Fix typo in tools/test_history.py #53514
Closed
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
💊 CI failures summary and remediationsAs of commit 33ab519 (more details on the Dr. CI page):
1 failure not recognized by patterns:
ci.pytorch.org: 1 failedThis comment was automatically generated by Dr. CI (expand for details).Follow this link to opt-out of these comments for your Pull Requests.Please report bugs/suggestions to the (internal) Dr. CI Users group. |

There was a problem hiding this comment.
@samestep has imported this pull request. If you are a Facebook employee, you can view this diff on Phabricator.
janeyx99
approved these changes
Mar 8, 2021
xuzhao9
approved these changes
Mar 8, 2021
siva1007
added a commit
to siva1007/pytorch
that referenced
this pull request
Mar 11, 2021
* Automated submodule update: FBGEMM (#53478)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53478
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: https://github.com/pytorch/FBGEMM/commit/c3612e67ee2e9c477c990696f6cdc8dcfe0e4a21
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53087
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jianyuh
Differential Revision: D26744074
Pulled By: jspark1105
fbshipit-source-id: c16de118a5befb9dae9e256a5796993cdcfb714b
* Extract TensorPipeAgent's collectNames to be a standalone utility function (#53202)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53202
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26791525
Pulled By: mrshenli
fbshipit-source-id: 8234c4d0350a5cd61926dce4ecc9e918960d30d2
* Use Store collect and verify names in all RPC agents (#53209)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53209
closes #40048
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26791524
Pulled By: mrshenli
fbshipit-source-id: fc75589f9707014334fcfae6f05af3c04217783b
* [NNC] Implementation for aten::cat without conditionals. (#53128)
Summary:
This PR adds an implementation for `aten::cat` in NNC without any conditionals. This version is not enabled by default.
Here is the performance of some micro benchmarks with and without conditionals. There is up to 50% improvement in performance without conditionals for some of the shapes.
aten::cat implementation in NNC **with** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 5.44 us, SOL 0.26 GB/s, algorithmic 0.51 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.75 us, SOL 1.05 GB/s, algorithmic 2.10 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.87 us, SOL 4.05 GB/s, algorithmic 8.11 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 14.52 us, SOL 8.31 GB/s, algorithmic 16.62 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 9.58 us, SOL 6.84 GB/s, algorithmic 13.68 GB/s
```
aten::cat implementation in NNC **without** conditionals
```
$ python -m benchmarks.tensorexpr --device cpu --mode fwd --jit_mode trace --cpu_fusion --cat_wo_conditionals concat
pt: concat2d2input_fwd_cpu_1_160_1_14_1: 4.67 us, SOL 0.30 GB/s, algorithmic 0.60 GB/s
pt: concat2d2input_fwd_cpu_1_580_1_174_1: 5.65 us, SOL 1.07 GB/s, algorithmic 2.14 GB/s
pt: concat2d2input_fwd_cpu_20_160_20_14_1: 6.10 us, SOL 4.56 GB/s, algorithmic 9.12 GB/s
pt: concat2d2input_fwd_cpu_20_580_20_174_1: 7.44 us, SOL 16.22 GB/s, algorithmic 32.44 GB/s
pt: concat2d2input_fwd_cpu_8_512_8_512_1: 6.46 us, SOL 10.14 GB/s, algorithmic 20.29 GB/s
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53128
Reviewed By: bertmaher
Differential Revision: D26758613
Pulled By: navahgar
fbshipit-source-id: 00f56b7da630b42bc6e7ddd4444bae0cf3a5780a
* Modify tests to use assertWarnsOnceRegex instead of maybeWarnsRegex (#52387)
Summary:
Related to https://github.com/pytorch/pytorch/issues/50006
Follow on for https://github.com/pytorch/pytorch/issues/48560 to ensure TORCH_WARN_ONCE warnings are caught. Most of this is straight-forward find-and-replace, but I did find one place where the TORCH_WARN_ONCE warning was not wrapped into a python warning.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52387
Reviewed By: albanD
Differential Revision: D26773387
Pulled By: mruberry
fbshipit-source-id: 5be7efbc8ab4a32ec8437c9c45f3b6c3c328f5dd
* [reland] Add OpInfo for `bitwise_not` and make ROCM and CUDA OpInfo tests consistent (#53181)
Summary:
Reference: https://github.com/pytorch/pytorch/issues/42515
This PR also enables the OpInfo tests on ROCM to check the same dtypes that of CUDA.
Note: Reland https://github.com/pytorch/pytorch/issues/51944
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53181
Reviewed By: zhangguanheng66
Differential Revision: D26811466
Pulled By: mruberry
fbshipit-source-id: 8434a7515d83ed859db1b2f916fad81a9deaeb9b
* [AutoAccept][Codemod][FBSourceClangFormatLinter] Daily `arc lint --take CLANGFORMAT`
Reviewed By: zertosh
Differential Revision: D26879724
fbshipit-source-id: 0e2dd4c5f7ba96e97e7cbc078184aed2a034ad2c
* [caffe2] Fix DBFileReader (#53498)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53498
This code depended on `Blobs()` being returned in sorted order:
https://www.internalfb.com/intern/diffusion/FBS/browsefile/master/fbcode/caffe2/caffe2/python/db_file_reader.py?commit=472774e7f507e124392491800d9654e01269cbaf&lines=89-91
But D26504408 (https://github.com/pytorch/pytorch/commit/69bb0e028596d481cda38a0f49bcb5965fab4293) changed the underlying storage to a hashmap, so now the blobs are returned in arbitrary order (Note that `Blobs()` returns also non-local blobs, and for those there was already no guarantee of ordering).
