AOTInductor dynamic shape #109012
AOTInductor dynamic shape #109012
Conversation
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/109012
Note: Links to docs will display an error until the docs builds have been completed. ✅ No FailuresAs of commit 0f6853b with merge base 025d1a1 ( This comment was automatically generated by Dr. CI and updates every 15 minutes. |

|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
bb538c0 to
e2083bc
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
Summary: This PR adds dynamic-shape support for AOTInductor Differential Revision: D49100472
e2083bc to
bfb55cf
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
bfb55cf to
64287a7
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
Summary: This PR adds dynamic-shape support for AOTInductor Differential Revision: D49100472
64287a7 to
1003ba8
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
1 similar comment
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
Summary: This PR adds dynamic-shape support for AOTInductor Differential Revision: D49100472
1003ba8 to
89223bb
Compare
There was a problem hiding this comment.
Thanks @chenyang78 ! Left some comments, mainly some clarification questions. It would be great if you could help summarize your changes in the PR description.
torch/_inductor/codegen/wrapper.py
Outdated
|
|
||
| return ", ".join(new_args) | ||
|
|
||
| def generate_default_grid(self, name, grid, cuda=True): |
There was a problem hiding this comment.
Is this cuda arg used anywhere?
There was a problem hiding this comment.
Seems unnecessary since the cpu backend doesn't need to generate grid
| return grid | ||
| assert isinstance(grid, list), f"expected {grid=} to be a list" | ||
| grid = [e.inner_expr if isinstance(e, SymbolicCallArg) else e for e in grid] | ||
| grid_fn = default_grid(*grid) |
There was a problem hiding this comment.
What is default_grid? I cannot find it in the pytorch repo.
There was a problem hiding this comment.
It's from from ..triton_heuristics import grid as default_grid
torch/_inductor/codegen/wrapper.py
Outdated
| ) | ||
| stack.enter_context(self.wrapper_call.indent()) | ||
|
|
||
| def generate_default_grid(self, name, grid_args): |
There was a problem hiding this comment.
nit: Add more comments to describe what this function does, and the args. Also add type hints.
There was a problem hiding this comment.
Will do. Thanks.
| @dataclasses.dataclass | ||
| class SymbolicCallArg: | ||
| inner: Any | ||
| inner_expr: sympy.Expr |
There was a problem hiding this comment.
Left some nits. LGTM overall.
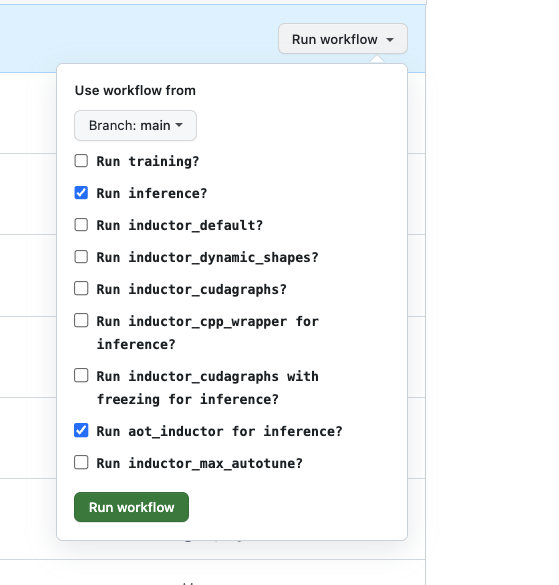
Currently AOTInductor on the OSS benchmarks are not a part of the CI yet. I have a pending PR, #108419, but it won't be merged soon given the recent CI infra instability. So can you manually trigger a run at https://github.com/pytorch/pytorch/actions/workflows/inductor-perf-test-nightly.yml?
You will need to select the options like in the screenshot,

Unfortunately the Branch selection does not work with a PR from your forked repo. You can create a mirror PR on a pytorch branch in order to do the testing. Let me know if you need more help on the instructions.
| for example_inputs, example_outputs in zip( | ||
| list_example_inputs, list_example_outputs | ||
| ): | ||
| output_tensors = [torch.empty_like(output) for output in example_outputs] |
There was a problem hiding this comment.
In the prod scenario, do we allocate a list of tensors with the max batch size and reuse those? If yes, we need to test that here.
There was a problem hiding this comment.
No, we don't re-use output tensors. Instead, we allocate output tensors for each inference run and return these tensors to the caller of the forward function.
| return grid | ||
| assert isinstance(grid, list), f"expected {grid=} to be a list" | ||
| grid = [e.inner_expr if isinstance(e, SymbolicCallArg) else e for e in grid] | ||
| grid_fn = default_grid(*grid) |
There was a problem hiding this comment.
It's from from ..triton_heuristics import grid as default_grid
torch/_inductor/codegen/wrapper.py
Outdated
|
|
||
| return ", ".join(new_args) | ||
|
|
||
| def generate_default_grid(self, name, grid, cuda=True): |
There was a problem hiding this comment.
Seems unnecessary since the cpu backend doesn't need to generate grid
| size_t num_inputs, | ||
| AOTInductorTensorHandle outputs_handle, | ||
| size_t num_outputs, | ||
| AOTInductorParamShape* output_shapes, |
There was a problem hiding this comment.
Needs to revisit for ABI compatibility, but ok for now.
89223bb to
a7158ba
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
Summary: This PR adds dynamic-shape support for AOTInductor Reviewed By: khabinov Differential Revision: D49100472
a7158ba to
9cf331c
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
Running it: https://github.com/pytorch/pytorch/actions/runs/6170063555 Hopefully I was doing it right. Thanks. |
Given the long task queueing time, I ran this PR locally to verify. I haven't checked every model, but the results look good to me. I am ok with landing it. |
Summary: This PR adds dynamic-shape support for AOTInductor Reviewed By: frank-wei, khabinov Differential Revision: D49100472
9cf331c to
768090f
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
768090f to
0f6853b
Compare
|
This pull request was exported from Phabricator. Differential Revision: D49100472 |
|
@pytorchbot merge |
Merge failedReason: This PR has internal changes and must be landed via Phabricator Details for Dev Infra teamRaised by workflow job |
|
@pytorchbot merge (Initiating merge automatically since Phabricator Diff has merged) |
Merge startedYour change will be merged once all checks pass (ETA 0-4 Hours). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
Summary: This PR adds dynamic-shape support for AOTInductor
On the runtime/interface side, we added two structs, StaticDimInfo
and DynamicDimInfo, to hold values for static and dynamic dimensions,
respectively. Dynamic dimensions are tracked by an unordered map field
defined in AOTInductorModelBase. At inference time, the inference run
method will assign the current real dimensional value to each dynamic
dimension before executing any kernel.
On the CUDA wrapper codegen side, we generate dynamic symbols
appropriately for shape computations. We simulate kernel launch grids
in the C++ land by re-using the grid functions from the Python world.
The returned grid configs, which may contain symbolic expressions,
are printed out in their C++ forms via the CppPrinter. Note that
when dynamic shapes are involved, we have to compute grid configs
for each kernel at runtime in the same way as we do for launching
the corresponding Triton kernel. Otherwise, we may end up with
memory-access failures or mis-computations caused by invalid indices
for fetching or storing data in device memory.
Differential Revision: D49100472
cc @voznesenskym @penguinwu @EikanWang @jgong5 @Guobing-Chen @XiaobingSuper @zhuhaozhe @blzheng @Xia-Weiwen @wenzhe-nrv @jiayisunx @peterbell10 @ipiszy @ngimel @yf225 @kadeng @muchulee8 @aakhundov