Home
The aim of the RCNet is to make the reservoir computing methods easy to use and freely available for .net platform without dependency on other libraries. Two main reservoir computing methods are called Echo State Network (ESN) and Liquid State Machine (LSM). RCNet supports both of these methods. However, since ESN and LSM are based on very similar principles, RCNet brings the option to combine them at the same time. This approach, as I believe, opens up new interesting possibilities. This general implementation is called "State Machine" in the context of RCNet.
I have no ambition to describe here the principles of the reservoir computing paradigm theoretically, there are many available documents on the Internet that explain the issue in detail. Primary aim of these pages is to describe the use of the RCNet library and I want to keep things as simple as possible. Still, I will allow a very brief introduction to the reservoir computing concept to facilitate understanding of RCNet library functionality and how it works behind.
Recurrent neural networks (RNNs) are very well suited for processing time-dependent data such as
- Forecasting the development of time series
- Classification (pattern recognition, etc.)
Examples:
- Forecast the future development of a time series (such as a share price)
- Based on EEG readout, recognize the coming epileptic seizure
- Recognize the speaker's emotion by voice intonation
- What is the probability that the driver of the second car will turn into my lane at the next moment?
- etc.
Reservoir computing makes it possible to use the benefits of the recurrent network very efficiently. Efficiency lies in the fact that the synapses and their weights in the recurrent network (called reservoir) are randomly chosen at the beginning and remain fixed (in contrast with traditional training methods for RNNs). Only the Readout layer is trained, most often very simply, by the linear regression.

- The input data is continuously pushed into the reservoir through special input neurons (yellow balls). Input neuron is very simple interface which only mediates external input for synapses (yellow arrows) delivering input to the reservoir's hidden neurons.
- Recurrently connected hidden neurons (blue balls interconnected by blue arrows) do the nonlinear transformation and provide reservoir dynamics. Input signal of each hidden neuron consists of summed weighted output signals from connected hidden neurons and input neurons. This can be a little confusing. Everyone probably thinks of the order in which the hidden neurons count their input signal? The answer is simple: It does not matter. The signal that provides hidden neuron to other neurons at the time T corresponds to the state at the last completed recomputation of the entire reservoir (T - 1).
- At each time point, after the reservoir recomputation, the historical and current input data are described by the current state of the reservoir neurons. The states of reservoir neurons are so-called predictors.
- Predictors are periodically collected (mostly after each computation cycle) and sent to the readout layer
Hidden neuron and its Activation function
In general, neuron is a small computing unit that processes the input signal (stimulation) and produces an output signal. The way neuron processes the input signal to output signal defines its so-called Activation function. The neuron can be simply understood as the envelope of its Activation function, where the neuron provides the necessary interface and the Activation function performs the core calculations. Activation functions (and therefore also neurons) are distinguished into two types: Analog and Spiking. For a better insight into the activation functions, look at the wiki pages.
Analog activation function has no similarity to behavior of the biological neuron. It is always stateless, which means that the output value (signal) does not depend on the previous inputs but only on current input at the time T and particular transformation equation (usually non-linear).
A typical example of the analog activation function is TanH (hyperbolic tangent), which non-linearly transforms the input value to the output in the range (-1, 1).

Spiking activation function attempts to simulate the behavior of a biological neuron that accumulates (integrates) input stimulation on its membrane potential and when the critical threshold is exceeded, fires a short pulse (spike), resets membrane and the cycle starts from the beginning. In other words, the function implements one of the so-called Integrate and Fire neuron models. For a better insight into the biological neuron models, look at the wiki pages.
It is obvious that spiking activation function is time-dependent and must remember its previous state.
The following figure illustrates the progress of membrane potential under constant stimulation. The figure is from the great online book Neuronal Dynamics and shows the behavior of the "Adaptive Exponential Integrate and Fire" model (class AdExpIF in RCNet).
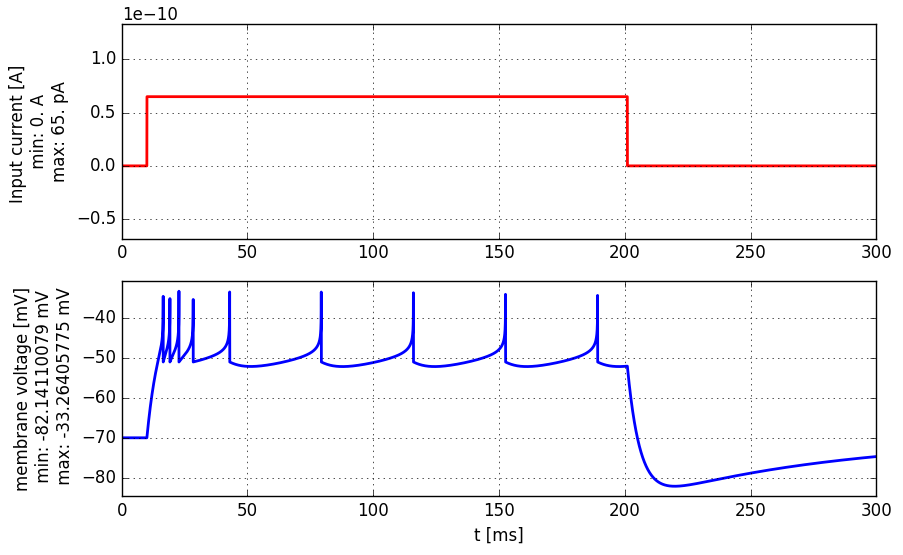
Note that the membrane potential (blue line) is not an output signal. The output signal consists of nine short constant pulses (spikes) at time points where membrane potential exceeds the firing threshold -40 mV. So the output is a zero signal and only at firing times the signal has a value of 1.
Input neuron has associated no activation function and is very simple. Its purpose is only to mediate external input and facilitate its delivery into the reservoir's hidden neurons through synapses.
Synapse is simply the interconnection of two neurons, ensuring unidirectional signal transmission from source nouron to target neuron. Each synapse transmits the signal weighted. If the signal is weighted by a constant weight, we are talking about a static synapse. If the weight changes over the time, we are talking about a dynamic synapse. Synapse can also delay the signal, usually proportionally to the length of the synapse.
Readout layer maps predictors (neurons' states) from the reservoir to the values of one or more output fields. The so-called supervised training is used and each output field is trained separately. The most commonly used technique is linear regression where linear coefficients are searched that best directly map the predictors to the corresponding desired output field values.
- Reservoir is simply the data preprocessor and typically contains hundreds (and sometimes thousands) of recurrently synaptically connected hidden neurons.
- The influence of historical input data on the current states of hidden neurons is weakening in time. The memory capacity of the reservoir depends on several aspects, such as the number of hidden neurons, the type and settings of hidden neurons, the density of the interconnection and the behavior of used synapses (signal delay)
- Synapses play an important role. It is necessary to ensure that the input signal will pass through the reservoir without the neurons being oversaturated.
- The rich reservoir dynamics allows to train readout layer to map the same predictors to the different outputs (predictions) at the same time. The most commonly used training method is linear regression
Simplified training scenario:
- Collect all known input and desired output data
- Normalize and standardize the data
- Through reservoir, transform the collection of input data into a collection of predictors
- Train readout layer to be able to map the predictors to the desired output data
The use of a trained network:
- Get next known input data
- Normalize and standardize the data by the same way as during the training
- Through reservoir, transform the input data into the predictors
- Push predictors into the readout layer and let it to compute output data