SummerOfCodeIdeas

Google Summer of Code 2022 - Program Page
These are a list of ideas compiled by mlpack developers; they range from simpler code maintenance tasks to difficult machine learning algorithm implementation, which means that there are suitable ideas for a wide range of student abilities and interests. The "necessary knowledge" sections can often be replaced with "willing to learn" for the easier projects, and for some of the more difficult problems, a full understanding of the description statement and some coding knowledge is sufficient.
In addition, these are not all of the possible projects which could be undertaken; new, interesting ideas are also suitable.
A list of projects from 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020 and 2021 that aren't really applicable to this year, can be found here.
For more information on any of these projects, visit #mlpack in libera.chat (IRC), #mlpack:matrix.org on Matrix, mlpack/mlpack on Gitter, mlpack.slack.com on Slack or email mlpack@lists.mlpack.org (see also http://knife.lugatgt.org/cgi-bin/mailman/listinfo/mlpack). It is probably worth consulting the mailing list archives first; many of these projects have been discussed extensively in previous years. Also, it is probably not a great idea to contact mentors directly (this is why their emails are not given here); a public discussion on the mailing list is preferred if you need help or more information. Please also do not expect the mentors to respond to individual emails for this very reason.
If you are looking for how to get started with mlpack, see the GSoC page, the community page, and the tutorials and try to compile and run simple mlpack programs. Then, you could look at the list of issues on Github and maybe you can find an easy and interesting bug to solve.
For an application template, see the Application Guide.
- Example Zoo
- Example Zoo, Embedded Edition
- Enhance CMA-ES
- Reinforcement learning
- Algorithm optimization
- Automatic bindings to new languages
- Profiling for parallelization
- Build System (CMake) Modernization
- Visualization Tool
- Better layer stacking for ANN
- Improvisation and Implementation of ANN Modules
- Multi-objective Optimization
- Ready to use Models in mlpack
- XGBoost implementation in mlpack
Over the course of the last years, various machine-learning algorithms have been implemented as a part of mlpack. This project will focus on applying some of the algorithms to interesting datasets to see how they fare. This will allow us to show (off!) the potential usage of mlpack through various real-world domains. But like string theory, there are extra dimensions to this project.
- 1 - When I am new to any library, I learn a great deal about the API seeing and running example code rather than documentation.
- 2 - A project such as these would establish certain robustness. We will be able to provide sample learning curves and code snippets through blogs.
- 3 - Cool graphs will keep the summer enjoyable. Samples such as pictures, sounds, Shakespeare English, or playing games with the RL framework, everything is welcome here.

The project should directly tie in the examples infrastructure we already use, which is a mixture of Jupyter notebooks (C++, Python, Go, R, Julia) and separate executables (C++).
deliverables: new examples in the examples repository, but the details are up to the proposer
difficulty: mlpack-complete, at least as "hard" as any other GSoC project. Just kidding... The difficulty will depend on the algorithms selected for implementation.
necessary knowledge: Familiarity with the several machine-learning algorithms implemented in mlpack and analyzing results with plotting tools. Being able to hack around mlpack.
potential mentor(s): Marcus Edel
project size: medium (~175 hours) and large project (~350 hours)
description: in the last year we have been working on adding support for
embedded platforms. Currently, the pull request
is close to being merged. This pull request provides support for aarch64 and arm32 architectures.
However, it would be nice to have a set of examples and documentation
to explain for the users and mlpack community how to use these new features.
Personally, I like vintage computing and embedded systems, and happy to optimize
any software and eliminate any non-necessary features. It could be really cool
to see mlpack running on resource-constrained devices by only executing make.
This project builds on the last year project, and extend it to make it simple to users by adding examples in the mlpack's Examples zoo repository created last year which is still new and have a modest set of examples. However running knn, svm, kmeans and an already trained ANN models on resources constrained devices can be a different thing.
To allow the user to use mlpack methods on embedded systems, the written examples need to be lightweight and have a very low impact on memory and storage. In order to have an idea of what the project might look like here are some ideas:
- Try to see if a Makefile for cross-compiler can generate arm binaries.