So we need to explicitly sort the result.
Test Plan:
```
$ buck test dper3/dper3/toolkit/tests:lime_test
$ buck test //dper3/dper3/toolkit/tests:model_insight_test
```
Pass after this diff.
Differential Revision: D26879502
fbshipit-source-id: d76113f8780544af1d97ec0a818fb21cc767f2bf
* [FX] change dynamic control flow example to a *more* dynamic version (#53250)
Summary:
This is a more fundamental example, as we may support some amount of shape specialization in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53250
Reviewed By: navahgar
Differential Revision: D26841272
Pulled By: Chillee
fbshipit-source-id: 027c719afafc03828a657e40859cbfbf135e05c9
* [FX] Fix default to align with documentation in `fuser.py` (#53457)
Summary:
Currently it says it does a deepcopy by default, but that's not true.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53457
Reviewed By: navahgar
Differential Revision: D26876781
Pulled By: Chillee
fbshipit-source-id: 26bcf76a0c7052d3577f217e79545480c9118a4e
* Add missing attr in LazyModuleMixin doc (#53363)
Summary:
To fix some rendering issues.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53363
Reviewed By: izdeby
Differential Revision: D26884560
Pulled By: albanD
fbshipit-source-id: fedc9c9972a6c68f311c6aafcbb33a3a881bbcd2
* Fix set_device_map docs (#53508)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53508
closes #53501
Differential Revision: D26885263
Test Plan: Imported from OSS
Reviewed By: H-Huang
Pulled By: mrshenli
fbshipit-source-id: dd0493e6f179d93b518af8f082399cacb1c7cba6
* Automated submodule update: tensorpipe (#53504)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: https://github.com/pytorch/tensorpipe/commit/46949a8ca310b99d8f340af0ed26808dd6290a0c
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53504
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26883701
fbshipit-source-id: 9e132a1389ac9cee9507c5600668af1afbb26efd
* Disable failing distributed test (#53527)
Summary:
See https://github.com/pytorch/pytorch/issues/53526. We're disabling the test temporarily until we can figure out what's going on (since it's unclear what needs to be reverted).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53527
Reviewed By: zhangguanheng66
Differential Revision: D26888037
Pulled By: samestep
fbshipit-source-id: f21a2d665c13181ed3c8815e352770b2f26cdb84
* [iOS GPU][BE][1/n] - Remove unused headers + improve error message (#53428)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53428
Start to do some code clean up work.
ghstack-source-id: 123038070
Test Plan:
- CircleCI
- Sandcastle CI
- AIBench
Reviewed By: SS-JIA, AshkanAliabadi
Differential Revision: D26681115
fbshipit-source-id: b1b7cfc6543b73928f517cd52e94a2664ee0bd21
* Fix typo in tools/test_history.py (#53514)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53514
Test Plan:
```
tools/test_history.py columns --ref=0ca029b22d17d236d34bcecad44b94b35b1af4bb test_common_errors pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_test1
```
Reviewed By: janeyx99
Differential Revision: D26886385
Pulled By: samestep
fbshipit-source-id: d3d79282e535707616d992ab8cf6216dfb777639
* .circleci: Restore docker builds for scheduled workflows (#53412)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53412
Docker builds for scheduled workflows still need to happen within the
regular build workflow since new docker image builds are actually only
done within the `build` workflow
A follow up to #52693
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D26890300
Pulled By: seemethere
fbshipit-source-id: d649bfca5186a89bb5213865f1f5738b809d4d38
* Add missing tensor header (#53489)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53489
It appears that D26675801 (https://github.com/pytorch/pytorch/commit/1fe6a6507e6a38534f0dc6265fd44cd26c80e5b0) broke Glow builds (and probably other instals) with the inclusion of the python_arg_parser include. That dep lives in a directory of its own and was not included in the setup.py.
Test Plan: OSS tests should catch this.
Reviewed By: ngimel
Differential Revision: D26878180
fbshipit-source-id: 70981340226a9681bb9d5420db56abba75e7f0a5
* fix broken quantization_test in operator_benchmark (#53153)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53153
This diff is a fix for quantization_test in operator_benchmark, which is broken because of removing the py_module for learnable fake_quantization.
ghstack-source-id: 123103477
Test Plan: `buck run mode/opt //caffe2/benchmarks/operator_benchmark/pt:quantization_test`
Reviewed By: z-a-f
Differential Revision: D26764881
fbshipit-source-id: 8d40c6eb5e7090ca65f48982c837f7dc87d14378
* [PyTorch] Enable explicit ATen level sources for lite interpreter (#52769)
Summary:
Enable partial explicit Aten level sources list for lite interpreter. More aten level source list will be added.
x86:
`SELECTED_OP_LIST=/Users/chenlai/Documents/pytorch/experiemnt/deeplabv3_scripted.yaml BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86`
libpytorch_jni_lite.so -- 3.8 MB
armeabi-v7a
`SELECTED_OP_LIST=/Users/chenlai/Documents/pytorch/experiemnt/deeplabv3_scripted.yaml BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh armeabi-v7a`
libpytorch_jni_lite.so -- 2.8 MB
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52769
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D26717268
Pulled By: cccclai
fbshipit-source-id: 208300f198071bd6751f76ff4bc24c7c9312d337
* [PyTorch] Move non-template part of TensorImpl::Resize to cpp (#53388)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53388
Most of this method did not depend on the template parameter. No need to include it in the .h file or duplicate it in the generated code.
