
Jump to classic benchmarks: LINPACK, STREAM, Whetstone, Dhrystone, NBench
Jump to modern benchmarks: CoreMark, HINT
This repository packages a selection of C program sources useful for benchmarking a wide variety of systems and compilers, including a number of classic, industry-standard benchmarks as well as some select programs that can be used as benchmarks. Sources in this package generally target ANSI C (ISO C90) compliance to maximize compatibility, though most benchmarks are still in the process of being refactored to that standard.
Sources in this package are at a minimum tested with GCC on Linux and a strict warning set. They are (variably) further tested with GCC on Mac OS, OpenBSD, AIX, HP-UX and other systems, as well as proprietary compilers such as IBM VisualAge C and HP C.
Always remember that a benchmark is ultimately only accurate for evaluating a system's performance on that very specific set of operations which don't always reflect its typical workload, and thus only paints a partial picture of your system's overall capabilities. Many of the programs included in this package are single-threaded and very CPU-focused, and won't tell you as much about your system's memory, disk, or I/O capabilities among other critical architectural features that may allow it to pull ahead of supposedly faster systems in many use cases.
Nonetheless, these programs are still easy and useful tools for evaluating compilers and giving you a rough idea of how your system performs and how it may compare to others.
Each benchmark in this package resides in its own directory and can be quickly
built by issuing the make command, or built and run with default parameters
using make run. ANSIbench makefiles by default expect the GNU C Compiler to
be used, though this can be changed using the cc and opt directives.
Most benchmarks support run parameters whose defaults can be seen at the top
of each makefile. The most common parameter is n, which is used to specify
array sizes or numbers of loops to iterate through in most benchmarks.
Some benchmarks may require platform-specific accomodations that the benchmark
itself can't determine automatically. These can be specified using the
platform parameter, presets of which are found in the mk directory if
applicable.
By default, benchmarks attempt to build using GCC with second-level
optimizations, but alternative compilers and optimizations can be specified
using the cc and opt directives, for example in this attempt to build
CoreMark on an HP-UX system with HP C:
make cc=hp-c opt=o4
Directive values refer to files or directories within the mk directory,
which allow for more modular, editor-free benchmark configuration and quicker
validation of multiple compilers and optimization levels.
If a specific optimization flag you are looking for is not present in a default
optimization preset, check your compiler's corresponding xflags directory or
specify it directly at build time using the XCFLAGS parameter.
Mature, venerable industry-standard benchmarks designed for use on a wide variety of systems and architectures
First introduced in 1979, the LINPACK benchmark measures a system's floating-point math capabilities by solving a dense system of linear equations. LINPACK remains an industry standard particularly in supercomputing, where it is used to build the TOP500 list of the world's fastest computers. LINPACK measures system performance in terms of Floating Point Operations per Second, or FLOPS. Most small systems today typically operate on the order of megaFLOPS, gigaFLOPS and teraFLOPS, while supercomputers often operate in the petaFLOPS range.
LINPACK evaluates performance with both single-precision (32-bit) and double-precision (64-bit) floating-point numbers, usually selectable at compile time. Single-precision values are most frequently used in "everyday" desktop computing applications where precision and utmost accuracy are not as necessary, while double-precision values are more frequently used in scientific and technical applications where minimal approximation is preferable. Many LINPACK variants default to double-precision (including the one in this package) because of the benchmark's significance in high-performance computing.
This version of LINPACK is a C translation of the original FORTRAN version first written in 1988 by Bonnie Toy and later updated in 1993 by Will Menninger, it most notably allows for user-definable matrix sizes and averages rolled and unrolled performance in its report. The original source can be found here.
This source has been slightly modified in this package to make it easier to automate and execute from scripts. It can now take the matrix size as an argument and the output has changed slightly for a cleaner look.
LINPACK has a single parameter n which can be passed to it when running
with make run, this corresponds to the matrix size. Typical matrices
used with LINPACK are of order 100x100 or 1000x1000, though any value of
n can be passed in, within reason. LINPACK can also be run without the
makefile by simply running the executable, which will then ask for n if
it wasn't supplied as the first argument.