- Prepare a list of machine learning methods that are suitable for resource-constrained devices
deliverables: A set of examples of using mlpack methods that can run on any aarch64 and arm32 devices such as RaspberryPI (0, 1, 2, 3, 4), Beagleboard and any arm based SoC chip.
difficulties 5/10 The project is simple, but be prepared this project might requires a lot of refactoring, testing and documentation, and writing a lot of mlpack examples.
relevant tickets: #2531
necessary knowledge: A good knowledge of C++ and cross-compiling toolchains are required, being familiar with mlpack codebase is necessary. In addition, good knowledge of machine learning and is a plus.
recommendations for preparing an application: The project will need to have a a good proposal that shows you listed interesting machine learning methods to run on embedded systems, and how you are going to minimize the memory and storage footprint without reducing functionalities for the users, you need also to show that you have a plan for making it easy to user to cross-compile on embedded systems.
potential mentor(s): Omar Shrit
project size: medium (~175 hours) and large project (~350 hours)
The Covariance Matrix Adaptation Evolution Strategy (CMA-ES) is an evolutionary strategy that adapts the covariance matrix of a normal search distribution. Compared to many other evolutionary algorithms, an important property of the CMA-ES is its invariance against linear transformations of the search space.

CMA-ES is one of the most robust algorithms for real-world problems. In recent years, several methods have been developed to increase the performance of the CMA-ES e.g:
- saACM-ES: Self-adaptive surrogate-assisted covariance matrix adaptation evolution strategy
- IPOP-CMA-ES: A Restart CMA Evolution Strategy with increasing population size
- Active-CMA-ES: Improving Evolution Strategies throughActive Covariance Matrix Adaptation
This project entails the investigation of methods to improve the original CMA-ES method and the implementation of these methods in a flexible manner.
difficulty: 8/10
deliverable: working CMA-ES based optimizer
necessary knowledge: basic data science concepts, good familiarity with C++ and template metaprogramming, familiarity with mlpack/ensmallen API
relevant ticket(s): #70 recommendations for preparing an application:: This project can't really be designed on-the-fly, so a good proposal will have already gone through the existing optimization codebase and identified what parts of the API will need to change (if any), what the API for the optimization methods should look like
potential mentor(s): Marcus Edel
project size: medium (~175 hours) and large project (~350 hours)
Back in 2015 DeepMind published their landmark Nature article on training deep neural networks to learn to play Atari games using raw pixels and a score function as inputs. Since then there has been a surge of interest in the capabilities of reinforcement learning using deep neural network policy networks, and honestly who didn't always want to play around with RL on their own domain-specific automation tasks. This project revitalizes this desire and combines it with recent developments in reinforcement learning to train neural networks to play some of the unforgettable games. In more detail, this project involves implementing different reinforcement methods over the course of the summer. A good project will select one or two algorithms and implement them (with tests and documentation. Note while in principle, the implementation of an agent that can play one of the Atari games is quite simple, this project concentrates more on the recent ideas, e.g:
-
Accelerated Methods for Deep Reinforcement Learning: Accelerated Methods for Deep Reinforcement Learning Investigate how to optimize existing deep RL algorithms for modern computers, specifically for a combination of CPUs and GPUs.
-
Actor Critic using Kronecker-Factored Trust Region: ACKTR uses an approximation to compute the natural gradient update, and apply the natural gradient update to both the actor and the critic.
-
Rainbow: Combining Improvements in Deep Reinforcement Learning: Rainbow: Combining Improvements in Deep Reinforcement Learning examines six extensions to the standard DQN algorithm (Double Q-learning, Prioritized replay, Dueling networks, Multi-step learning, Distributional RL, Noisy).
-
Proximal Policy Optimization Algorithms: The PPO method was released by OpenAI in 2017, and it made a splash by it's state of the art performance while being much easier to implement.
-
Persistent Advantage Learning DQN: In Google’s DeepMind group presented a novel RL exploration bonus based on an adaptation of count-based exploration for high-dimensional spaces. One of the main benefits is that the agent is able to recognize and adjust its behaviors efficiently to salient events.
The algorithms must be implemented according to mlpack's neural network interface and the existing reinforcement learning structure so that they work interchangeably. In addition, this project could possibly contain a research component -- benchmarking runtimes of different algorithms with other existing implementations.

