Gen.jl wrapper for the Redner differentiable renderer
The GenRedner module currently exports a one function:
depth_renderer = GenRedner.get_depth_renderer(;num_samples=1, print_timing=false)where num_samples is the number of samples that the renderer will user internally for rendering and for its internal gradient estimation.
The returned value is a generative function of concrete type GenPyTorch.TorchGenerativeFunction.
The returned generative function has the following type signature:
Arguments:
-
verticesis anx 3 matrix of floating point values, wherenis the number of vertices in the mesh. Each row gives the x, y, and z coordinates of a mesh vertex in the camera's 3D coordinate frame (see below for this frame). -
indicesis anx 3 matrix of integers, wherenis the number of triangle faces in the mesh. Each row gives the indices of the three vertices that comprise the face. The indices of vertices face start from 1. -
instrinsicsis a length-4 vector of floating point values of the form[fx, fy, cx, cy]wherefxis the horizontal focal length of the camera model,fyis the vertical focal length, andcxandcygive the principle points. -
dimsis a length-2 vector of integers of the form[width, height]wherewidthis the number of rows in the resulting depth image andheightis the number of columns.
The return value is a 3D array of floating point values points with dimension height x width x 3, where points[:,:,1] contains the x-coordinates in the camera's 3D coordinate frame, points[:,:,2] contains the y-coordinates, and points[:,:,3] contains the z-coordinates (i.e. the depth image). The first row of the matrix has the highest y-coordinate (corresponding to the bottom row of pixels in the image).
Like all generative functions, the returned depth rendering generative function supports both forward execution (via Gen.simulate) and computing gradients with respect to vertices and intrinsics (via Gen.choice_gradients or Gen.accumulate_param_gradients!). Note that this generative function has no trainable parameters of its own. The generative function is intended to be called from within a generative model of depth images. The generative funciton internally calls Redner for both forward rendering and for gradient computation.
The input vertices and the output point cloud both are in the camera's 3D coordinate frame. This coordinate frame is the same as the 3D camera coordinate frame used by OpenCV (the black coorinate frame in the image below):
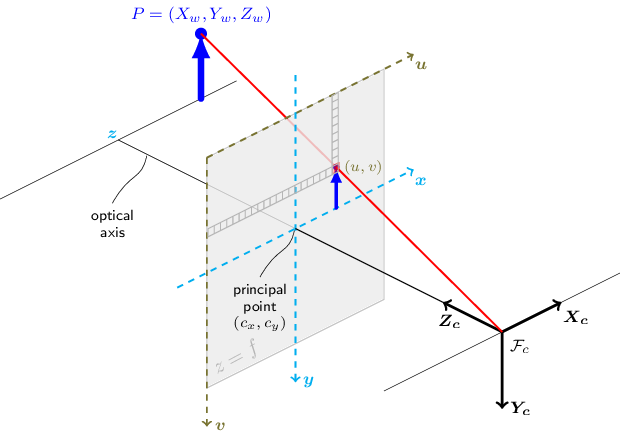
-
Add this package to your Julia environment (e.g. using
add https://github.com/probcomp/GenRedner.jlfrom the Julia package manager). -
Create a Python environment (e.g. using
virtualenv) that has thetorchPython package installed, and eitherredner-gpuorrednerPython packages installed (see Redner for more details about setting up the Python environment). -
Build the
PyCallpackage so that it points to the Python environment you created. See the GenPyTorch documentation and the PyCall documentation for more details.
See example.jl for a script that sets up an example scene consisting of a background square and two foreground triangles, and renders the point cloud using Redner, and also fits the vertices of the scene to the observed point cloud using stochastic gradient descent, using a from
The Redner renderer computes the depth of a pixel by averaging the depth of continuous points inside the pixel.
For pixels on edges of sillhouettes, the depth values are therefore averages of the foreground and background depths.
Also, the Redner renderer is stochastic.
For depth images, it estimates the depth value for a pixel by sampling points inside the pixel.
