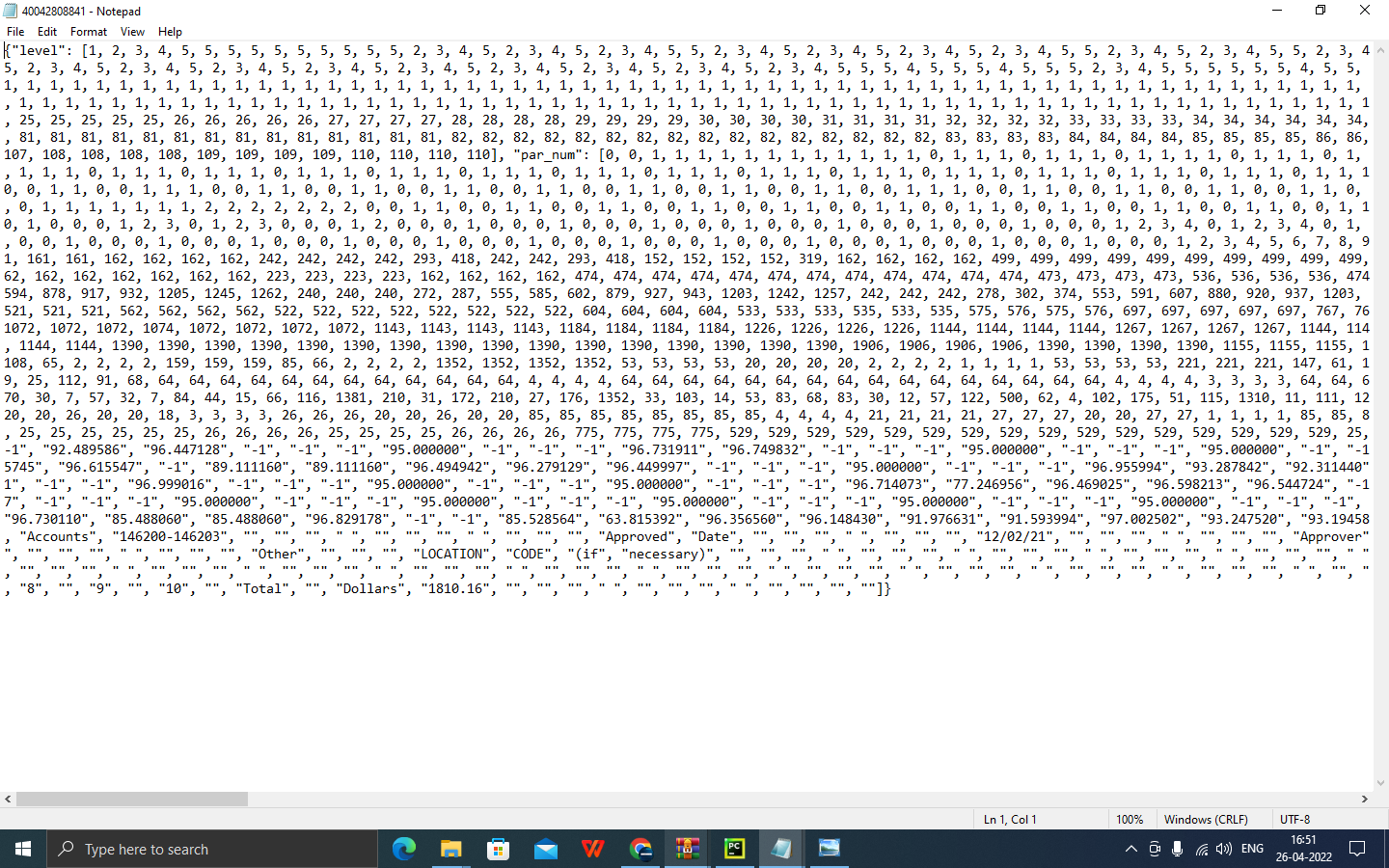
Getting JSON output for the image or file loaded in ocr engine I recommend to use pycharm for this pytesseract Create new project ...now open python interpreter ,in pycharm settings and select add packages now search for opencv-python and pytesseract select install.
If you are using Windows OS, I recommend you to install TESSERACT.exe in your local disk first. use this link for tesseract installation .. Link:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v5.0.1.20220118.exe
Save or copy the location where yout install this tesseract file .I have installed in C:\Users\HARIHARAN\AppData\Local\Programs\Tesseract-OCR\tesseract. Copy this path you need to specify this in the main.py file. use \ instead of \ for specifying the location of installation otherwise pytesseract will not be initialized
after this installation open your python ide's terminal or command prompt Now install pytesseract using pip again this is required because windows os requires 2 way installation . If you use linux operating system and others you can just install with pip or conda forge.