ghstack-source-id: 123211590
Test Plan: Existing CI should cover this
Reviewed By: smessmer
Differential Revision: D26851985
fbshipit-source-id: 115e00fa3fde547c4c0009f2679d4b1e9bdda5df
* [PyTorch] Don't copy vector arguments to caffe2::Tensor::Resize (#53389)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53389
Resize was written to take arguments by value, which was
totally fine if they were ArrayRef or a series of integers, but not so
fine if they're std::vector.
ghstack-source-id: 123212128
Test Plan:
Existing CI should make sure it builds
Inspected assembly for ios_caffe.cc and saw no more vector copy before
calling Resize
Reviewed By: smessmer
Differential Revision: D26852105
fbshipit-source-id: 9c3b9549d50d32923b532bbc60d0246e2c2b5fc7
* feature_segmented_histogram_binning_calibration
Summary: We implement a hierarchical fine grained binning structure, with the top level corresponding to different feature segments and bottom level corresponding to different range of ECTR. The model is designed to be general enough to perform segmented calibration on any useful feature
Test Plan:
buck test dper3/dper3/modules/calibration/tests:calibration_test -- test_histogram_binning_calibration_by_feature
buck test dper3/dper3_models/ads_ranking/model_impl/mtml/tests:mtml_lib_test -- test_multi_label_dependent_task_with_histogram_binning_calibration_by_feature
e2e test:
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_sparse_nn_histogram_binning_calibration_by_feature
buck test dper3/dper3_models/ads_ranking/tests:model_paradigm_e2e_tests -- test_mtml_with_dependent_task_histogram_binning_calibration_by_feature
All tests passed
Canary packages:
Backend -> aml.dper2.canary:e0cd05ac9b9e4797a94e930426d76d18