The single LINPACK source file is used to build two executables, linpacksp
for evaluating single-precision performance and linpackdp for evaluating
double-precision performance. Both are identical in functionality.
Running LINPACK with make run will run both the single-precision and
double-precision versions of the benchmark.
The LINPACK sources included in this package build easily under CodeWarrior on the Classic Macintosh with no modification required, using the SIOUX (Simple Input and Output User eXchange) library to provide a text console interface for input and output.
Because CodeWarrior cannot utilize the included makefiles, the source files
must be manually included in a CodeWarrior project with appropriate build
targets specified for single and double-precision executables. Because LINPACK
builds by default in double-precision mode, the symbol SP must be defined at
compile time to override this, typically accomplished using a command-line
option such as -DSP when calling GCC, for example.
Rather than using command-line options to define symbols prior to compilation,
CodeWarrior instead utilizes "prefix files," and to this end a simple header
file sp.h is included in the LINPACK utils directory to define SP at
compile time. Simply include sp.h in your project and reference it as a
prefix file in your build target to build a single-precision executable.
You'll likely need to include it in all of your build targets to avoid errors;
double-precision builds simply won't need to reference it.
After setting up your build targets, LINPACK can be easily built and run directly from the CodeWarrior IDE.
STREAM is a synthetic memory benchmark first developed in 1991 by Dr. John McCalpin at the University of Delaware's College of Marine Studies. It is described by McCalpin as "an extremely simplified representation of the low-compute-intensity, long-vector operations characteristic of ocean circulation models" and has since become a standard for measuring memory performance on various computer systems.
STREAM measures memory performance using four separately timed kernels corresponding to copy, scale, add and "triad" operations, with the latter kernel (a combination of the three others) usually cited for in-general comparison. STREAM results are often used alongside LINPACK when evaluating supercomputer performance, as memory bandwidth is often even more important than raw processor speed when working with the large data sets typical in supercomputing workloads.
This is the "official" C version of STREAM which can be found on the
STREAM website. The source has been very
minimally modified for inclusion in this package mostly to make it acceptable
to an ANSI C compiler and easier to automate using a makefile. Only comments,
print statement formatting and some macro definitions have been modified
(to allow the default array size to still be properly set in the event of an
empty STREAM array size definition argument from a non-GNU makefile) with the
deprecated Time Zone structure removed in the mysecond() function.
Because of the minimal nature of these modifications, this version of STREAM
should still be compliant with the official
run rules.
STREAM by default operates on an array of 10,000,000 elements, which may be
too small or too large for some systems. In a similar manner to LINPACK, the
array size can be configured from the makefile using the parameter n. Unlike
LINPACK, this parameter is defined at compile-time, and STREAM will need to be
recompiled to use a different array size.
It is recommended to specify an array size at least 4 times the size of your
system's processor caches in order to ensure that the system memory is
actually what is being benchmarked. The default n=10,000,000 parameter
should be acceptable for caches up to 4 MiB, but many modern systems are now
shipping with 8 MiB of cache and beyond, meaning n will need to be larger
for a result that properly reflects memory performance.
STREAM by default is built expecting OpenMP support on the target system. This
can be disabled simply by specifying mp= to wipe the mp parameter when
running the makefile. -DDIS_OPENMP may also need to be passed in through
XCFLAGS.
HP-UX with HP C requires certain preprocessor macros defined to compile STREAM
successfully which are included as platform directives hp-ux and hp-ux-mp
depending on whether or not OpenMP is being used. mp will need to be cleared
if using the former.
The Whetstone benchmark is a synthetic benchmark that primarily measures a computer's floating-point performance. Originally written in ALGOL 60 in 1972 by Harold Curnow of the Technical Support Unit of the United Kingdom's Department of Trade and Industry, it was one of the first general-prupose benchmarks to set industry standards for evaluating computing performance.
