BUG: bootstrap_plot samples without replacement #45634
Description
Pandas version checks
-
I have checked that this issue has not already been reported.
-
I have confirmed this bug exists on the latest version of pandas.
-
I have confirmed this bug exists on the main branch of pandas.
Reproducible Example
import pandas as pd
import numpy as np
from pandas.plotting import bootstrap_plot
np.random.seed(0)
data = pd.Series(np.random.rand(1000))
bootstrap_plot(data, size=1000, samples=500, color="grey")Issue Description
bootstrap plot samples without replacement, see
pandas/pandas/plotting/_matplotlib/misc.py
Line 305 in ad19057
random.sample instead of random.choices.
This means if you boostrap_plot with size equal to the original dataset, all your bootstrap samples are the same.
Expected Behavior
The code above produces
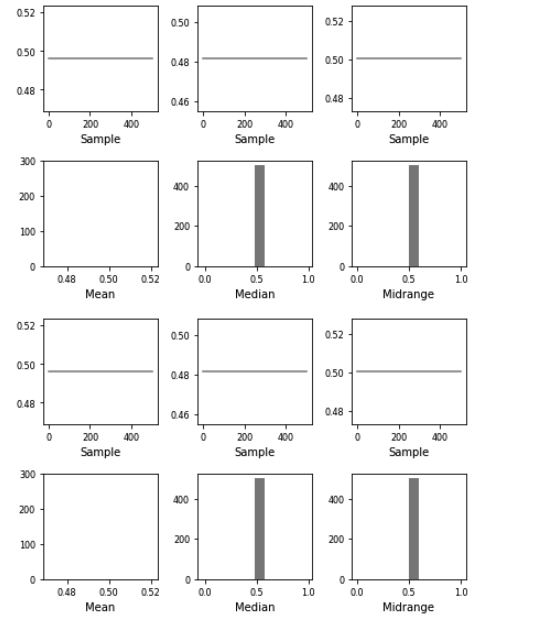
I would expect the output to look like
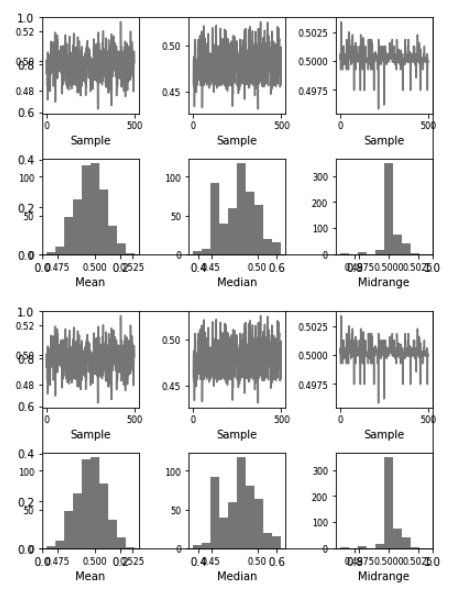
As an alternative to fixing this issue, I would also suggest removing the plot entirely.
Installed Versions
INSTALLED VERSIONS
commit : bb1f651
python : 3.8.12.final.0
python-bits : 64
OS : Linux
OS-release : 4.14.252-131.483.amzn1.x86_64
Version : #1 SMP Mon Nov 1 20:48:11 UTC 2021
machine : x86_64
processor : x86_64
byteorder : little
LC_ALL : None
LANG : en_US.UTF-8
LOCALE : en_US.UTF-8
pandas : 1.4.0
numpy : 1.21.3
pytz : 2021.3
dateutil : 2.8.2
pip : 21.2.4
setuptools : 58.0.4
Cython : None
pytest : None
hypothesis : None
sphinx : None
blosc : None
feather : None
xlsxwriter : None
lxml.etree : 4.6.3
html5lib : None
pymysql : 1.0.2
psycopg2 : None
jinja2 : 3.0.3
IPython : 7.28.0
pandas_datareader: None
bs4 : 4.10.0
bottleneck : None
fastparquet : None
fsspec : 2021.10.1
gcsfs : None
matplotlib : 3.4.3
numba : None
numexpr : None
odfpy : None
openpyxl : 3.0.9
pandas_gbq : None
pyarrow : 5.0.0
pyreadstat : None
pyxlsb : None
s3fs : 2021.10.1
scipy : 1.7.3
sqlalchemy : None
tables : None
tabulate : None
xarray : None
xlrd : None
xlwt : None
zstandard : None