Frontend -> ads_dper3.canary:55819413dd0f4aa1a47362e7869f6b1f
Test FBL jobs:
**SparseNN**
ctr mbl feed
f255676727
inline cvr
f255677216
**MTML regular task**
offsite cvr
f255676719
**MTML dependent task**
mobile cvr
f255677551
**DSNN for AI models**
ai oc
f255730905
**MIMO for both AI DSNN part and AF SNN part**
mimo ig
f255683062
Reviewed By: zhongyx12
Differential Revision: D25043060
fbshipit-source-id: 8237cad41db66a09412beb301bc45231e1444d6b
* [PyTorch][CI] Enable building test_lite_interpreter_runtime unittest in CI (macos) (#52566)
Summary:
## Summary
1. Enable building libtorch (lite) in CI (macos)
2. Run `test_lite_interpreter_runtime` unittest in CI (macos)
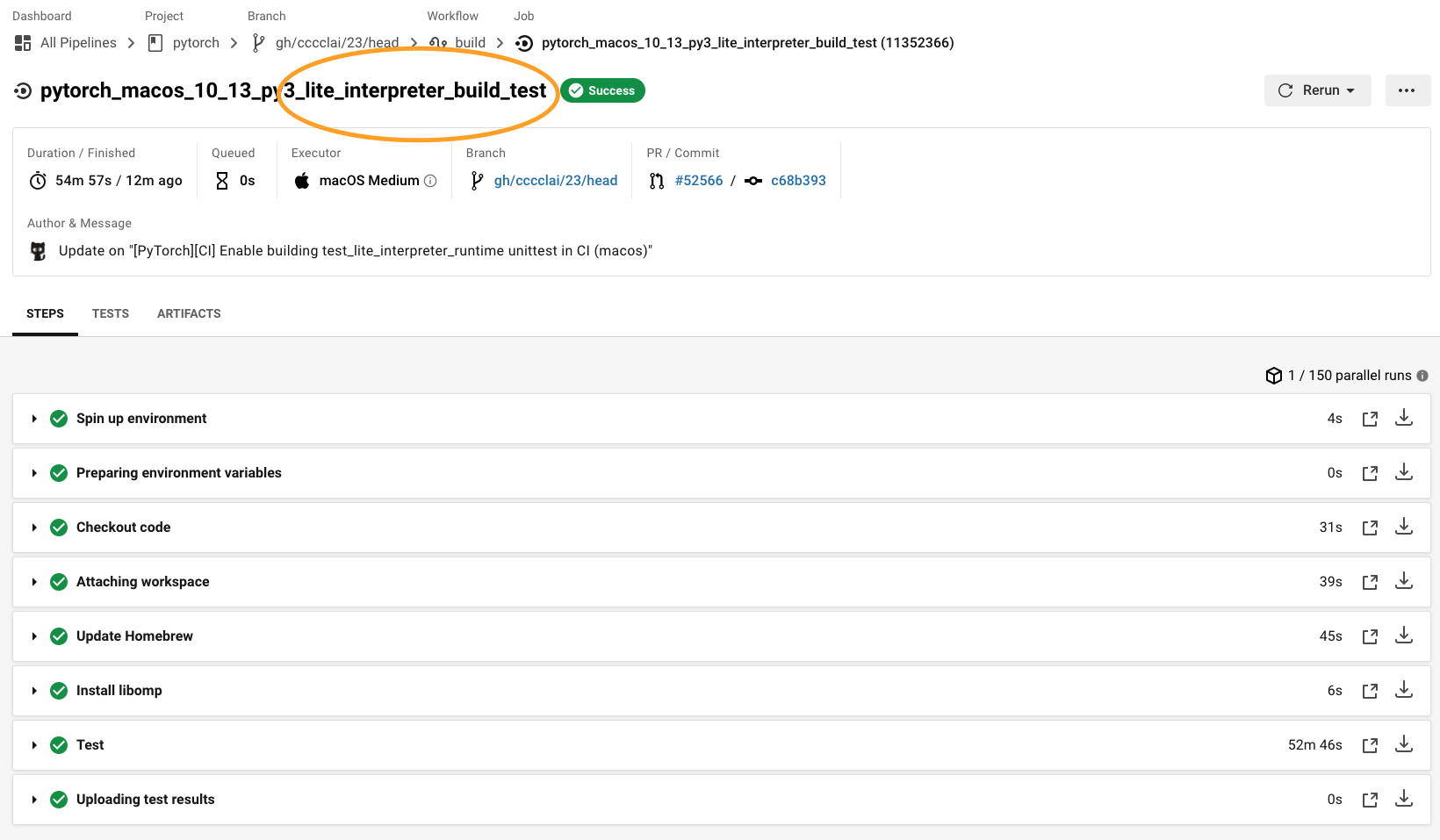
{F467163464}
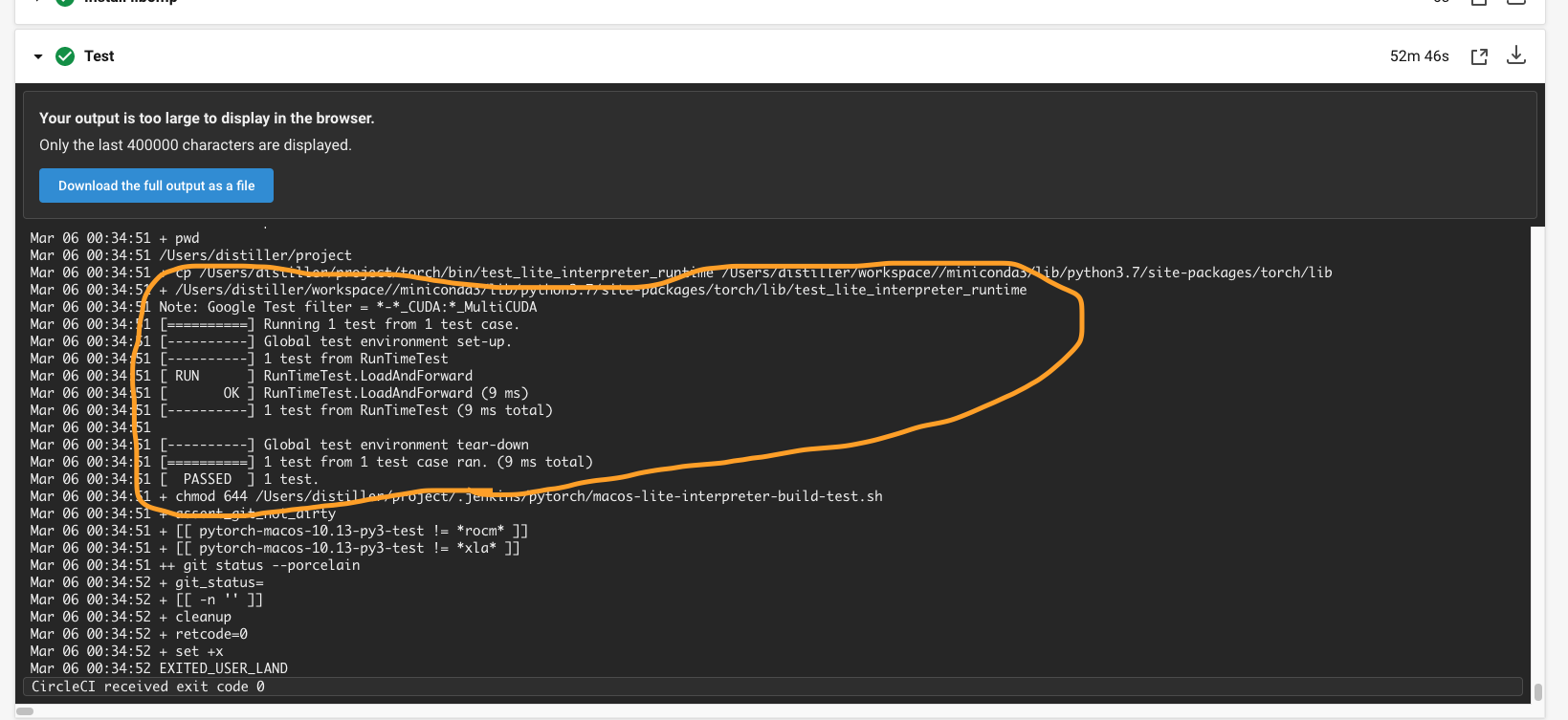
{F467164144}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52566
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26601585
Pulled By: cccclai
fbshipit-source-id: da7f47c906317ab3a4ef38fe2dbf2e89bc5bdb24
* Fix to empty_like example (#53088)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/52375
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53088
Reviewed By: zou3519
Differential Revision: D26752772
Pulled By: iramazanli
fbshipit-source-id: 21e395c6bbfd8f2cc808ddc12aefb2a426bb50d0
* [iOS GPU][BE][2/n] - Use dispatcher in MPSCNNTests.mm (#53429)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53429
Call the testing ops through dispatcher instead of calling them through `at::native`. Some metal ops can't be called through dispatcher yet. For example, `at::t` will call `at::as_strided` which hasn't been implemented on metal yet. For those ops, we'll skip and call `mpscnn::`directly. We'll convert those ops once we have implemented the missing ops.