The Whetstone benchmark is based on prior work by Brian Wichmann of the UK's National Physical Laboratory (NPL) who collected statistics from a modified version of the "Whetstone" ALGOL compiler running on an English Electric KDF9 computer at the NPL and used the data to build a set of 42 simple statements that could be used to evaluate the efficiency of other compilers and processor performance.
Whetstone speed ratings are measured in Whetstone Instructions Per Second (WIPS), and most early versions of the benchmark output ratings in KWIPS, while most newer versions (including this one) produce ratings in MWIPS. Although Whetstone performs a general mix of calculations, most of them are still overwhelmingly floating-point heavy, and because only a small amount of data is referenced, architectural factors such as the performance of the memory subsystem are barely if at all evaluated, especially if the processor being evaluated has large enough caches.
The Whetstone version included in this package is the "updated" C translation found on the Netlib repository with minimal modification, mostly just to printed output. This version was translated directly from the original ALGOL 60 version of the benchmark, and has output similar to the FORTRAN version.
By default, Whetstone is configured to loop 1,000,000 times, which is often
too little for newer systems. Change the loop count by specifying the n
parameter with make run or running the binary directly with the loop count
as the first argument.
Whetstone can also loop continuously with the -c flag, which is not
used by the makefile.
It's always recommended to build Whetstone with PRINTOUT defined for proper
output, this ensures that optimizing compilers do not over-optimize the
benchmark by omitting computations whose end result are never shown to the
user.
A pun on the name of the floating-point focused "Whetstone" benchmark, the Dhrystone benchmark is, like Whetstone, a synthetic benchmark derived from statistical analysis with the goal of representing an "average" program. Dhrystone is unlike Whetstone in that it focuses entirely on integer arithmetic, making it more relevant to small systems and typical computing use cases in general than the more scientific and technically-oriented Whetstone.
Dhrystone was originally written in the Ada programming language by Reinhold P. Weicker of Siemens Nixdorf Information Systems in 1984, based on analysis of a number of programs in numerous languages. Weicker characterized these programs based on common constructs such as procedure calls and variable assignments, and used this data to write a benchmark corresponding to a "representative mix" of these features, similar to the design process of the Whetstone benchmark over a decade earlier.
Dhrystone was first ported to C by Rick Richardson of PC Research, Inc. and distributed via Usenet. Richardson and Weicker later collaborated on subsequent versions of the benchmark, their work mostly centered around standardizing the Ada, C and Pascal versions as well as out-smarting increasingly intelligent optimizing compilers.
Dhrystone speed ratings are measured in Dhrystones Per Second, corresponding to the number of times the main Dhrystone loop iterates in a single second. This quantity is often further refined into "VAX MIPS," corresponding to a multiple of the DEC VAX-11/780 superminicomputer's reported score of 1,757 Dhrystones per second.
While Dhrystone attempts to emulate the "typical" program, it is nonetheless unsuitable for use as a sole means of benchmarking a system for a number of reasons, many cited by the authors themselves:
- Dhrystone only evaluates processor integer performance, it does not evaluate other significant architectural components such as memory/disk subsystems, or perform any I/O operations. Dhrystone also makes limited use of operating system calls.
- Dhrystone is an extremely small benchmark operating on an extremely small data set, both of which can easily fit completely into extremely fast modern processor caches. Most "typical" programs are too large to completely fit in cache, and often operate on data stored in memory or on disk as well as cached, frequently accessed data.
- Dhrystone's integer/system focus may paint a skewed picture of systems designed with an emphasis on scientific and technical computing where floating-point math is more prevalent.
- The C version of Dhrystone places increased emphasis on string operations compared to the reference benchmarks, due to C's lack of a built-in string data type.
With this in mind, it's important to treat Dhrystone results as only a rough overview of a system processor's integer performance under very ideal conditions, and combine it with other benchmarks when evaluating a system as a whole. Dhrystone nonetheless is still widely used in the industry, especially in embedded systems where VAX MIPS is still often cited in marketing literature.
