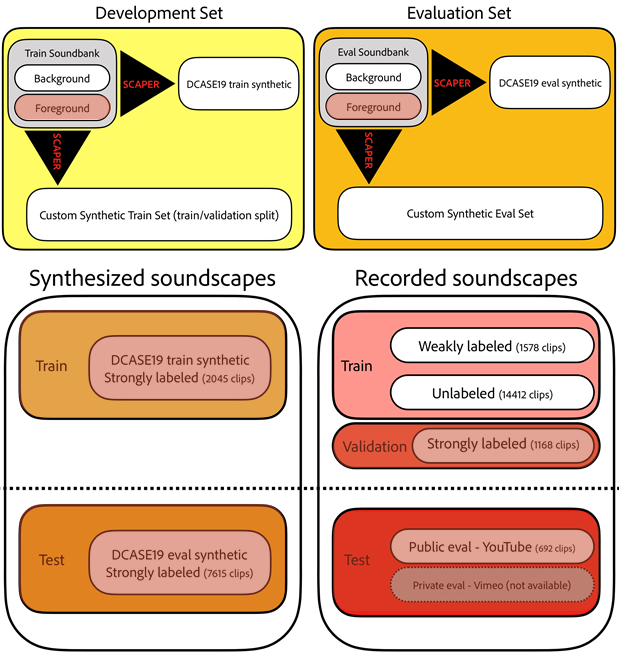
- Soundbank: Foreground and background soundbanks are synthesized and augmented with Scaper to produce synthesized soundscapes
- Synthesized soundscapes: Mixture and foreground and background soundbanks which are strongly labeled
- Recorded soundscapes: Real recorded dataset from Audioset which are unlabeled/weakly labeled/strongly labeled
This project used only strongly labeled data(foreground soundscape, strongly labeled recorded soundscapes) for training.
Thingy:52 is a multi-sensor prototyping platform including microphone which supports BLE.
This project collected sounds generated from activities of daily living in real domestic environment with 3 residents with Thingy:52.
Recorded sounds are annotated with Audacity into 10 different classes: toilet, shower, wash, brush_teeth, dry_hair, cook, eat, wash_dish, watch_tv, vacuum_cleaner.
Each classes contain many sound events for example, toilet class can contain sounds such as toilet flush, fart, and so on. Length of labeled sound data varies from seconds to minutes.
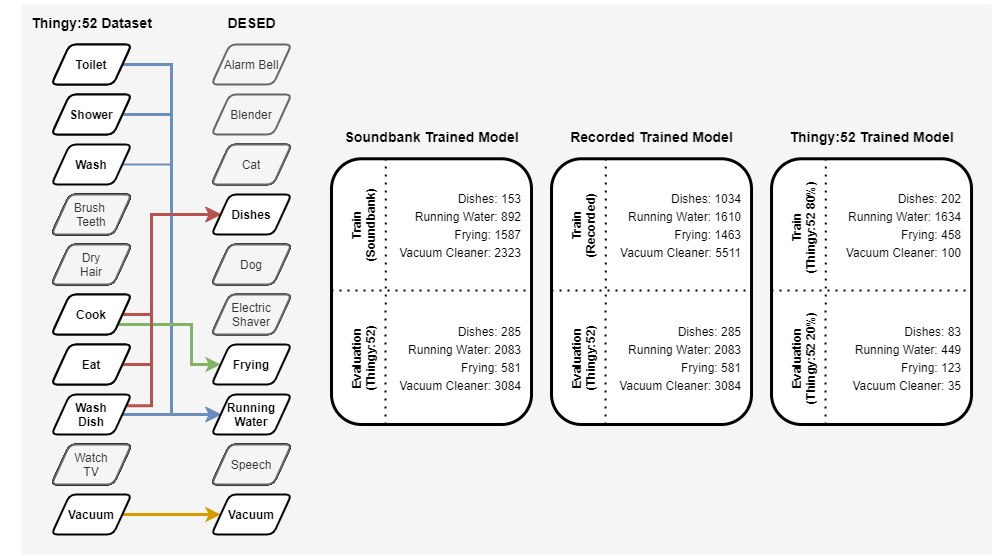
DESED dataset and Thingy:52 dataset are integrated for training to classify four different sound events: dishes, frying, running_water, vacuum_cleaner. Dataset are divided into three groupset for training and integrated Thingy:52 dataset is used for evaluation.
