Awesome package! Thanks for all the work, @mayer79. Great to see such a solid implementation of H statistics in R. Well documented and compatibile with many modelling packages.
Would it be feasible to add out-of-the-box support for H2O models? Due to the way how you've set up the code, it's already possible now to use the pred_fun argument for H2O models in the various functions. See the code example down below, where I illustrate this for binomial, regression and multinomial H2O models.
I believe overwriting the generics for hstats(), partial_dep(), ice(), and perm_importance() would require two main things:
- Changing the
pred_funargument to:
# Class "H2OBinomialModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[[3]]
}
# Class "H2ORegressionModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[[1]]
}
# Class "H2OMulticlassModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[, -1]
}
- Ensuring the provided data argument (potentially an H2OFrame) gets converted to a data.frame using
as.data.frame()
Further suggestions / potential improvements:
- Would it be possible/better to set up a generic for the
pred_fun itself? Then you'd only have to overwrite that one for ranger, Learner, explainer, H2OBinomialModel, H2ORegressionModel, and H2OMulticlassModel classes instead of all of hstats(), partial_dep(), ice(), and perm_importance().
- The prediction function for H2O models requires converting the data to an H2OFrame using
as.h2o() and then calling h2o.predict(). Doing this only once is much faster than calling pred_fun multiple times. Hence, particularly for H2O models, further speed improvements are possible by first combining the data and then calling pred_fun instead of the other way around. [Try running the below examples using h2o.show_progress() to see a progress bar whenever as.h2o() and h2o.predict() get called]
partial_dep(..., BY = ...) could be faster by avoiding the for loop over the BY argument.hstats() could be faster by avoiding the for loop over the one-way, two-way and three-way effects. [This would be hard to refactor though]perm_importance() could be faster by avoiding the for loop over the v argument. [This might lead to memory issues though when stacking too many data frames when v, m_rep and/or n_max is large, so potentially having an optional argument for this would be better]
- For H2O models, the default argument when
v = NULL in hstats() and perm_importance() could be set to object@allparameters$x. That way no unnecessary computations are performed for columns in X not used as features.
- For H2O models, the default argument for
y in perm_importance() can be set to object@allparameters$y.
Code example for H2O models:
library(hstats)
library(h2o)
h2o.init()
h2o.no_progress()
# H2O Binomial ----
# Import the prostate dataset into H2O:
prostate <- h2o.importFile("http://s3.amazonaws.com/h2o-public-test-data/smalldata/prostate/prostate.csv")
prostate_df <- as.data.frame(prostate)
# Set the predictors and response; set the factors:
prostate$CAPSULE <- as.factor(prostate$CAPSULE)
prostate$RACE <- as.factor(prostate$RACE)
prostate$DPROS <- as.factor(prostate$DPROS)
prostate$DCAPS <- as.factor(prostate$DCAPS)
prostate$GLEASON <- as.factor(prostate$GLEASON)
predictors <- c("AGE", "RACE", "DPROS", "DCAPS", "PSA", "VOL", "GLEASON")
response <- "CAPSULE"
# Build and train the model:
pros_gbm <- h2o.gbm(x = predictors,
y = response,
nfolds = 5,
seed = 1111,
keep_cross_validation_predictions = TRUE,
training_frame = prostate)
# Class "H2OBinomialModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[[3]]
}
# H stats
s <- hstats(pros_gbm, X = prostate_df, pred_fun = pred_fun)
s
#> 'hstats' object. Use plot() or summary() for details.