A modern alternative to Dhrystone that attempts to provide solutions to many of its shortcomings is the EEMBC's CoreMark benchmark, which is also included in this package and recommended for use especially with newer systems where Dhrystone's reporting can be quite inaccurate.
The Dhrystone version included in this package is the most widely used version (2.1) with some modifications mostly to make it acceptable to ANSI-compliant C compilers as well as automation improvements such as the ability to take in the number of iterations as an argument at execution time. It has also been modified to compute and report the VAX MIPS rating from the benchmark result and display it after the Dhrystones per second rating.
Because the C Dhrystone translation is still mostly written in K&R-style C, it generates a lot of warnings when compiled with the package's standard flag set. The whetstone source will eventually be revised to bring it into compliance with ANSI C.
By default, the Dhrystone benchmark loops 10,000,000 times. This can be
increased or decreased to better evaluate a given system by setting the
n parameter when running the benchmark through the makefile, or
by specifying the number of loops when running the executable directly.
Dhrystone requires the parameter HZ to be defined at compile time, which
corresponds to the granularity of the timing function. This is typically 100
on most newer systems and is the default value, however it can still vary and
should be confirmed before running the benchmark. If you're working in a POSIX
environment, the script gethz.sh will compile and run a simple program that
determines the value of the _SC_CLK_TCK parameter which corresponds to the
number of clock "ticks" per second as configured in the kernel. This
information can also be retrieved by issuing getconf _SC_CLK_TCK (or getconf CLK_TCK if _SC_CLK_TCK is unsupported) and passing the value into make using
the hz parameter. An example build and run operation might be: make run n=50000000 hz=120 occ=gcc-ofast to build and run Dhrystone on a GNU/Linux
system with maximal optimization and a kernel configured for 120 clock "ticks"
per second.
The timing function to use can also be passed at compile time, by default
Dhrystone will be built to use wall clock time with time() specified by the
-DTIME flag, but it can also be configured to use times() for process time
with -DTIMES. You can configure Dhrystone to be built with the times()
function for timing by including time=TIMES in your make command.
The makefile is configured to build and run Dhrystone both with and without register variables, meaning that Dhrystone will assign some variables to dedicated processor registers when possible for faster access than from cache or memory.
Formerly known as BYTEmark or the BYTE Native Mode Benchmarks, NBench is a self-contained suite of synthetic benchmarks designed to test the capabilities of a computer's CPU, FPU and memory subsystem, scoring them using an index based on a Dell Pentium 90 running MS-DOS or an AMD K6-2/233 running Linux.
NBench was ported to Linux by Uwe F. Mayer (who still hosts the sources on his University of Utah website) in late 1996 based on BYTEmark 2.0 which was largedly developed by Rick Grehan, a significant contributor to BYTE's many benchmarking efforts, who started work on that version in 1994, describing it in BYTE's March 1995 issue.
BYTEmark 2.0 and NBench are described as an "algorithm-based" suite that, while still synthetic, is far less so than its predecessors, evaluating a system using a suite of small program kernels as opposed to simple repetitive sequences of single or similarly few instructions. In total, NBench evaluates ten algorithms:
- Numeric Sort: Measures the time needed to sort a one-dimensional array of signed long integers using a heapsort algorithm. Chosen as a general-purpose processor performance test due to its common and fundamental nature.
- String Sort: Similar to the above, but uses a heapsort algorithm to sort strings of abritrary content and length rather than integers.
- Bitfield: Evaluates a system's ability to manipulate single bits with an algorithm best described as a simulation of how an operating system might keep track of disk block allocation using a bit map in memory.
- Emulated Floating-Point: A small floating point emulation software package that performs fundamental arithmetic; addition, subtraction, multiplication and division without the use of a hardware floating-point unit.
- Fourier Coefficients: Exercises a system's trigonometric abilities by calculating the first n Fourier coefficients for a cyclic waveform constructed using a logarithmic function.