Now code your ocr model for text detection , now save your code and paste the image file which has text in it to be extracted. I need to extract text from a file . So iam pasting the file in the path where my code is saved. Once you pasted the file you can find the file in project window in the left pane. Now run the code. the json output will be returned in the main window's console below the code. And a new window will be opened with boundary boxes, around the text and below the boundary boxes the text recognized will also be shown.
Code by : Hariharan M 2011.hariharan@gmail.com
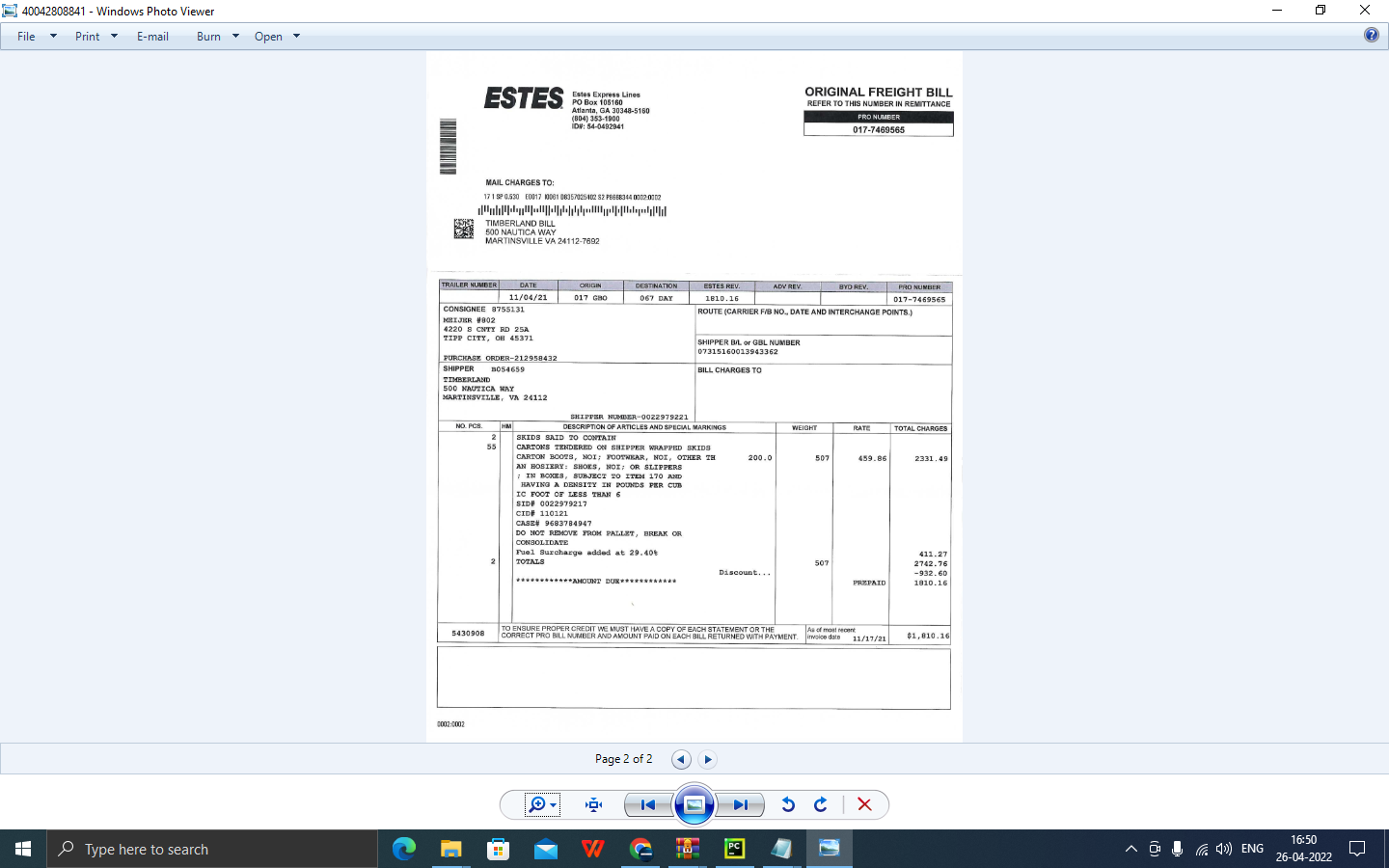
OUTPUT for file 40042808841.tif
40042808841.txt