#>
#> H^2 (normalized)
#> [1] 0.2818805
# H statistics: overall level of interaction & pairwise
plot(s)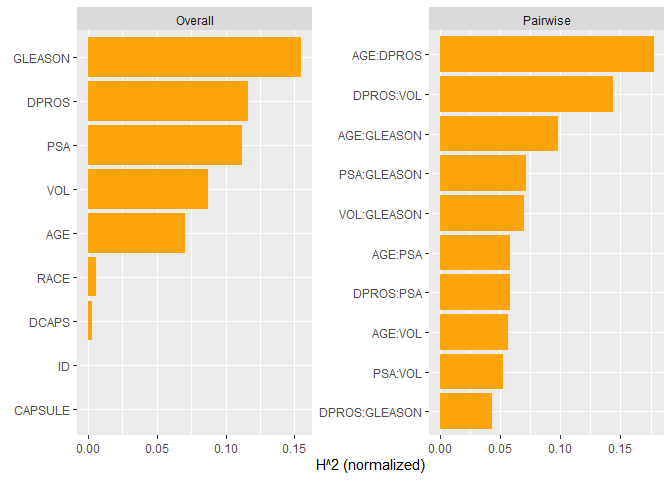
# Unnormalized pairwise statistics
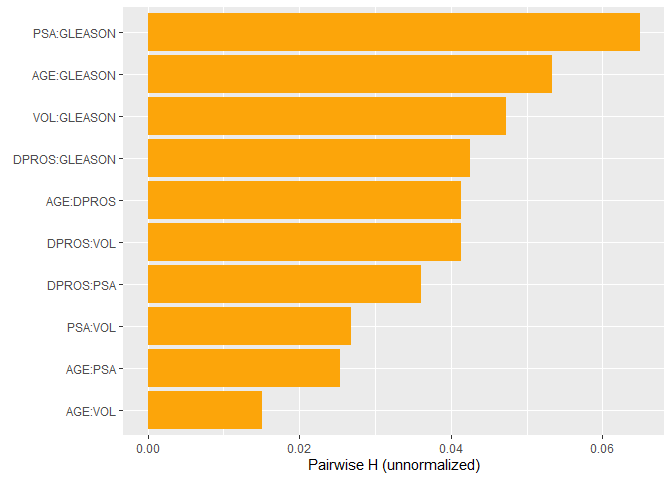
plot(h2_pairwise(s, normalize = FALSE, squared = FALSE))
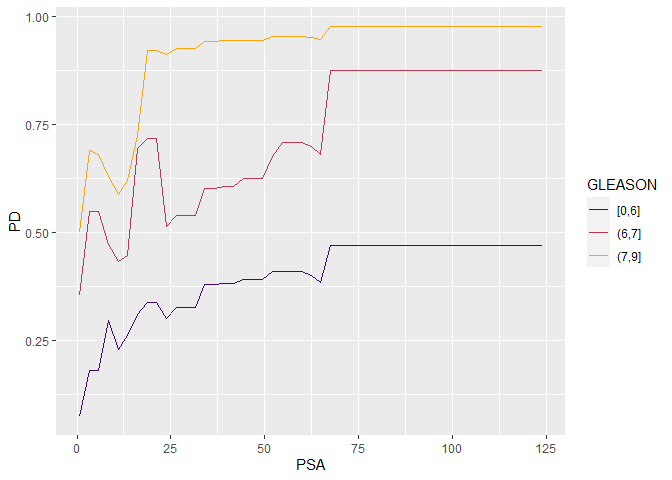
# Stratified PD
plot(partial_dep(pros_gbm, v = "PSA", X = prostate_df, BY = "GLEASON", pred_fun = pred_fun), show_points = FALSE)
# Two-dimensional PDP
pd <- partial_dep(pros_gbm, v = c("PSA", "GLEASON"), X = prostate_df, pred_fun = pred_fun, grid_size = 1000)
plot(pd)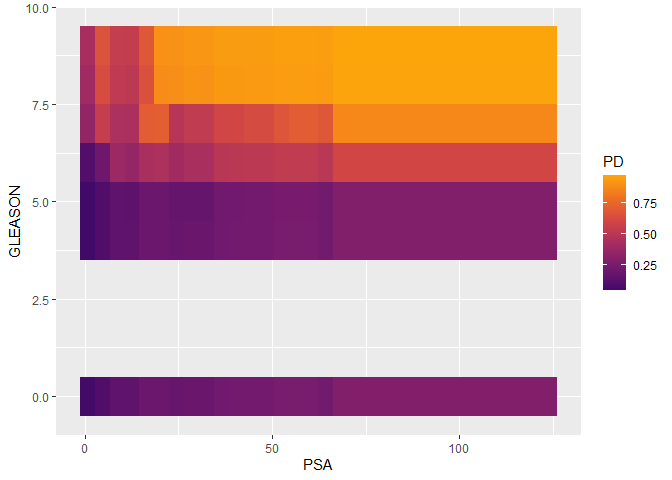
# Centered ICE plot with colors
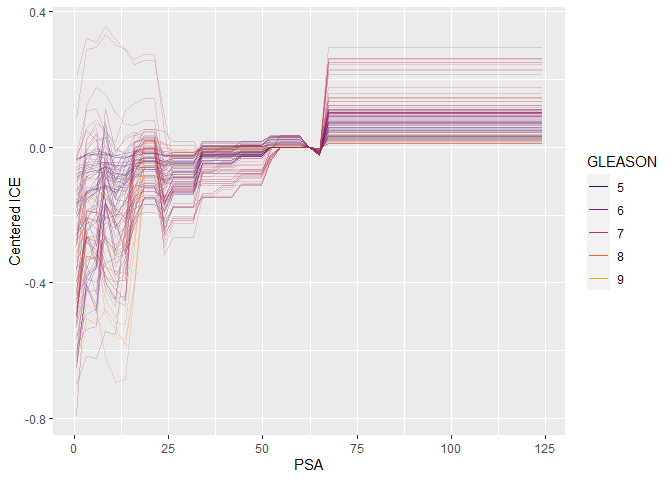
ic <- ice(pros_gbm, v = "PSA", X = prostate_df, BY = "GLEASON", pred_fun = pred_fun)
plot(ic, center = TRUE)
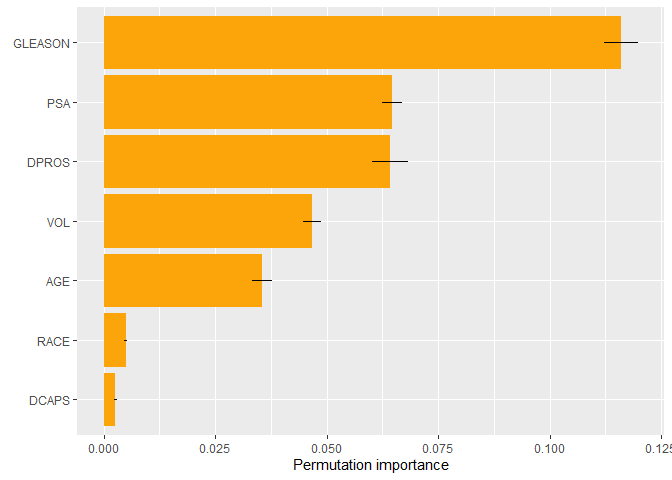
