A Machine Learning model for text based multi-label Intent Classification of code review questions
Code review is a systematic examination of a source code produced by a person or a group of people, to find bugs, give suggestions, make clarifications, and hence evaluate the quality of the code. In this process, there will be one or more presenters, who will be facing questions or suggestions from a panel. The dataset used here, emerged from a case study aimed at investigating the communicative intention of developers’ questions during the code review process. The challenge is to extract the necessary information from the bunch of questions so as to come up with a proper conclusion about the intention of the questions and hence create a model which predicts the same with a plausible accuracy.
The dataset is obtained from an exploratory case study done as part of a research paper : Communicative Intention in Code Review Questions, involving 399 Android code reviews, from which 499 questions have been extracted and fed into an Excel sheet. It has the following 4 fields:
inline-comment-id#CommentQuestion: question/statement raised by the reviewerFinal Label: intention of the question/statement (Target variable)
The intentions are broadly classified into 5, with further subdivisions summing up to 9 and 2 additional subdivisions, making it a total of 14. We have considered only the broad classifications and hence converted the attribute Final Label to contain only the intial level of classification with 5 subcategories, namely Suggestions, Requests, Attitudes and emotions, Hypothetical Scenario, Rhetorical Question. This converted category is fed as a new attribute New Label. See the figure for a better understanding:

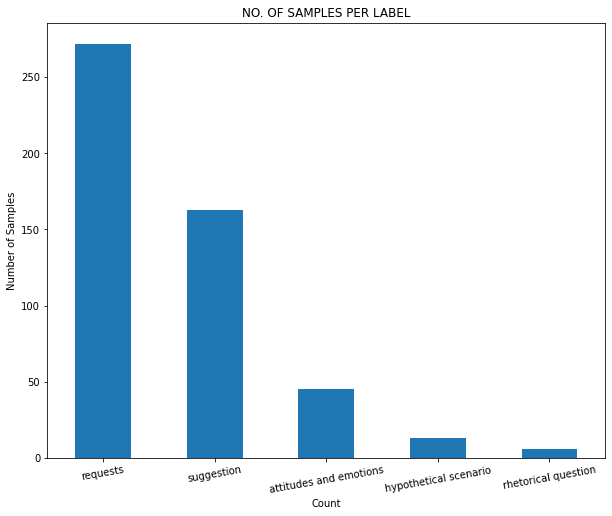
The attribute Questions is taken as the input variable and New Label as the output variable. Distribution of the output variable (number of samples per label) can be seen here:
Since the input variable is in textual form and not numerical, certain preprocessing steps are required to be done before training the model with it. The output variable can be fed to the model either directly, or after encoding it into numerical values using encoders such as the Label Encoder. Here, we have fed them directly.
The preprocessing of the text has been done using two approaches:
-
Approach 1 :
- Expanding the contractions (e.g: haven’t --> have not)
- Conversion of text to word sequence (includes conversion to lower case)
- Removal of numbers and punctuations
-
Approach 2 :
- Conversion to lower case
- Removal of numbers and punctuations
- Tokenisation : converts the sentence into a list of words
- Lemmatisation : converts each word to its root form
These approaches are done on the input variable and the results are stored in a new attribute Question Words.
We are required to add new features to train and test the model so as to enhance its accuracy. For this purpose, we have introduced new columns related to the attribute “Questions”:
excl_marks: count of exclamation marksqstn_marks: count of question markspuncts: count of punctuations like .,:;symbols: count of other symbols like *&$%=/word_count: number of words Out of these,word_countandexcl_markshave been included as features, in addition to the preprocessed text columnQuestion Words. These have been chosen because they contribute the most to the emotion in a statement/question, compared to other symbols. You can experiment training the model with other features as well. But here, the vector for training consists of only three attributes –Question Words,excl_marksandword_count.
To convert Question Words to numerical vectors, the TF-IDF vectoriser from sklearn is used, which assigns a particular numerical value to each word, signifying its importance.
For text preprocessing, the package nltk, keras, contractions, string (for removing punctuations), re (Regular Expressions) have been used. For training, testing and accuracy analysis of the model, sklearn has been used.
For each approach, the model is fit to three different classifiers - Linear SVM, Random Forest Classifier, Logistic Regression - among which Linear SVM performed the best in both the approaches.
NOTE : If any errors are raised while importing the modules from nltk, it might be because explicit download of the modules are required. In such cases, try the following code in your Jupyter notebook:
import nltk
nltk.download('stopwords')
nltk.download('wordnet')