{kind=link}
{kind=link}
Make embedding spaces interoperable with simple, drop-in adapters.
Bridge embedding spaces. Use adapters, not hacks.
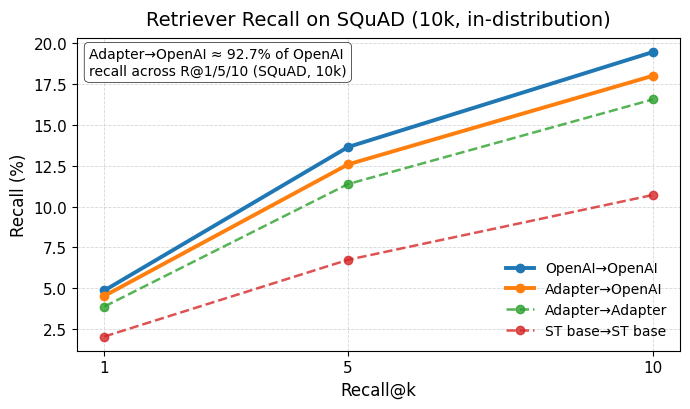
all-MiniLM-L6-v2 + Embedding Adapter reaches ~93% of OpenAI’s
text-embedding-3-small recall (R@1/5/10) while running locally in just a few ms.

Translate embeddings between model spaces locally with a single command.
pip install embedding-adaptersembedding-adapters embed \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-small \
--flavor large \
--text "Where can I get a hamburger?"^ outputs an embedding and confidence score
embedding-adapters is a lightweight Python library and model collection that lets you map embeddings from one model’s space into another’s.
Instead of:
- Re-embedding an entire corpus every time you change models or providers, or
- Locking your search / RAG stack to one vendor’s embeddings,
you can:
- Embed with a source model (often local / open-source),
- Pass those vectors through a pre-trained adapter, and
- Use the result in a target embedding space (for example, an OpenAI embedding index).
The goal is to make “take vectors from here, make them look like they came from there”:
- Easy to adopt – one import, one factory call, one
.forward - Consistent – adapters are trained under a known setup (e.g. normalized inputs)
- Practical – designed for real retrieval, migration, and experimentation workflows
Quality / out-of-distribution (OOD) scoring is supported as an optional diagnostic feature. It can help you understand when an adapter is likely to behave well on your data, but it is not required to start using the library.
Real problems this helps with:
-
Avoid full re-embedding when changing models
You already have a corpus embedded with Model A (e.g. a cloud provider). You want to start using Model B (e.g. a locale5variant) for queries or new content, but re-encoding everything is expensive or disruptive. An adapter lets you map into the existing space instead of re-building the world in one shot. -
Local-first or hybrid setups
You want to run a strong open-source model locally (for cost, latency, or privacy reasons), while keeping your vector database and relevance logic in terms of a “canonical” target space. Adapters let you keep that target space stable while you change what runs at the edge. -
Cross-model interoperability
Treat “embedding space” as a contract, not “whatever the current provider happens to be.” Adapters let you plug multiple embedding backends (Hugging Face, OpenAI, etc.) into a shared or slowly evolving space. -
Fast experimentation
You want to try different source models against a fixed target space / index without rebuilding the entire system every time. Adapters give you a low-friction way to do that. -
Extremely Cheap embeddings
Run low-cost or local embedding models (MiniLM, e5, etc.) while still operating in a premium target space like OpenAI’s. You keep the retrieval quality of the expensive model for a fraction of the cost, and you only pay the cloud provider when you choose to — not for every embedding. -
Fast Local embeddings
Local or lightweight models can generate vectors in just a few milliseconds. With an adapter, you keep this speed while still operating inside a stronger target embedding space. This makes retrieval feel instant and dramatically reduces latency for chat, search, ranking, and real-time applications.
In short: EmbeddingAdapters turns cross-model compatibility into a first-class, reusable primitive, rather than an ad-hoc alignment script hidden inside a platform or one-off migration projectps!
When serving users with familiar or standard questions, waiting ~200ms for a cloud-based embedding model can be unnecessary overhead. By using a local model (or caching strategies) and an adapter layer, you can answer common queries quickly while still aligning with the canonical embedding space. This improves responsiveness and user experience without compromising the integrity of your system - Don't waste time in unnecessary network hops!