# Variable importance based on permutation
plot(perm_importance(pros_gbm, X = prostate_df, y = pros_gbm@allparameters$y, pred_fun = pred_fun, v = pros_gbm@allparameters$x))
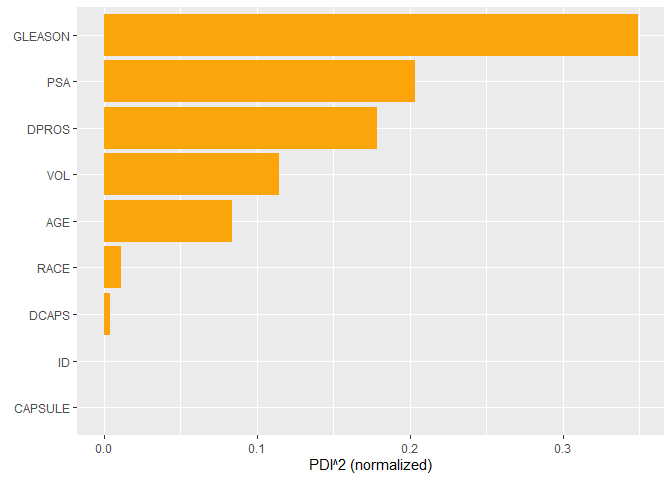
# Variable importance based on PD function
plot(pd_importance(s))
# H2O Regression ----
# Run GLM of VOL ~ CAPSULE + AGE + RACE + PSA + GLEASON
prostate_path = system.file("extdata", "prostate.csv", package = "h2o")
prostate = h2o.importFile(path = prostate_path)
predictors <- setdiff(colnames(prostate), c("ID", "DPROS", "DCAPS", "VOL"))
pros_glm <- h2o.glm(y = "VOL", x = predictors, training_frame = prostate, family = "tweedie",
nfolds = 0, alpha = 0.1, lambda_search = FALSE,
interactions = c("AGE", "GLEASON"))
# Class "H2ORegressionModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[[1]]
}
# H stats
s <- hstats(pros_glm, X = as.data.frame(prostate), pred_fun = pred_fun)
s
#> 'hstats' object. Use plot() or summary() for details.