- Assignment Algorithm: Performs a variety of operations on two-dimensional integer arrays by solving a simulated resource allocation problem.
- Huffman Compression: Uses the Huffman compression algorithm to test a system's competence at a mixture of text processing, complex data management and bit manipulation.
- IDEA Encryption: Measures the ability of a system to encrpyt and decrypt data using the International Data Encryption Algorithm (IDEA), operating on groups of 16 bits at a time.
- Neural Net: Teaches a simple back-propagation neural network (of the type originally presented by Maureen Caudill in the October 1991 BYTE article "Expert Networks") to recognize various ASCII characters. Primarily a floating-point benchmark making heavy use of the exponential function.
- LU Decomposition: Uses the LU Decomposition algorithm to solve systems of linear equations and measure a system's fundamental floating-point capabilities.
There are caveats to this suite noted by Grehan in his 1995 article, most notably the extremely small size of the tests - typically less than 16 KiB. This means that NBench tests will often fit completely in a CPU's fast cache memories and thus their scores will represent ideal scenarios rather than the average case, where complex programs often do not fully fit within cache.
NBench was designed to be highly portable and builds on most systems with ease. The version included in this package sports no modifications from Mayer's standard distribution, differing only in the way the files are structured and the way the benchmark is built: dynamically linked rather than statically linked due to some problems with the standard build method on certain (mostly embedded) systems.
NBench determines workloads dynamically requires no parameters from the user,
thus you can simply build and run it immediately with make run from its
directory.
Modern industry-standard (and upcoming) benchmarks that attempt to solve the various problems of or otherwise improve on their "classic" predecessors
The CoreMark benchmark is a product of the Embedded Microprocessor Benchmark Consortium, and aims to provide a modern alternative to the venerable integer-focused Dhrystone benchmark while answering many of its shortcomings and improving its relevance primarily in the area of low-power embedded systems, where Dhrystone is still predominantly used by vendors to provide rough performance estimates and means of comparison with competing products.
CoreMark was primarily developed by Shay Gal-On, then the director of software engineering at the EEMBC, as the EEMBC's first freely available standard benchmark. CoreMark answers a number of problems with the original synthetic Dhrystone benchmark with an entirely new design built around a number of commonly used algorithms in microcontrollers and microprocessors alike, including list procesing, matrix manipulation, state machines and cyclic redundancy checks, as opposed to Dhrystone's purely synthetic, statistically derived loop that intends to simulate the "average" program. In addition to a more real-world focus, CoreMark also does not call any external libraries in timed sections of the benchmark, so as to most effectively report on the performance of the processor itself rather than the quality of the target system's standard libraries. Lastly, CoreMark is also designed more defensively against compiler optimizations than Dhrystone, to keep any actual computation from being "optimized away" at compile time, an oft-cited (and exploited) problem with Dhrystone.
Like Dhrystone, CoreMark reports its scores in terms of the number of benchmark iterations per second.
CoreMark is freely distributed by the EEMBC under the Apache 2.0 license and is available to any interested party through the EEMBC's official GitHub repository. The source files included in this package are mostly identical to those in the official repository, but with some modifications to address compiler warnings:
- Prototypes for seed argument handling have been moved from
core_main.ctocoremark.has the functions are called from multiple files - Missing function prototypes have been added to
core_list_join.c - Definition of
check_data_types()incore_util.chas been changed tocheck_data_types(void)
Though these changes are minimal and likely don't impact benchmark performance, it's still recommended to use the official repository for any official validation and score submission purposes due mostly to differences in building, directory structure, documentation and reporting arising from this package's exclusive focus on convenient personal and non-marketing usage.
By default, the makefile is configured to build and run CoreMark with the seeds
0x0, 0x0 and 0x66 and 20,000 iterations, the latter of which can be tweaked
with the n parameter. CoreMark is required to run for at least 10 seconds in
order to obtain a valid result.