A Beginner's Guide to Deep Reinforcement Learning
Note: We already have written code to communicate with the OpenAI Gym toolkit. You can find the code here: https://github.com/zoq/gym_tcp_api
difficulty: 7/10
deliverable: Implemented algorithms and proof (via tests) that the algorithms work with the mlpack's codebase.
necessary knowledge: a working knowledge of neural networks and reinforcement learning, willingness to dive into some literature on the topic, basic C++
recommendations for preparing an application: To be able to work on this you should be familiar with the source code of mlpack, especially: src/mlpack/methods/reinforcement_learning/. We suggest that everyone who likes to apply for this idea, compile and explore the source code including the tests: src/mlpack/tests/. If you have more time, try to review the documents linked below, and in your application provide comments/questions/ideas/tradeoffs/considerations based on your brainstorming.
relevant tickets: none are open at this time
references: Reinforcement learning reading list, Deep learning bibliography, Playing Atari with deep reinforcement learning
potential mentor(s): Manish Kumar, Marcus Edel
project size: medium (~175 hours) and large project (~350 hours)
mlpack is renowned for having high-quality, fast implementations of machine learning algorithms. To this end, since 2013, we have maintained a benchmarking system that is able to help us show mlpack's efficient implementations. However, it is always possible to make these implementations a bit faster. Below is some example output from a recent run of the benchmarking system on some logistic regression problems.
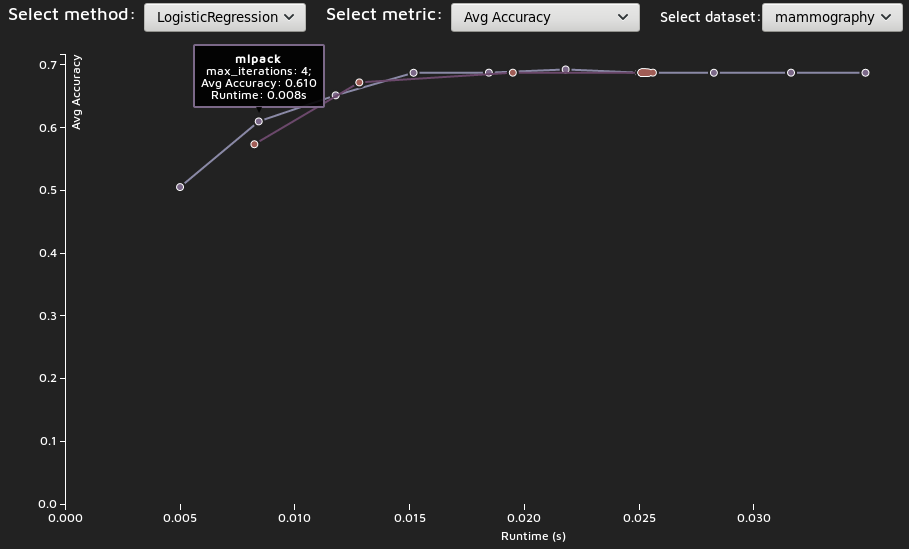
Your goal in this project would be to choose a machine learning algorithm that you are interested in and knowledgeable about, then set up a series of datasets and configurations that allows you to provide a nice benchmarking view like the one above, and iteratively improve the mlpack implementation, hopefully until it is the fastest. This could involve high-level optimizations like simply avoiding unnecessary calculations or changing default parameters when needed, or lower-level optimizations like checking that SIMD autovectorization is happening and avoiding small memory allocations and copies, and even algorithm-level optimizations like clever approximations. Almost certainly any successful project here will involve a lot of time with a profiler.
The finished product should be mergable code, but more importantly, the benchmarking output, which can allow users to quickly see and understand that mlpack's implementation is good.
difficulty: 3/10-10/10, depending on the algorithm chosen and the level of interest
deliverable: improved implementation and benchmarking configuration providing a relevant and clear comparison of mlpack to other implementations
necessary knowledge: good knowledge of C++ and Armadillo, knowledge of how to use a profiler, in-depth knowledge of the algorithm to be optimized, strong familiarity with the existing implementation of the algorithm to be optimized
recommendations for preparing an application: You should definitely be familiar with the source code of the algorithm you are interested in working with, and it would not be a bad idea to do some preliminary benchmarking and possibly submit a simple pull request with an improvement (if there is low-hanging fruit that could be easily optimized). When we evaluate these applications it will be important to see a clear plan for progress, so that we can avoid the project "getting stuck".
potential mentor(s): Ryan Curtin, Shikhar Jaiswal, Sangyeon Kim, Saksham Bansal
project size: medium (~175 hours) and large project (~350 hours)
As of last year, mlpack now has an automatic bindings system documented here. So far, bindings exist for Python, command-line programs, Markdown documentation, and PRs are in progress for Go and Julia; it would be really useful to add bindings for even more languages.