#>
#> H^2 (normalized)
#> [1] 0.0007039798
# Pairwise statistics
plot(h2_pairwise(s, normalize = FALSE, squared = FALSE))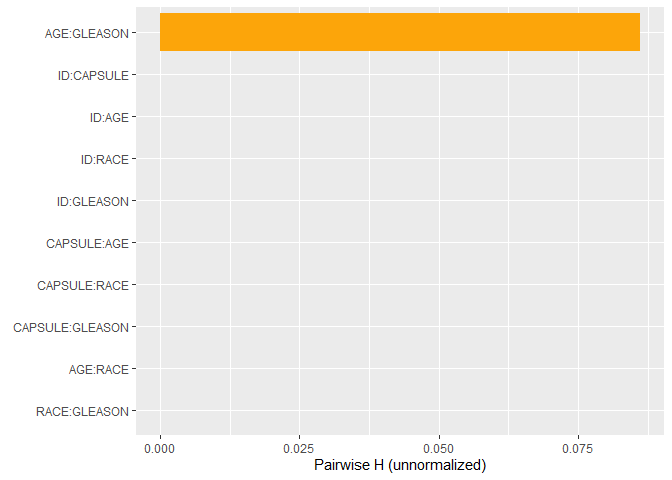
# PD plot
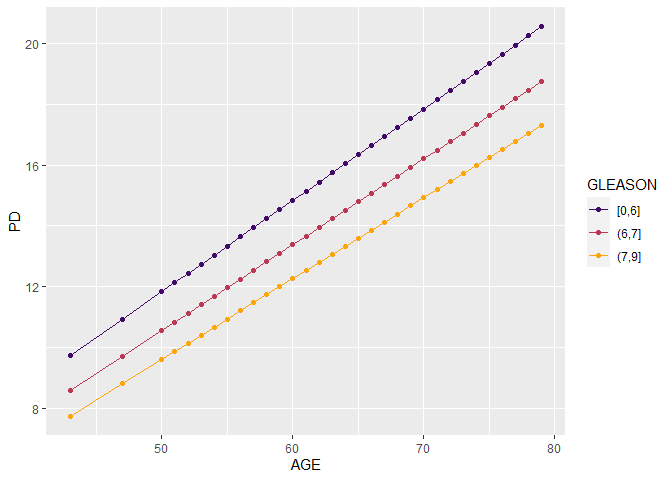
pd <- partial_dep(pros_glm, v = "AGE", X = as.data.frame(prostate), BY = "GLEASON", pred_fun = pred_fun, grid_size = 500)
plot(pd)
# H2O Multinomial ----
# import the cars dataset
cars <- h2o.importFile("https://s3.amazonaws.com/h2o-public-test-data/smalldata/junit/cars_20mpg.csv")
# set the predictor names and the response column name
predictors <- c("displacement", "power", "weight", "acceleration", "year")
response <- "cylinders"
cars[, response] <- as.factor(cars[response])
# split into train and validation sets
cars_splits <- h2o.splitFrame(data = cars, ratios = 0.8, seed = 1234)
train <- cars_splits[[1]]
valid <- cars_splits[[2]]
# build and train the model:
cars_gbm <- h2o.gbm(x = predictors,
y = response,
training_frame = train,
validation_frame = valid,
distribution = "multinomial",
seed = 1234)
# Class "H2OMulticlassModel"
pred_fun <- function(object, newdata) {
as.data.frame(h2o::h2o.predict(object, h2o::as.h2o(newdata)))[, -1]
}
# H stats
s <- hstats(cars_gbm, X = as.data.frame(cars), pred_fun = pred_fun)
s
#> 'hstats' object. Use plot() or summary() for details.