CoreMark is capable of multi-threaded execution by setting the threads
parameter. By default, an EEMBC sample POSIX Threads implementation will be
used, but a fork()-based implementation is also available. Lines for both are
provided in the CoreMark makefile.
Although released in 1994, the Hierarchical INTegration (HINT) benchmark is considered a "modern" benchmark due to its novel and innovative design, which evaluates a computer system's performance in terms of the quality of a solution, rather than simply the overall amount of time it took to compute it, and in fact is built around a solving problem that has no exact, final solution, something which accurately reflects many problems encountered in the world of high-performance computing, where models are continuously refined and improved to gain more and more resolution, rather than solved outright to obtain some exact quantity or output.
HINT was designed by Dr. John Gustafson and Quinn Snell of the US DoE's Ames Laboratory, taking some ideas from the earlier SLALOM benchmark but with an entirely new fundamental concept based on the measurement of Quality Improvements Per Second (QUIPS) on a problem not of fixed size nor fixed time. HINT derives this metric from the following task, described in this publication on Gustafson's website:
Use interval subdivision to find rational bounds on the area in the xy plane for which x ranges from 0 to 1 and y ranges from 0 to (1- x) / (1+ x). Subdivide x and y ranges into an integer power of two equal subintervals and count the squares thus defined that are completely inside the area (lower bound) or completely contain the area (upper bound). Use the knowledge that the function (1- x) / (1+ x) is monotone decreasing, so the upper bound comes from the left function value and the lower bound from the right function value on any subinterval. No other knowledge about the function may be used. The objective is to obtain the highest quality answer in the least time, for as large a range of times as possible.
In the simplest terms, HINT successively refines the upper and lower bounds
(quality) of the function (1-x)/(1+x) with each subinterval, eventually
arriving at a solution similar to this example with 8-bit data types shown
below:
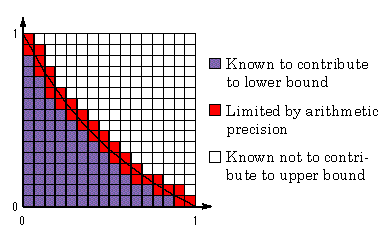
The quality of this solution can further be refined theoretically infinitely, only limited by the hardware of the system it is running on and the precision of the selected data types.
While HINT outputs a "Net QUIPS" score at the end of every run, actual HINT results are dumped to a file as a table of QUIPS observed over time and are meant to be plotted to better evaluate the performance of not only the processor but the memory subsystems as well. Gustafson and Snell provide an example plot of HINT results from an SGI Indy workstation with a variety of data types in HINT's introductory publication:
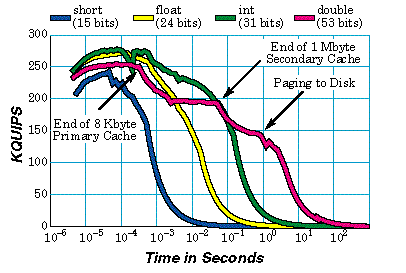
While net QUIPS can still be considered a valid performance estimate, plotting HINT data provides much more insight into more significant system components, as well as the system's ability to sustain a given rate of QUIPS over an extended period of time.
The version of HINT included in this package is the "serial" variant for
single-processor Unix systems, which isn't properly optimized for parallel
execution. A parallel version of HINT does exist, and may be included in this
package at a later time. Some modifications were introduced primarily for
packaging and ANSI compliance, mainly the removal of the long long data type
and fixed data file names to allow for proper execution from the makefile.
John Gustafson maintains a small page dedicated to HINT on his website, including links to some interesting publications, results and source code.
By default, the makefile builds a double executable when run or builds all
executables when run with make alone.
The data type used by HINT can be changed at compile time with the make target
or dtype parameter (when using make run) set to one of the following values:
shortintlongfloatdouble(default)ldouble(long double)
HINT requires additional flags to compile on some platforms, currently only
HP-UX with platform=hp-ux is accounted for.
The HINT benchmark can take a considerably long time to run depending on the data type selected, be patient with it!