A couple of ideas for languages are given above---MATLAB, Octave, Java, Scala. But these are certainly not the only language for which bindings could (and should) be provided.
For this project, once you select your target language, you will have to design a handful of components:
-
The build system workflow and CMake infrastructure so that the bindings are properly built. i.e., for the command-line bindings, this is a single-step compilation, but for Python, this involves generating a Cython .pyx file, generating a setuptools setup.py file, then compiling the Cython bindings.
-
Handling and conversion of the different types from the input language. It's extremely important that matrices aren't copied during this step, so it is important to think this through beforehand as that may guide the design of the bindings in other ways.
-
Generation of the code for the target language from the PARAM_*() macros and PROGRAM_INFO() macros.
Any design process should certainly start by looking at the existing bindings, and thinking about how to make a proof-of-concept to the new language. It's important to use the existing automatic bindings system so that the bindings we do provide in the files like logistic_regression_main.cpp and others can work for all languages. So, unfortunately, hand-written bindings for each language will not suffice here, since they are difficult to maintain and keep in sync.
difficulty: 6/10
deliverable: working and tested binding generator to the target language, plus some simple examples of how they can be used for user documentation
necessary knowledge: strong knowledge of the details of the target language is necessary, as well as familiarity with the existing automatic bindings system
recommendations for preparing an algorithm: Start with the basics; think about how you would hand-write an efficient binding to the target language, and perhaps prepare a simple proof-of-concept for binding with the same functionality as of the simple programs like src/mlpack/methods/pca_main.cpp. Then, think about how you would automatically generate that hand-written binding from the sources in pca_main.cpp, and this will guide the design that you will use for the automatic binding generator to your target language. In your application, be sure to include a reasonable level of detail about the implementation; specifically, how the overall generator will work, how unnecessary copies will be avoided, how users will interact with the bindings, and so forth.
references: automatic bindings documentation
potential mentor(s): Ryan Curtin
project size: large project (~350 hours)
mlpack is used and developed in a wide variety of contexts. As a result of this, the CMake configuration files have to support different operating systems, compilers, and library paths. While the current solution works sufficiently, users with even slightly nonstandard setups often have a difficult time building mlpack from the source. In addition, some suboptimal compromises have been made, such as preventing the system to search for boost-cmake. Luckily, CMake has seen some new features in 3.0.0 and forward which can be used to fundamentally restructure the build process to be clearer and more portable. Note that the mlpack build process is reasonably complex and includes multiple other language bindings.
difficulty: 4/10
deliverable: working CMakeList files matching modern conventions
necessary knowledge: build system tools such as cmake and makefiles. Some resources for "modern" CMake can be found here, here, and here
relevant tickets: #2113, #2215
potential mentor(s): Ryan Birmingham
recommendations for preparing an application: It may be a good idea to prepare or adopt a simple project or proof of concept which uses "modern" CMake, to demonstrate an understanding of the requirements of this project.
project size: medium (~175 hours)
Various machine learning algorithms are implemented in C++ using mlpack. Thus, users should also be to visualize various metrics and data generated by these models. There are visualization libraries like OpenCV which helps in visualizing the model in C++, but in order to do so, the user is required to know the nitty-gritty of those libraries as well which is not feasible for time-constrained projects. So to improve visualizing mlpack models, there is a need for a visualization tool that will log various model metrics and would help in visualizing the training of models. There are various solutions to provide this feature. One solution is to develop the tool from scratch. Another idea would be to write code to integrate with the existing visualization tool like TensorBoard.