ghstack-source-id: 123038068
Test Plan:
- Sandcastle CI
- Circle CI
- AIBench/Mobilelab
Reviewed By: SS-JIA, AshkanAliabadi
Differential Revision: D26683366
fbshipit-source-id: bf130b191046f5d9ac9b544d512bc6cb94f08c09
* Adding print_test_stats.py job to Windows CI (#53387)
Summary:
This way, we can get S3 test time stats for windows tests as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53387
Reviewed By: samestep
Differential Revision: D26893613
Pulled By: janeyx99
fbshipit-source-id: ac59e4406e472c9004eea0aae8a87a23242e3b34
* [NNC] Added some more external function bindings (#53420)
Summary:
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53420
Reviewed By: navahgar
Differential Revision: D26876784
Pulled By: Chillee
fbshipit-source-id: 05e7c782a72de5159879f88a104f1a273e0345eb
* Revert D26811466: [pytorch][PR] [reland] Add OpInfo for `bitwise_not` and make ROCM and CUDA OpInfo tests consistent
Test Plan: revert-hammer
Differential Revision:
D26811466 (https://github.com/pytorch/pytorch/commit/a5ada2127d110e0541d21cd6aed5f999dd77f6da)
Original commit changeset: 8434a7515d83
fbshipit-source-id: 9c2c760e18154a88cf7531e45843a802e3f3d19c
* [static runtime] convert to->to_copy (#53524)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53524
Add to->to_copy in the ReplaceWithCopy pass for playing well with
AliasDb
Test Plan:
Run bench with CastedBatchOneHot fusion off
(https://www.internalfb.com/intern/diff/view-version/123230476/),
on adindexer and adfinder models
Reviewed By: hlu1
Differential Revision: D26887050
fbshipit-source-id: 3f2fb9e27783bcdeb91c8b4181575f059317aff1
* Automated submodule update: FBGEMM (#53509)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: https://github.com/pytorch/FBGEMM/commit/da1e687ee39670f2e4031ff7ef8871dfeadaeb5b
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53509
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26885426
fbshipit-source-id: 80a3d0680fa584744380bb993ee3a2dc13991847
* move test to CUDA only (#53561)
Summary:
Helps make master green by removing this hefty memory allocating from CPU test.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53561
Reviewed By: malfet, albanD
Differential Revision: D26897941
Pulled By: janeyx99
fbshipit-source-id: 9f6c2d55f4eea1ab48665f7819fc113f21991036
* [caffe2] Add an optimization to avoid extra fp32->fp16 conversions in Onnxifi (#53560)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53560
If an op like Fused8BitRowwiseQuantizedToFloat ends up on CPU and Tile ends up on an accelerator and only FP16 is supported, then we want to make sure conversion from FP32 to FP16 is done on CPU to save cycles on accelerator.
Reviewed By: ChunliF
Differential Revision: D26862322
fbshipit-source-id: a7af162f2537ee9e4a78e6ef3f587129de410b07
* [pytorch] use correct warning type for tracer warnings (#53460)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53460
We have code to ignore this category of warnings and found this one is incorrect.
Use `stacklevel=2`, otherwise the warning is always filtered by TracerWarning.ignore_lib_warnings()
Test Plan: sandcastle
Reviewed By: wanchaol
Differential Revision: D26867290
fbshipit-source-id: cda1bc74a28d5965d52387d5ea2c4dcd1a2b1e86
* Add mock.patch() to clear environment for test (#53537)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53537
fixes #53526
This fixes the issue of the one of the environment variables being tested is somehow set by a previous test. For example:
`WORLD_SIZE=1 python test/distributed/test_c10d.py RendezvousEnvTest.test_common_errors` would have previously failed but now passes
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26891207
Pulled By: H-Huang
fbshipit-source-id: 1c23f6fba60ca01085a634afbafbb31ad693d3ce
* [Pytorch] Remove assumption forward exists in freeze_module (#52918)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52918
Freeze_module seems to operate under the assumption that forward always exists. This isnt true, so the change first checks for existence then retrieves the function.
ghstack-source-id: 123215242
Test Plan: Try freezing something with and without forward.
Reviewed By: dhruvbird
Differential Revision: D26671815
fbshipit-source-id: d4140dad3c59d3d20012143175f9b9268bf23050
* [static runtime] Minimum fusion group size (#50217)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50217
If we fuse small groups, things are slow
Test Plan: buck test //caffe2/test:static_runtime
Reviewed By: bertmaher
Differential Revision: D25643460
fbshipit-source-id: d2f39a4d612df3e1e29362abb23c2d997202f6ea
* Install GCC-9 into ROCm builders (#53459)
Summary:
Should prevent intermittent internal compiler errors reported in https://bugs.launchpad.net/ubuntu/+source/gcc-7/+bug/1917830
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53459
Reviewed By: izdeby
Differential Revision: D26870602
Pulled By: malfet
fbshipit-source-id: 1e90bb0d33736d01a696f80fc981aedcf7e3b639
* [fx] Add DCE pass (#52658)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52658
DCE will reverse iterate over the graph looking for nodes without users and delete them. It will skip over unused placeholders (since this affects the signature of the method) and outputs (which never have users but we want to keep them :) )
Test Plan: Added unit tests
Reviewed By: jamesr66a, khabinov, chenccfb
Differential Revision: D26602212
fbshipit-source-id: f4f196973e40546076636090bb0008c24f33795e
* [FX Acc] Add support for multi partitions in fx-glow (#53280)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53280
Add supports for handling multiple partitions in fx_glow e2e flow.