Intelligent routing for difficult queries When the system recognizes a query as unfamiliar, complex, or requiring higher fidelity, embedding-adapters can help route the request to a stronger or more specialized provider. You maintain a consistent target space while flexibly selecting the best model for this
EmbeddingAdapters has the tools for this! Just use our quality endpoints and find out if your query will work, if it won't route to your cloud provider.
Mapping between vector spaces is not a new idea in itself. People have aligned word embeddings, distilled models, and trained student/teacher embeddings for years.
What is new and different about this project is how that idea is packaged and exposed:
- A registry of pre-trained, cross-model adapters you can load with one call, instead of rolling your own alignment for every project.
- A focus on model-to-model compatibility, not just query-only tweaks for a single model and corpus.
- An explicit design for retrieval and system builders, not just a research demo:
- Known training setup (e.g. normalization requirements)
- Simple, stable API surface
- Optional diagnostics to help you understand when adapters are likely in-distribution
- A library that is independent of any single vector database or provider. It can sit next to whatever infrastructure you already use.
Platforms and vector DBs sometimes implement internal or corpus-specific adapters, but they tend to be:
- Closed, tied to that one platform, or
- Hidden behind higher-level tooling, not exposed as a reusable, model-agnostic building block.
embedding-adapters makes cross-model adapters themselves the product: loadable, inspectable, and usable wherever you build your systems.
-
🔁 Pre-trained adapters between embedding spaces
Load an adapter bysourceandtargetmodel IDs and apply it directly to your source embeddings. -
🧱 Simple, explicit API
EmbeddingAdapter.from_registry(...)for registry-backed adaptersEmbeddingAdapter.from_pair(...)when you want to specify a source/target pair explicitly
-
🧪 Evaluation-friendly design
Adapters are trained with a documented setup (e.g. normalized inputs), and the library encourages you to evaluate them on your own data rather than treating them as magic. -
📊 Optional quality / OOD diagnostics
Utilities inembedding_adapters.qualityhelp you inspect when a given adapter is likely in- vs out-of-distribution for your inputs. This is useful for analysis, debugging, and research, and can inform more advanced workflows if you choose. -
🧰 Library, not a platform
No server to run and no database to adopt. Just Python code and models you can call inside your existing stack.
pip install embedding-adaptersSome adapters and source models may require a Hugging Face token:
- Create a token: https://huggingface.co/settings/tokens
- Either export it as an environment variable or pass it explicitly when creating an adapter.
Example: embed with sentence-transformers/all-MiniLM-L6-v2 locally and map into an OpenAI embedding space (for example, text-embedding-3-small).
pip install sentence-transformers embedding-adapters torch numpyimport os
import torch
import numpy as np
from sentence_transformers import SentenceTransformer
from embedding_adapters import EmbeddingAdapter
# 1) Compute source embeddings with a local / open-source model
src_model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
device = "cuda" if torch.cuda.is_available() else "cpu"
# 2) Load a pre-trained adapter from the registry
adapter = EmbeddingAdapter.from_registry(
source="sentence-transformers/all-MiniLM-L6-v2",
target="openai/text-embedding-3-small",
flavor="large",
device=device,
huggingface_token=os.environ['HUGGINGFACE_TOKEN']
)
# 3) Assemble texts for encoding
texts = [
"NASA announces discovery of Earth-like exoplanet.",
"Can you help me find my keys?"
]
# 4) Generate embeddings from source model ---
start = time.time()
src_embs = src_model.encode(
texts,
convert_to_numpy=True,
normalize_embeddings=True, # important: matches adapter training setup
)
# 5) Send the base model encodings to the adapter and generate the translated embs
translated_embs = adapter.encode_embeddings(src_embs) # (N, out_dim)
elapsed_ms = (time.time() - start) * 1000.0
print(f"[Device: {device}]")
print(f"Elapsed time for {len(texts)} embeddings in batch: {elapsed_ms:.2f} ms")
print(f"Average per embedding: {(elapsed_ms / len(texts)):.2f} ms")
print("Translated embeddings shape:", translated_embs.shape)
print("First 8 dims of first translated emb:", translated_embs[0][:8])The resulting translated_embs live in the target embedding space (same dimensionality, compatible geometry), so you can:
- Use them with an existing index built from real target embeddings, or
- Mix adapter-derived and native target embeddings in the same vector store (after validating on your workload).