- Soundbank Trained Model: Foreground soundbank is used for training and Thingy:52 recorded dataset is used for evaluation
- Recorded Trained Model: Recorded sounscapes (validation+test) is used for training and Thingy:52 recorded dataset is used for evaluation
- Thingy:52 Trained Model: 80% of Thingy:52 recorded datset is used for training and 20% is used for evaluation
All audio files are downsampled to 16kHz and enveloped with threshold magnitude of 0.003. Files are sliced into 1 second delta time and saved in each class directories into samples.
Models include Conv1D, Conv2D, and LSTM. 128 log mel-banks are extracted with 25ms window frame and a stride of 10ms.
Models are selected and trained with training samples. Trained models are saved in models directory.
Accuracy and loss histories are saved in logs directory.
Predictions are made with evaluation samples and saved in logs directory as numpy array.
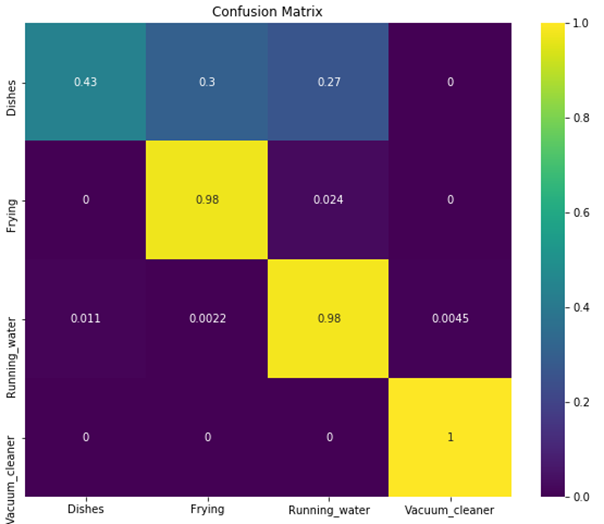
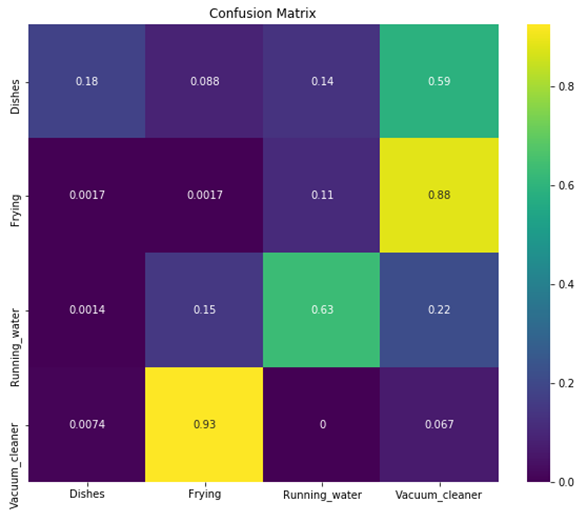
Prediction logs are used for confusion matrix.
- Conv1D
- Conv2D
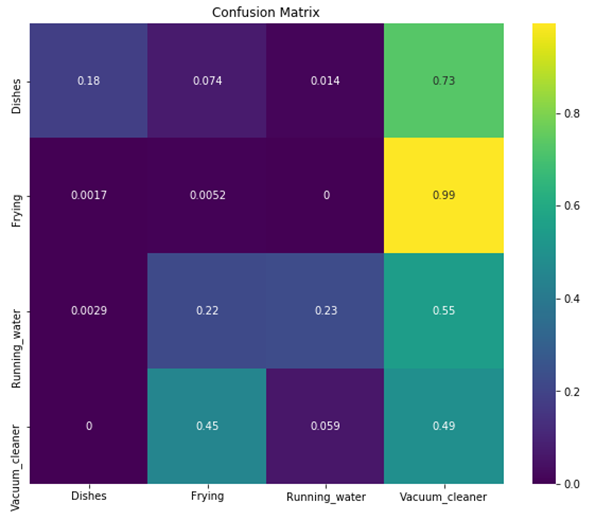
- LSTM

- Conv1D
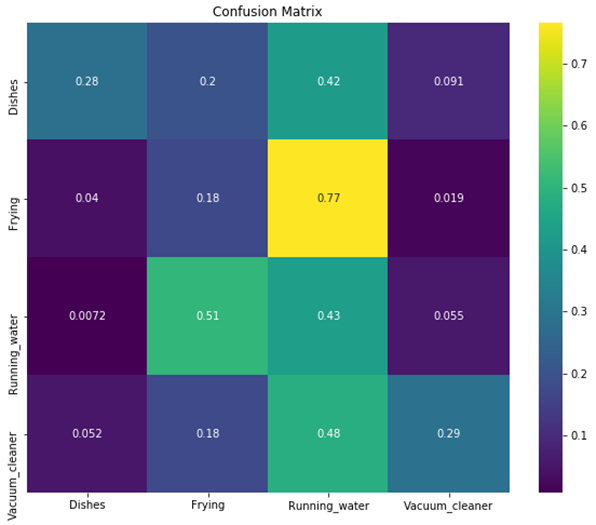
- Conv2D
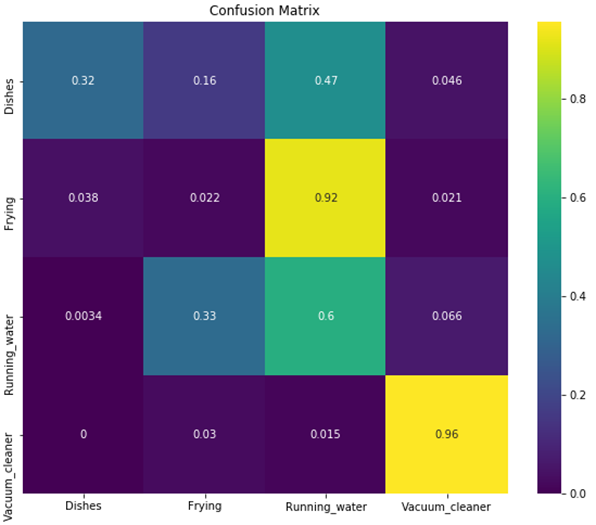
- LSTM
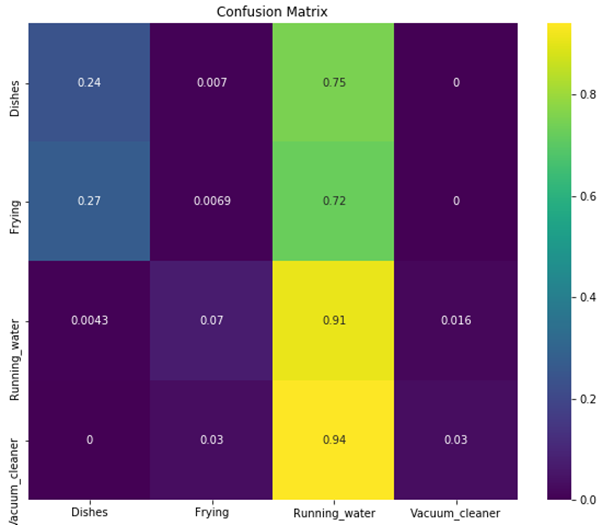
- Conv1D
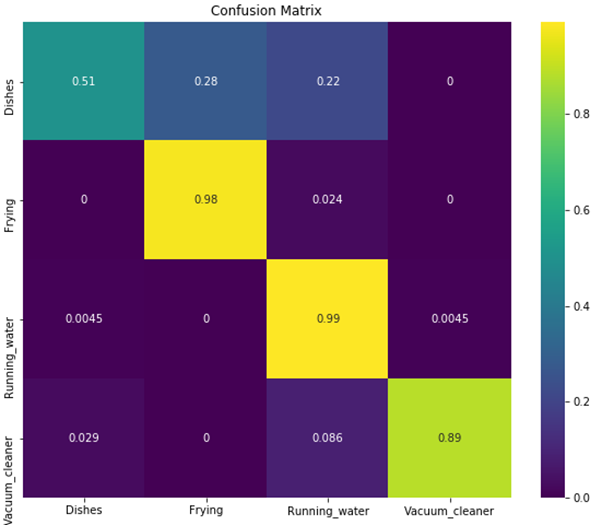
- Conv2D
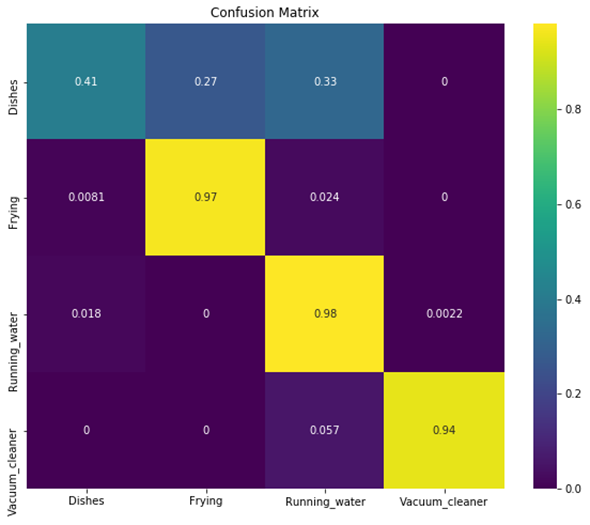
- LSTM