Test Plan: `buck test glow/fb/fx/fx_glow:test_fx_glow`
Reviewed By: gcatron
Differential Revision: D26819886
fbshipit-source-id: b31aa4612aab3aee694bb155571ba6f5e75c27ba
* [iOS GPU][BE][3/n] - Rename MetalTensor to MetalTensorImplStorage (#53430)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53430
The definition of Metal tensor is confusing, as we're using it to initialize the MetalTensorImpl. It acts more like a TensorImplStorage.
ghstack-source-id: 123038073
Test Plan:
1. Sandcastle CI
2. Circle CI
3. AIBench/Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26685439
fbshipit-source-id: e0487d0884e4efc3044d627ed0e4af454eca9d67
* [Static Runtime] Back out D26659824 (#53570)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53570
Reviewed By: allwu
Differential Revision: D26899099
fbshipit-source-id: 87c6d74a91c102e6b0487f9e6f49394755792a94
* [iOS GPU][BE][4/n] - Convert Objective-C class methods to C functions (#53431)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53431
Objective-C’s dynamism comes at the cost of code size, perf and safety. In Facebook, we tend to not use Objective-C primitives or keep it to a minimum unless you need them.
ghstack-source-id: 123063340
Test Plan:
1. CircleCI
2. SandCastleCI
3. Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26800753
fbshipit-source-id: b5a752a700d72ca3654f6826537aa3af47e87ecd
* [iOS GPU][BE][5/n] Remove indirection calls from MPSCNNOps.mm and MetalAten.mm (#53432)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53432
1. Creating individual .mm files for each op under the ops/ folder, and each op just has it's own function. The op is registered at the end of the file.
2. Remove the indirection calls from MetalAten.mm to MPSCNNOps.mm
3. Delete MPSCNNOps.mm
ghstack-source-id: 123205443
Test Plan:
1. Sandcastle
2. CircleCI
3. Mobilelab
Reviewed By: SS-JIA
Differential Revision: D26840953
fbshipit-source-id: e1664c8d7445fdbd3b016c4dd51de0a6294af3a5
* Fix inport -> import typo in documentation (#53589)
Summary:
Fixes a small documentation typo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53589
Reviewed By: ngimel
Differential Revision: D26907045
Pulled By: Chillee
fbshipit-source-id: 15c35bec8d75dd897fe8886d0e0e1b889df65b24
* Support parsing Ellipsis in JIT frontend (#53576)
Summary:
De-sugars `Ellipsis` into dots (`...`)
Fixes https://github.com/pytorch/pytorch/issues/53517
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53576
Reviewed By: pbelevich
Differential Revision: D26904361
Pulled By: gmagogsfm
fbshipit-source-id: 5b23e049a075a9a99e37dcb47a9410b6f82a6fb7
* Remove notion of "level" from `Module::dump_to_str`. (#52539)
Summary:
The code uses `torch::jit::jit_log_prefix` for handling recursive
indenting in most places in this function. There was one place that was
using "level", but it was buggy -- it would result in a compounding
superlinear indent. Note that changing it to "level+1" doesn't fix the
bug.
Before/after:
https://gist.github.com/silvasean/8ee3ef115a48de6c9c54fbc40838d8d7
The new code establishes a recursive invariant for
`Module::dump_to_str`: the function returns the module printed at the
base indent level (i.e. no indent). `torch::jit:log_prefix` is used
to prefix recursive calls. The code was already nearly there, except for
this spurious use of "level".
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52539
Reviewed By: navahgar
Differential Revision: D26773657
Pulled By: gmagogsfm
fbshipit-source-id: ab476f0738bf07de9f40d168dd038dbf62a9a79e
* [caffe2] don't use static for template declarations in headers (#53602)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53602
Using static in headers causes code bloat. Remove the unnecessary `static` qualifiers.
Test Plan: sandcastle
Reviewed By: asp2insp
Differential Revision: D26886180
fbshipit-source-id: 6008bce0d47f06d3146ce998234574a607c99311
* Definition infrastructure for instruction count ubenchmarks (#53293)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53293
Instruction count benchmarks need some includes for IValues, but this is also just generally useful. (Unlike Python where you can just drop imports anywhere, C++ will get very upset if you `#include` in a function body...)
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D26906684
Pulled By: robieta
fbshipit-source-id: cbdfd79d3b8383100ff2e6857b6f309c387cbe2a
* Quality of life improvements to Timer (#53294)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53294
Just a bunch of little things, none of which are big enough to need a full PR.
1) C++ wall time should release the GIL
2) Add option to retain `callgrind.out` contents. This will allow processing with kCachegrind for more detailed analysis.
3) Stop subtracting the baseline instruction counts. (People just found it confusing when they saw negative instruction counts.) There is a finesse in #53295 that drops the baseline to ~800 instructions for `number=100`, and at that level it's not worth correcting.
4) Add a `__mul__` overload to function counts. e.g. suppose `c0` was run with `number=100`, and `c1` was run with `number=200`, then `c0 * 2 - c1` is needed to properly diff them. (Obviously there are correctness concerns, but I think it's fine as a caveat emptor convenience method.)
5) Tweak the `callgrind_annotate` call, since by default it filters very small counts.
6) Move some args to kwargs only since types could be ambiguous otherwise.
7) Don't omit rows from slices. It was annoying to print something like `stats[:25]` and have `__repr__` hide the lines in the middle.
Test Plan: Imported from OSS
Reviewed By: Chillee
Differential Revision: D26906715
Pulled By: robieta
fbshipit-source-id: 53d5cd92cd17212ec013f89d48ac8678ba6e6228
* Expands OpInfo out= testing (#53259)
Summary:
Addresses several of the challenges described in https://github.com/pytorch/pytorch/issues/49468.
This PR builds on https://github.com/pytorch/pytorch/pull/50741 and https://github.com/pytorch/pytorch/issues/53105 to extend OpInfo out= testing. It covers the following cases for ops that produce a single tensor:
- out= values don't affect computation
- out= noncontiguous produces the correct output and preserves strides
- out= with the wrong shape throws a warning
- out= with an empty tensor throws no warning
- out= with the wrong device throws an error
- out= with a dtype the computation's result can't be "safely" cast to throws an error
It works with operations that produce a single tensor and operations that produce an iterable of tensors (the latter is tested with operations like torch.svd).