#>
#> H^2 (normalized)
#> p3 p4 p5 p6 p8
#> 0.74177545 0.06181569 0.95886855 0.07111337 0.00996367
# Pairwise statistics
plot(h2_pairwise(s, normalize = FALSE, squared = FALSE))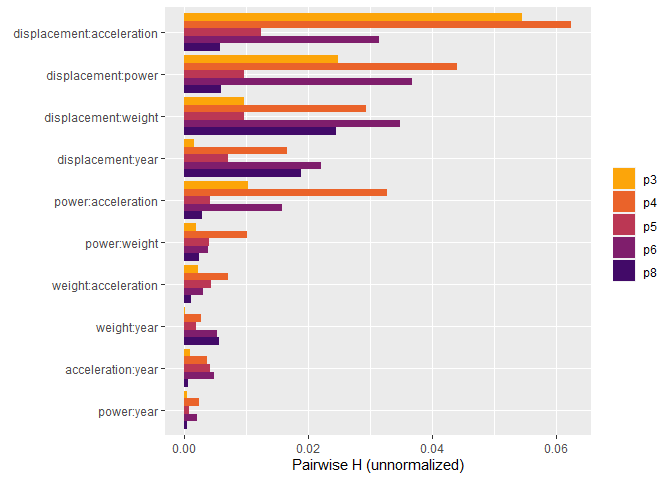
# PD plot
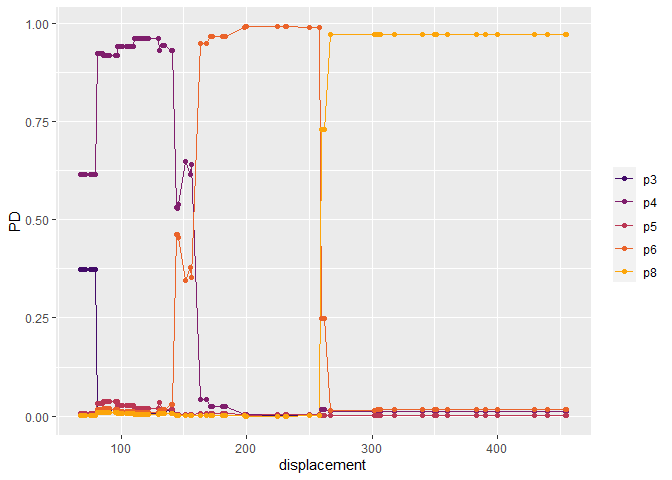
pd <- partial_dep(cars_gbm, v = "displacement", X = as.data.frame(cars), pred_fun = pred_fun, grid_size = 500)
plot(pd)
Created on 2023-10-28 with reprex v2.0.2
Awesome package! Thanks for all the work, @mayer79. Great to see such a solid implementation of H statistics in R. Well documented and compatibile with many modelling packages.
Would it be feasible to add out-of-the-box support for H2O models? Due to the way how you've set up the code, it's already possible now to use the
pred_funargument for H2O models in the various functions. See the code example down below, where I illustrate this for binomial, regression and multinomial H2O models.I believe overwriting the generics for
hstats(),partial_dep(),ice(), andperm_importance()would require two main things:pred_funargument to:as.data.frame()Further suggestions / potential improvements:
pred_funitself? Then you'd only have to overwrite that one for ranger, Learner, explainer, H2OBinomialModel, H2ORegressionModel, and H2OMulticlassModel classes instead of all ofhstats(),partial_dep(),ice(), andperm_importance().as.h2o()and then callingh2o.predict(). Doing this only once is much faster than callingpred_funmultiple times. Hence, particularly for H2O models, further speed improvements are possible by first combining the data and then callingpred_funinstead of the other way around. [Try running the below examples usingh2o.show_progress()to see a progress bar wheneveras.h2o()andh2o.predict()get called]partial_dep(..., BY = ...)could be faster by avoiding the for loop over theBYargument.hstats()could be faster by avoiding the for loop over the one-way, two-way and three-way effects. [This would be hard to refactor though]perm_importance()could be faster by avoiding the for loop over thevargument. [This might lead to memory issues though when stacking too many data frames whenv,m_repand/orn_maxis large, so potentially having an optional argument for this would be better]v = NULLinhstats()andperm_importance()could be set toobject@allparameters$x. That way no unnecessary computations are performed for columns inXnot used as features.yinperm_importance()can be set toobject@allparameters$y.Code example for H2O models:
Created on 2023-10-28 with reprex v2.0.2