2 NCCL all_reduces per step for large models on multiNode training #61353
Description
🐛 Bug
When using large models with DDP, we witness two NCCL all reduces per iteration and have no ability to increase the first bucket size. This is due to reducer.hpp KDefaultFirstBucketBytes being a const expr int that cannot be modified through the python api, yet it is exposed as an attribute of torch.distributed.
The value is defined here:
The bucket size is set here:
https://github.com/pytorch/pytorch/blob/master/torch/csrc/distributed/c10d/reducer.cpp#L1649
There is a Python API exposure, however since the value is a constexpr it is defined at compile time which would make changing it through Python at Runtime problematic. Changing the value through the Python does not currently work.
Python API:
pytorch/torch/csrc/distributed/c10d/init.cpp
Line 1623 in 43fb39c
The user should be able to increase this KDefaultFirstBucketBytes value through the python API.
Reproduction Steps (Should Work in any pytorch container from 21.05 and onwards):
- tar -xvzf ddp_overlap.tgz
- cp -r ddp_overlap /opt/
- cd /opt/ddp_overlap
- bash run.sh
Repro Scripts:
ddp_overlap.zip
Example of issue:
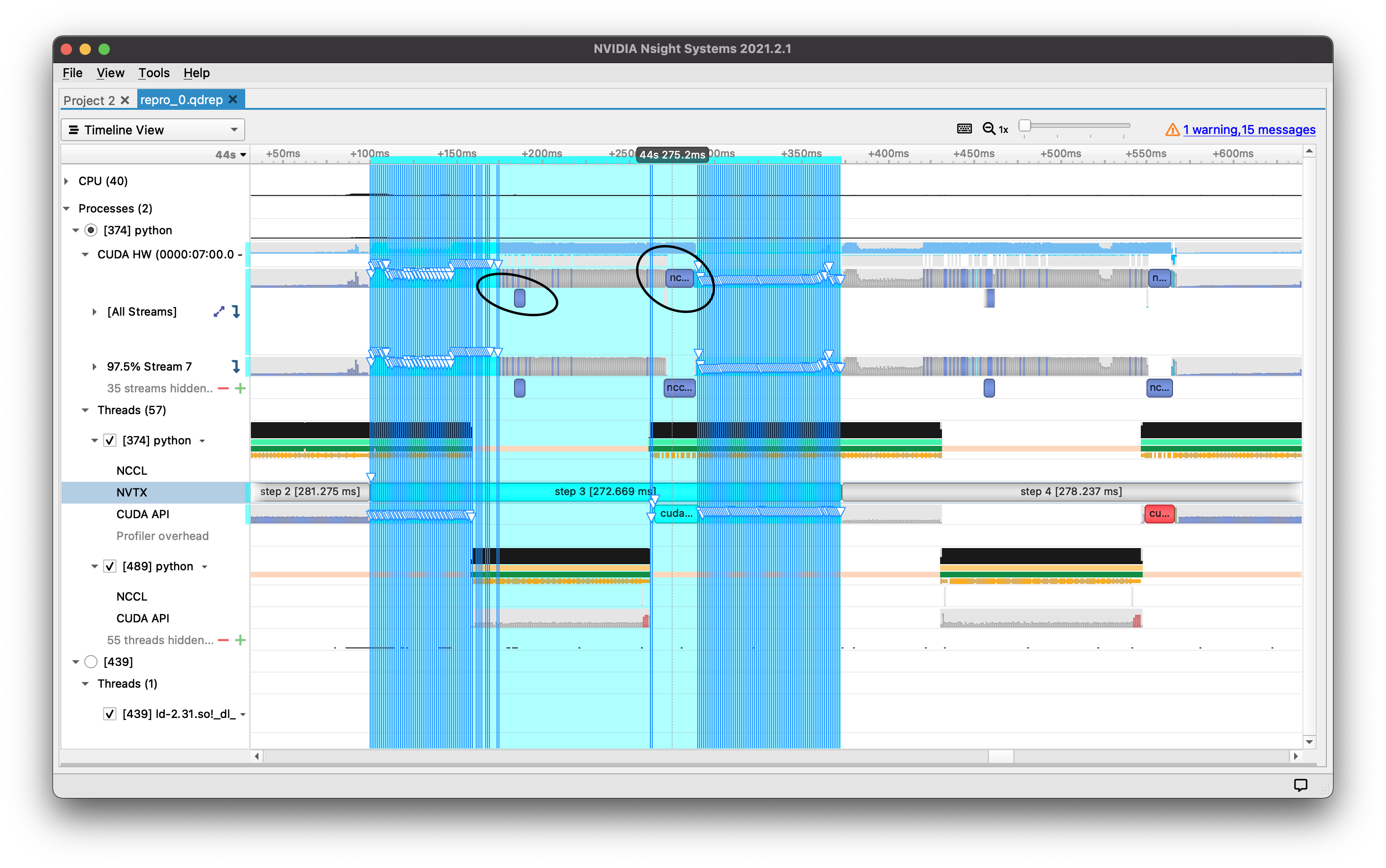
This issue persists if the KDefaultFirstBucketBytes value is edited through the Python binding showing that it does not work. In contrast, changing the hardcoded value of the constexpr defined in reducer.hpp manually and recompiling pytorch does remove the 2 all_reduce calls issue. This value should be properly defined in the backend of PyTorch such that it can be edited by a user in the PyTorch Python API without having to recompile for situations such as this with very large models.
cc @ezyang @gchanan @zou3519 @bdhirsh @jbschlosser @anjali411 @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @agolynski @SciPioneer @H-Huang @mrzzd @cbalioglu @gcramer23