In addition to the new out= test, the OpInfos have been updated. "supports_tensor_out" is replaced with the more general and straightforward "supports_out" metadata, and many operations which previously had to skip out= testing with an explicit SkipInfo no longer need to. A couple redundant tests in test_unary_ufuncs.py have been removed, too.
One other perk of these tests is that once all operations have OpInfos this will allow us to validate that we've universally deprecated incorrectly sized tensors passed to out=, and give us the option to actually disable the behavior.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53259
Reviewed By: mrshenli
Differential Revision: D26894723
Pulled By: mruberry
fbshipit-source-id: 2b536e9baf126f36386a35f2f806dd88c58690b3
* Add TORCH_CHECK_NOT_IMPLEMENTED/c10::NotImplementedError; make dispatch use it (#53377)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53377
My underlying goal is I want to make the test suite ignore
NotImplementedError without failing when bringing up a backend (meta)
that doesn't have very many functions implemented.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D26850766
Pulled By: ezyang
fbshipit-source-id: ffbdecd22b06b5ac23e1997723a6e2a71dfcd14a
* Add debug only layout assert for empty_cpu (#53396)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53396
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26891806
Pulled By: ezyang
fbshipit-source-id: 4789ab5587d1a11d50e9a60bbfa1c21c1222823e
* Add Meta support for empty_strided (#53397)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53397
It turns out once you remove all the indirection from the
empty_cpu_strided implementation, this implementation is pretty
simple. We should see if we can simplify empty_cpu this way too.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bdhirsh
Differential Revision: D26891870
Pulled By: ezyang
fbshipit-source-id: 9bddd332d32d8bf32fa3175e3bb0ac3a8954ac91
* Modify error message (#53525)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53518
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53525
Reviewed By: mthrok
Differential Revision: D26900045
Pulled By: carolineechen
fbshipit-source-id: 387301381603d37d24cc829c8fed38123f268c0b
* Add logic to auto-fetch submodules (#53461)
Summary:
In setup.py add logic to:
- Get list of submodules from .gitmodules file
- Auto-fetch submodules if none of them has been fetched
In CI:
- Test this on non-docker capable OSes (Windows and Mac)
- Use shallow submodule checkouts whenever possible
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53461
Reviewed By: ezyang
Differential Revision: D26871119
Pulled By: malfet
fbshipit-source-id: 8b23d6a4fcf04446eac11446e0113819476ef6ea
* [Pytorch] Fix embedding bag bug accessing unaligned memory (#53300)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53300
Float scale and bias are packed as per row parameters at the end of each row.
This takes 8 bytes. However if the number of elements in row are such that end
of row address is unaligned for float, not multiply of 4 bytes, we will get
unaglined memory access.
Current solution is inefficient, so this should really be fixed at weight
packing time.
It seems that longer term there will be prepack function that packs weights. So
this fallback path should eventually match that and not store scale and bias
inline.
Test Plan: python test/test_quantization.py
Reviewed By: pengtxiafb
Differential Revision: D26828077
fbshipit-source-id: 8512cd95f3ac3ca53e1048139a9f6e19aa8af298
* Fix a cuda max_pool3d issue, do multiplication in int64 (#52828)
Summary:
Fix https://github.com/pytorch/pytorch/issues/52822
- [x] benchmark
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52828
Reviewed By: mrshenli
Differential Revision: D26866674
Pulled By: heitorschueroff
fbshipit-source-id: bd8276dd70316a767dc6e1991c1259f1f0b390b2
* Fix pylint error torch.tensor is not callable (#53424)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53424
Fixes https://github.com/pytorch/pytorch/issues/24807 and supersedes the stale https://github.com/pytorch/pytorch/issues/25093 (Cc Microsheep). If you now run the reproduction
```python
import torch
if __name__ == "__main__":
t = torch.tensor([1, 2, 3], dtype=torch.float64)
```
with `pylint==2.6.0`, you get the following output
```
test_pylint.py:1:0: C0114: Missing module docstring (missing-module-docstring)
test_pylint.py:4:8: E1101: Module 'torch' has no 'tensor' member; maybe 'Tensor'? (no-
member)
test_pylint.py:4:38: E1101: Module 'torch' has no 'float64' member (no-member)
```
Now `pylint` doesn't recognize `torch.tensor` at all, but it is promoted in the stub. Given that it also doesn't recognize `torch.float64`, I think fixing this is out of scope of this PR.
---
## TL;DR
This BC-breaking only for users that rely on unintended behavior. Since `torch/__init__.py` loaded `torch/tensor.py` it was populated in `sys.modules`. `torch/__init__.py` then overwrote `torch.tensor` with the actual function. With this `import torch.tensor as tensor` does not fail, but returns the function rather than the module. Users that rely on this import need to change it to `from torch import tensor`.
Reviewed By: zou3519
Differential Revision: D26223815
Pulled By: bdhirsh
fbshipit-source-id: 125b9ff3d276e84a645cd7521e8d6160b1ca1c21
* Automated submodule update: tensorpipe (#53599)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/tensorpipe](https://github.com/pytorch/tensorpipe).