Below are three depth images (left) produced by running the depth renderer on the same scene three times, and the point clouds produced by the renderer, with num_samples=2.
The camera coordinate frame is shown (red is X axis, green is Y axis, and blue is Z axis):

Note that when num_samples=1, there are no intermediate depth values. Each pixel is either the foreground or background planes:
Below is an animation of stochastic gradient ascent for MAP estimation:
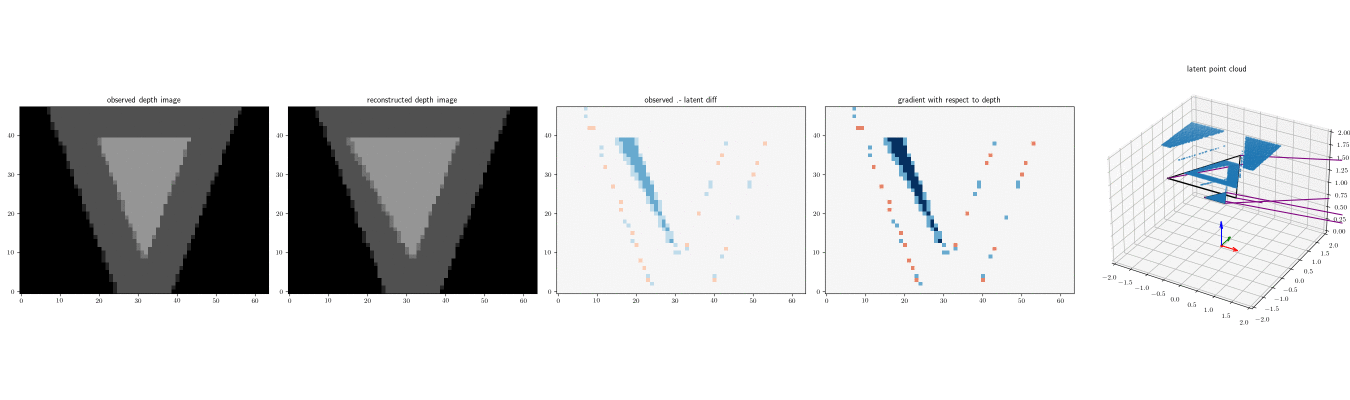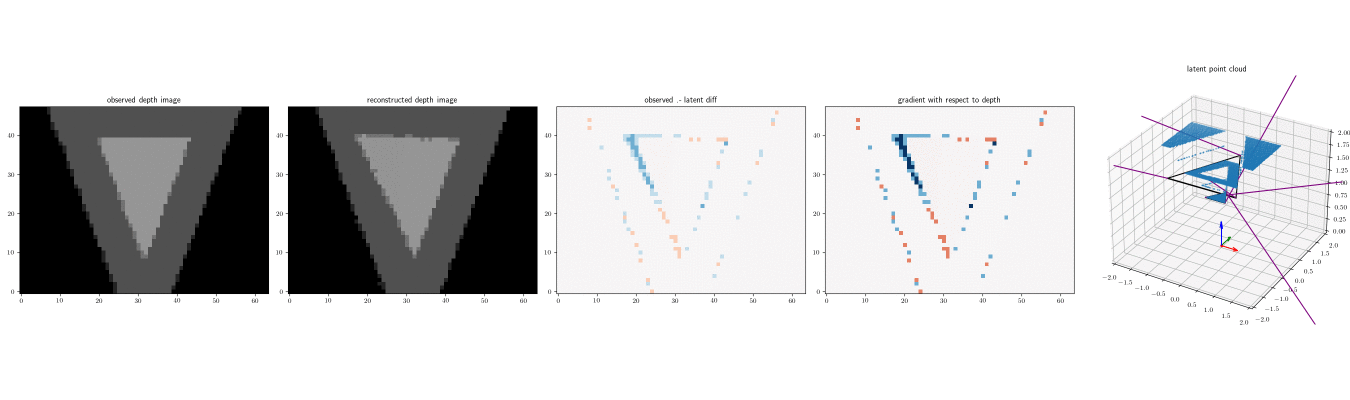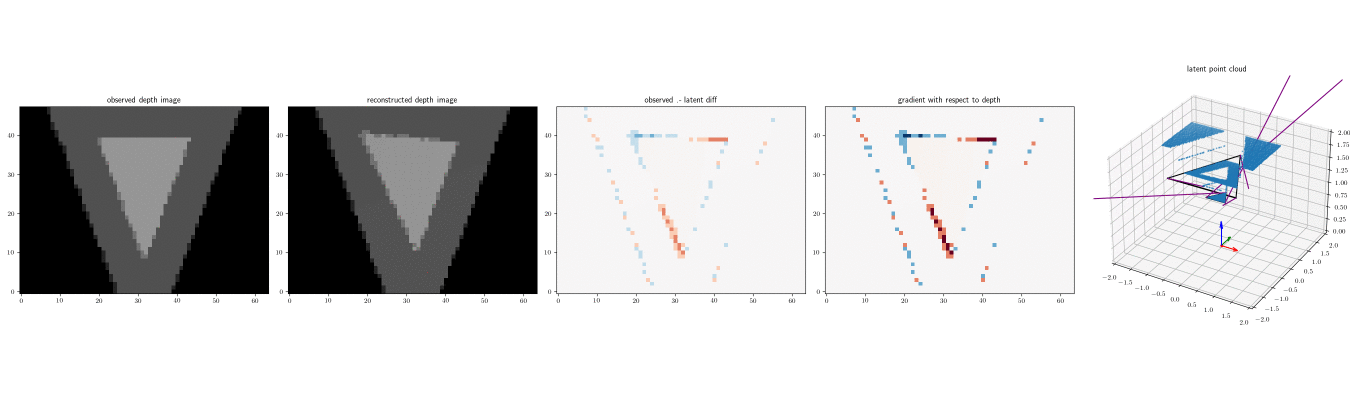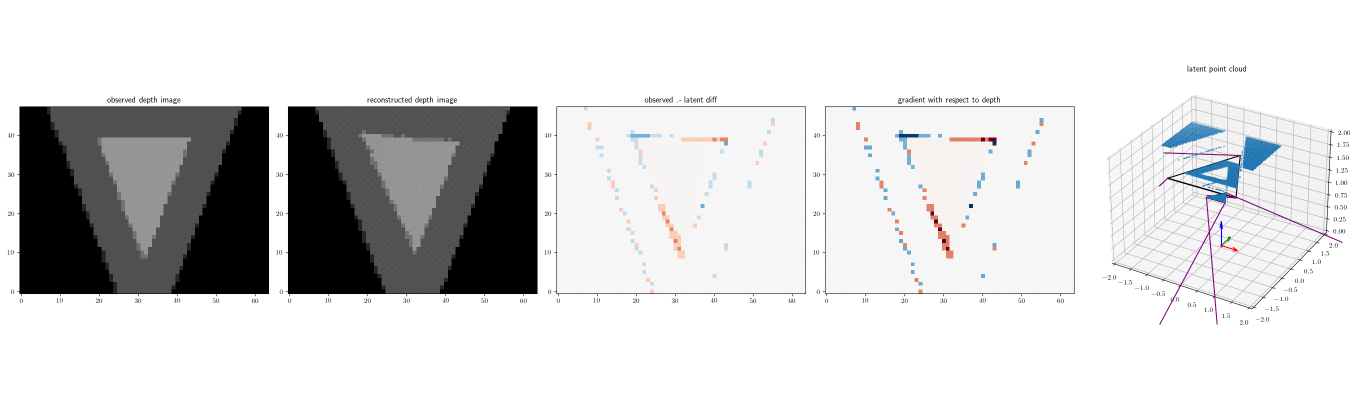
The Redner differentiable renderer produces many more output channels, including various types of RGB rendering (including photorealistic rendering), and object masks. This wrapper will be extended with additional generative functions that wrap these other rendering capabilities in the future.