You have:
- A corpus embedded with Provider A and stored in a vector DB
- A desire to experiment with or move toward a different model (for cost, latency, or privacy)
With a source → target adapter:
- Keep the corpus index as-is (e.g. original provider embeddings)
- Run new queries through your chosen source model, then through the adapter, then into the existing index
- Compare performance to direct target-model queries without re-embedding everything
You want to know how far a local or cheaper model can take you compared to a cloud provider’s embeddings.
- Start embedding queries with a local model
- Map into a known target space with an adapter
- Compare behavior and retrieval quality to “ground-truth” target embeddings on a subset of your data
This lets you quantify tradeoffs instead of guessing.
You prefer to treat “embedding space” as a long-lived contract and “embedding providers” as interchangeable.
Adapters make it possible to:
- Standardize on one or a few target spaces
- Plug in new source models over time via adapters, without constantly rebuilding indices and pipelines
On a subset of the AG News dataset:
| Setting | R@1 | R@5 | R@10 |
|---|---|---|---|
| OpenAI embeddings → OpenAI corpus | 1.00 | 1.00 | 1.00 |
| e5-base-v2 → adapter → OpenAI corpus | 0.86 | 1.00 | 1.00 |
- R@1: fraction of queries where the top retrieved document matches the top OpenAI baseline match.
- R@10: fraction where the baseline neighbor is within the top 10 results.
This does not mean the adapter is identical to the target model. It means:
- For this dataset, the adapter preserves much of the target model’s semantic neighborhood,
- While allowing queries to be embedded by a local model.
You should always evaluate on your own tasks, especially for domain-specific, safety-critical, or multilingual workloads.
Every adapter has a “comfort zone”: inputs similar to the data and distributions it was trained on. Beyond that, behavior may degrade.
The embedding_adapters.quality module provides utilities to estimate when a given source embedding looks in-distribution vs out-of-distribution (OOD) for a particular adapter. This can be useful for:
- Understanding when an adapter seems well-matched to your data
- Debugging surprising retrieval behavior
- Research and analysis of adapter behavior
Example:
# !pip -q install embedding-adapters sentence-transformers transformers torch numpy huggingface_hub
import os
import time
import torch
import numpy as np
from sentence_transformers import SentenceTransformer
from embedding_adapters import EmbeddingAdapter
from embedding_adapters.quality import interpret_quality
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
# 1) Load source encoder + adapter (adapter loads quality stats automatically if present)
src_model = SentenceTransformer(SOURCE_MODEL_ID, device=device)
adapter = EmbeddingAdapter.from_registry(
source="sentence-transformers/all-MiniLM-L6-v2",
target="openai/text-embedding-3-small",
flavor="large",
device=device,
# some adapters need a huggingface token to download
# huggingface_token=os.environ['HUGGINGFACE_TOKEN']
)
texts = [
"NASA announces discovery of Earth-like exoplanet.",
"How do I build a RAG pipeline?",
"Where can I get a hamburger near me?",
"asdfasdfasdfasdfasdfasdfasdfasdfasdfasdf", # junk text to see quality drop
]
# 2) Encode source embeddings
src_embs = src_model.encode(
texts,
convert_to_numpy=True,
normalize_embeddings=True,
)
# 3) Translate embeddings (target space)
t0 = time.time()
translated = adapter.encode_embeddings(src_embs)
t_ms = (time.time() - t0) * 1000.0
print("Source shape :", src_embs.shape)
print("Translated shape :", translated.shape if hasattr(translated, "shape") else (len(translated), len(translated[0])))
print(f"Translate time : {t_ms:.2f} ms")
# 4) Quality scoring on SOURCE embeddings (this does NOT require load_source_encoder)
# It uses the adapter's stored quality stats (npz) if present.
scores = adapter.score_source(src_embs)
# 5) Human-readable interpretation
print("\n--- Quality interpretation (source space) ---")
print(interpret_quality(texts, scores, space_label="source"))
# 6) Raw per-text scores (handy for debugging / programmatic use)
print("\n--- Raw scores ---")
# scores might be a numpy array or dict-like depending on your implementation
print(scores)The output gives you human-readable information about each text and its corresponding score, indicating whether the input looks typical for the adapter or unusual.