Note: As integrating with existing tools leads to limitations in features and also adds a dependency, a tool of our own would be the solution for the problem.
difficulty: 5/10
deliverable: working visualization tool/code that helps visualize different metrics of mlpack models (e.g loss, images, etc.) on TensorBoard.
necessary knowledge: Knowledge of event writing and projecting values using graphs.
relevant tickets: None
potential mentor(s): Ryan Birmingham
recommendations for preparing an application: It may be a good idea to prepare or adopt a simple project or proof of concept which helps in visualizing machine learning models, to demonstrate an understanding of the requirements of this project.
project size: medium (~175 hours) and large project (~350 hours)
Right now the basic solution to stacking Artificial Neural network(ANN) layers is to use a vector and stack layers in that, which works fine for basic networks but gets complicated if someone wants to design a more complex model which requires them to stack layer arbitrarily and connect the input and output of a single layer to multiple different layers.
We have been thinking of a DAG class that would aim to eliminate this constraint. A good way to go for this project would be by developing some simple DAG-structured networks as tests, and then implementing the code in a test-driven way: first implement the tests, then implement the basic DAG class so that the easiest test works, then generalize it to the more complicate classes.
deliverables: Working DAG class for ANN
difficulties: 7/10, That's obviously a number which I could think on top of my head knowing things that would go in but given the time it shouldn't be a hard project but could be one that requires a lot of testing and going back to the code to make sure it works.
relevant tickets: #2777
necessary knowledge: Knowledge of DAGs and their implementation and a good understanding of the ANN code base in mlpack.
potential mentor(s): Aakash Kaushik
project size: medium (~175 hours) and large project (~350 hours)
mlpack has a great ANN module but when compared to Tensorflow or Pytorch it still lags behind in terms of features and flexibility. Hence it would be great if the missing features can be hunted down and implemented/fixed. It often happens that when we need a specific feature, we open an issue, get that particular feature implemented and move on. In this context, a feature can be an extra parameter in one of the layers (for eg: padding support in maxpool layers) or implementation of a new layer, activation function, etc. from scratch. Research papers keep coming up and often there are improvements over existing layers. Another thing that comes to mind is the absence of accessor functions for some layers which can be fixed. There are quite some shortcomings that I cannot recall but they keep cropping up while using the library. The applicant is expected to be thorough with the ANN module structure of both libraries, i.e., mlpack and Pytorch (or anything else that you might use for reference) and also be comfortable with the basic maths behind the layers/functions he/she would be modifying or implementing from scratch. In addition to this, there are a number of open issues related to the ANN module which can be solved as part of this project. The entire project is to be done in such a way that all changes are backward compatible, i.e., previously written code shall still run without any issue.
difficulty: 6/10 (depends more on what exactly you are seeking to change)
deliverable: A reformed and more robust ANN module
necessary knowledge: Thorough knowledge of how mlpack layers are implemented, sufficient experience with Pytorch (or any other standard framework) and fundamental clarity about forward propagation, backward propagation and gradient mathematics. Extensive experimentation/work with mlpack will help you to build a strong proposal.
relevant tickets: Any open issue related to the ANN module.
potential mentor(s): Sreenik Seal
recommendations for preparing an application: This project is scalable to a certain degree, that is, by implementing only a couple of layers properly, one should be comfortable enough to work with the remaining layers. That being said, the application should also describe a solid design approach with respect to the reformed ANN codebase and explicitly mention the changes to be brought about in detail. To be kept in mind is also the fact that writing tests is as vital as the implementation of the feature itself. The proposal should also highlight how you are going to use the entire three months of coding period efficiently. This idea is open to some extent, i.e., the applicant has certain liberty in choosing the direction of the project. However, it is advisable to discuss your approach in the IRC before writing the proposal. Best of luck!
project size: medium (~175 hours) and large project (~350 hours)
ensmallen, a header-only library for numerical optimization, recently added support for multi-objective optimization with the addition of the NSGA2 optimizer. This project would involve adding more multi-objective optimization algorithms to ensmallen. Optimizers to be implemented can include Directed Search Domain, Successive Pareto Optimization, PGEN etc.
deliverable: Working multi-objective optimizer(s).
difficulty: 2/10-6/10, depending on the algorithm chosen and the level of interest.
necessary knowledge: familiarity with C++ and template metaprogramming, machine learning methods, multi-objective optimization and ensmallen APIs is helpful.
relevant tickets: mlpack/ensmallen#149, mlpack/ensmallen#176
potential mentor(s): Sayan Goswami
project size: medium (~175 hours) and large project (~350 hours)
The aim of models repository is to showcase the power of mlpack, with pre-trained, ready to use models written in mlpack. To the same effect, the goals of the project are listed below :

-
Adding ready to use state of the art deep learning models : Models repo currently has DarkNet(tiny, 19 and 53) and YOLOv1. Last year there were also attempts to add YOLOv3 and Bert models as well. Following the same trend, it would be nice to see various object classification / detection / segmentation. Since training these models without GPU might be cumbersome, we will depend on the weight conversion between mlpack and PyTorch (or any other framework). Refer to the PyTorch-mlpack Weight Converter. For more details refer to this models wiki-page.
