buffer improvement with piece tree#41172
Merged
Conversation
Member
|
@rebornix I wonder if all the initial loading speed advantage is due to the memory optimization (avoiding sliced strings) that I pushed a while ago. How does it look when setting |
Member
Author
|
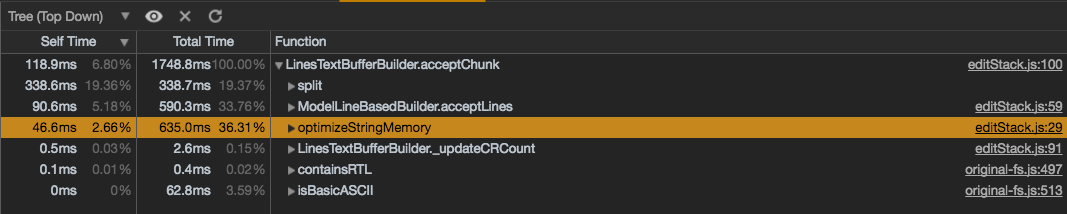
@alexandrudima you are right, memory optimization is the major thing that makes the line buffer slow in file opening.
Disable Line Buffer PT They are close so from performance perspective, current implementation is good. The cost goes to memory. |


…ill revert later." This reverts commit 96e79f7.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to subscribe to this conversation on GitHub.
Already have an account?
Sign in.
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
This is an early version of adopting piece table with red black tree as new text buffer. It still contains quite a few hacks (model builder, textsource) and
applyEditsis not returning good info and leads to whole page re-tokenization, but we can still get an idea of how a chunk based, tree structure buffer works in vscode.Under the hood it's a piece table, which has two string buffers to hold the original content and newly added content. Instead of using a doubly-linked list to store the pieces, here I use a red black tree in order to get a good average time complexity of most operations.
In addition to basic red black tree node properties, each node has
I didn't use a piece's offset in the document as key because that would lead to an inorder traversal of a lot nodes when inserting/deleting. The latter two properties above can help us find the position to insert/delete a node, and make sure after each operation, we only need to do some updates from the modified node to tree root, at most.
Todo:
Right now the bottleneck of this implementation is CRLF. As we don't do splits by
/\r\n|\r|\n/and the system is heavily relying on line break counts, we need to do some validation for each operation as it may split CRLF to CR and LF. When the changed_buffer size is large, this validation is costly.Recording of some crazy file (large.c is 50MB, 1.4MM lines; Heap-xyz is 50MB, 3.3MM lines)
Left: Piece Table, Right: Insider