These signals are advisory: they are there to help you make informed decisions about how and where to use an adapter. The library does not prescribe or implement any particular policy on top of them.
embedding-adapters is deliberately not a vector database or a full search stack. It is designed to sit alongside tools you may already use, such as:
- Chroma, Qdrant, Pinecone, Weaviate, pgvector, etc.
- Cloud embedding providers (OpenAI and others)
- Local embedding models from Hugging Face or other sources
Some platforms implement their own internal adapters or regression layers for queries within a single ecosystem. embedding-adapters is different in that it:
- Focuses on general model-to-model translation, not just corpus-specific query transforms
- Is vendor-agnostic and can be used with whichever vector store or infrastructure you prefer
- Treats adapters themselves as first-class loadable models, rather than hiding them behind a larger hosted platform
Think of it as a low-level tool in the stack: if embeddings are your “language of meaning,” this library provides the translators.
The embedding-adapters CLI lets you discover adapters, generate embeddings,
translate between embedding spaces, and optionally score quality — all from
the command line.
After installing:
pip install embedding-adaptersYou will have the embedding-adapters command available.
embedding-adapters embed \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-small \
--flavor large \
--text "Where can I get a hamburger?"On first run, models and adapters will be downloaded and cached locally. Subsequent runs reuse the cache automatically.
Repeat --text:
embedding-adapters embed \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-small \
--text "hello" \
--text "world"Or pipe from stdin:
printf "hello\nworld\n" | embedding-adapters embed \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-smallQuality scoring is enabled by default when available. To skip it:
embedding-adapters embed --no-quality \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-small \
--text "hello world"embedding-adapters embed --ndjson \
--source sentence-transformers/all-MiniLM-L6-v2 \
--target openai/text-embedding-3-small \
--text "hello" \
--text "world"Each line will contain:
{
"text": "...",
"embedding": [...],
"confidence": 0.94
}embedding-adapters listOnly show paid / pro adapters:
embedding-adapters list --pro-onlyembedding-adapters registryembedding-adapters info emb_adapter_minilm_to_openai_text-embedding-3-large_v1embedding-adapters pathsembedding-adapters news
embedding-adapters docs
embedding-adapters donateembedding-adapters version- Models and adapters are cached using Hugging Face caching.
- GPU is used automatically when available.
- No OpenAI or Gemini API keys are required — everything runs locally.
- Adapters translate embeddings between model spaces without re-encoding text.
It is:
- A Python library for loading and applying pre-trained translational models (“adapters”) between embedding spaces.
- A small set of diagnostic utilities to help you understand when an adapter is likely to behave well on your data.
- A way to reduce friction when:
- experimenting with new models,
- migrating between providers, or
- running local models against an existing index.
It is not (today):
- A vector database or retrieval engine.
- A hosted routing platform or managed service.
- A guarantee of perfect equivalence to any proprietary embedding model or provider.
Higher-level concerns like routing policies, caching, retries, or safety rules belong in your surrounding infrastructure or future tools built on top of this layer.
Areas we are interested in exploring over time:
- More source → target adapter pairs, including domain-specific spaces
- Richer diagnostics and evaluation tools around adapters
- Example integrations with popular vector databases and frameworks
- Improved models with more expansive training sets
- More domain specific adapters
- Hosted endpoints for adapters so you don’t have to ship or manage weights yourself
The guiding principle is to stay small, explicit, and composable. Adapters should be easy to understand, easy to evaluate, and easy to slot into existing systems.
If you:
- Find a bug
- Want to propose a new adapter pair
- Have ideas for better evaluation or diagnostics
…please open an issue or pull request. Critical, thoughtful feedback is welcome — it helps make the library more useful for everyone.