-
Showcasing usage of models repo in examples repo : Demonstrate the usage of models repo API in examples repo, to show how easy it is to use pre-trained models in mlpack.
-
Building on the existing dataloader : models repo provides an awesome dataloader that allows you read image / object detection datasets. It would be really nice to see support for other types as well. For more details refer to this dataloaders wiki-page.
-
Adding support for more standard datasets : Currently, the dataloader allows user to download and load datasets like Pascal VOC in single line. This can be extended to other datasets as well. For more details on supported datasets refer to the supported datasets section.
-
Building on Augmentation class : The Augmentation class allows users to manipulate / augment their dataset. Currently it supports only resize feature for images. This provides room to add new augmentations.
-
Showcase usage of augmentation class in examples repo : Demonstrate the usage of augmentation class in examples repo, to show how easy it is to augment datasets in a single line.
-
Adding visualisation tools for computer vision models : Add functions like
PlotBoundingBoxesthat take in an image and coordinates of a bounding box and displays an image with bounding boxes. -
Adding CLI for features in models repo
Note : A potential student doesn't need to implement everything listed above. The goals chosen will vary with difficulty of model / algorithm chosen to implement.
deliverable: State of the art pre-trained model. Support for standard datasets. Improved Data-loaders. More augmentation tools.
difficulty: Difficulty will depend on the algorithms selected for implementation.
necessary knowledge: Familiarity with general NN algorithms and analyzing results with plotting tools. Being able to hack around mlpack ANN and RL codebase.
relevant tickets: None so far
potential mentor(s): Kartik Dutt
recommendations for preparing an application : The application should ideally have some pseudo-code explaining the API of the new model / dataset / dataloader and how it would help the organization (i.e. usage of the model / dataset). It should also mention timeline and targets for each phase. This idea can be stretched to very complex algorithms ergo the applicant has certain liberty in choosing the direction of the project. It is advisable to discuss your algorithms / datasets in the mailing list before writing the proposal. Looking forward to working with you!
project size: medium (~175 hours) and large project (~350 hours)
Tree ensembles have regularly been shown to be among the best-performing machine learning models out there; they regularly win Kaggle competitions. Last year, the support was laid to implement the XGBoost algorithm inside of mlpack (#3011, #3014, #3025, #3022 and others), but a ready-to-use implementation is not yet available.
The goal of this project is to pick up where we left off last year, and finish the XGBoost implementation inside of mlpack. Given that the basic algorithm is mostly ready, there will be a lot of time during the summer to tune, profile, and improve the implementation such that it is competitive with---or better than!---the reference implementation.
The specific deliverables and goals of the project are up to the student, but here are a few ideas of things that could be included:
- A user-facing binding for XGBoost, like the
random_forestanddecision_treebindings insrc/mlpack/methods/random_forest_main.cppandsrc/mlpack/methods/decision_tree_main.cpp, respectively. - Comparisons with the reference implementation of XGBoost to ensure correctness of our implementation.
- Benchmarks against the reference implementation of XGBoost to identify places where our implementation is competitive with or better than the reference implementation.
- Deep investigation and profiling of core inner loops in decision tree training, along with associated optimizations and improvements to the code. (That may apply not just to the XGBoost implementation but also to our decision tree and random forest implementation.)
- Parallelization of the XGBoost, decision tree, and random forest implementations with OpenMP.
deliverable: completed XGBoost algorithm implementation, or other improvements to mlpack's tree ensemble implementations
difficulty: between 4/10 to 6/10
necessary knowledge: a deep understanding of decision trees, random forests, or gradient boosting algorithms. Definitely familiarity with algorithms like XGBoost will be needed.
potential mentor(s): Germán Lancioni, Ryan Curtin, TBD
project size: medium (~175 hours) and large project (~350 hours)