New submodule commit: https://github.com/pytorch/tensorpipe/commit/a11ddfdf99875677203e15bd7c3c38c5fc01f34a
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53599
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: lw
Differential Revision: D26910634
fbshipit-source-id: a2bf808536e42b9208e5d9f88198ce64061385fa
* [PyTorch] Fix typo in QNNPACK
Summary: Build failed when `PYTORCH_QNNPACK_RUNTIME_QUANTIZATION` is unset. According to D21339044 (https://github.com/pytorch/pytorch/commit/622f5b68f08eda6dd7eb6210494ea164d04ab399) it seems like a typo.
Test Plan: buck build //xplat/caffe2/aten/src/ATen/native/quantized/cpu/qnnpack:pytorch_qnnpackWindows xplat/mode/windows-msvc-15.9
Reviewed By: kimishpatel
Differential Revision: D26907439
fbshipit-source-id: ac52eeef4ee70726f2a97b22ae65921b39aa0c0b
* .circleci: Remove hardcoded tag for rocm (#53636)
Summary:
We shouldn't need the hardcoding anymore
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53636
Reviewed By: malfet
Differential Revision: D26921067
Pulled By: seemethere
fbshipit-source-id: 1e3ba4bbef4c5c6c6a6bcc2f137fef017cec3bb7
* [caffe2] use snprintf() instead of sprintf() in the Checkpoint operator (#53434)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53434
Use `snprintf()` to avoid buffer overflows.
Also only throw an exception on error, instead of crashing the entire
application. A failure can occur if the caller supplies an invalid format
string.
ghstack-source-id: 123401582
Test Plan:
Ran the checkpoint tests:
buck test caffe2/caffe2/python/operator_test:checkpoint_test
Verified that the checkpoint file names logged in the output are the same
before and after this change.
I also tested manually changed the initial buffer size to 1 to confirm that
the code works when the initial buffer size is too small. I considered
updating the checkpoint_test.py code to test using long db names that would
exceed this limit, but I figured that long filenames was likely to cause
other problems on some platforms (Windows has a maximum path length of 260
characters up until pretty recent releases).
Differential Revision: D26863355
fbshipit-source-id: 8fc24faa2a8dd145471067718d323fdc8ce055d6
* Automated submodule update: FBGEMM (#53632)
Summary:
This is an automated pull request to update the first-party submodule for [pytorch/FBGEMM](https://github.com/pytorch/FBGEMM).
New submodule commit: https://github.com/pytorch/FBGEMM/commit/4b88f40a0e135d7929f3ba0560152fada8d49a75
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53632
Test Plan: Ensure that CI jobs succeed on GitHub before landing.
Reviewed By: jspark1105
Differential Revision: D26919594
fbshipit-source-id: 4ac25bbe883b3c2cd4c02bc75a6e2c6f41d2beb7
* Lazy Modules Documentation Clarifications (#53495)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53366
gchanan albanD
Thanks for the feedback. Did a first pass trying to address the concerns in the original issue.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53495
Reviewed By: mrshenli
Differential Revision: D26914768
Pulled By: albanD
fbshipit-source-id: fa049f1952ef05598f0da2abead9a5a5d3602f75
* ci: Remove special versioning privileges for cu102 (#53133)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53133
In light of some issues where users were having trouble installing CUDA
specific versions of pytorch we should no longer have special privileges
for CUDA 10.2.
Recently I added scripts/release/promote/prep_binary_for_pypi.sh (https://github.com/pytorch/pytorch/pull/53056) to make
it so that we could theoretically promote any wheel we publish to
download.pytorch.org to pypi
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: walterddr
Differential Revision: D26759823
Pulled By: seemethere
fbshipit-source-id: 2d2b29e7fef0f48c23f3c853bdca6144b7c61f22
* Add more kernel launch checks (#53286)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53286
Test Plan: Sandcastle
Reviewed By: ngimel
Differential Revision: D26818164
fbshipit-source-id: 01ba50dc7e4a863e26c289d746bc5b95aa76d3cc
* [Static Runtime] Remove dead code (#53588)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53588
Remove `SRViewOperatorRegistry` and related code now that it's no longer needed.
Reviewed By: swolchok
Differential Revision: D26901367
fbshipit-source-id: fa73501cd785d4b89466cda81481aea892f8241f
* [FX][docs] Render inherited methods in fx.Tracer API reference (#53630)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53630
Test Plan: Imported from OSS
Reviewed By: suo
Differential Revision: D26918962
Pulled By: jamesr66a
fbshipit-source-id: 2c84e308889d4ba3176018c7bd44a841e715e6c8
* [PyTorch] Make IValue::toTensor() inlineable (#53213)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53213
The failure path for toTensor() is fairly long because it has to stringify tagKind() and construct a std::string. Forcibly outlining it should allow inlining the happy path.
ghstack-source-id: 123012703
Test Plan:
1) Compare perf profile on AdIndexer benchmark before/after --
toTensor frames no longer show up, demonstrating inlining
2) Compare perf stat results on AdIndexer benchmark before/after:
Before:
```
17,104.66 msec task-clock # 0.999 CPUs utilized ( +- 0.26% )
3,666 context-switches # 0.214 K/sec ( +- 18.53% )
3 cpu-migrations # 0.000 K/sec ( +- 6.25% )
102,745 page-faults # 0.006 M/sec ( +- 0.47% )
33,860,604,938 cycles # 1.980 GHz ( +- 0.25% ) (50.02%)
69,514,752,652 instructions # 2.05 insn per cycle ( +- 0.06% ) (50.01%)
11,280,877,966 branches # 659.521 M/sec ( +- 0.11% ) (50.01%)
75,739,099 branch-misses # 0.67% of all branches ( +- 0.98% ) (50.03%)
# Table of individual measurements:
17.2467 (+0.1172) #
17.0014 (-0.1280) #
17.2134 (+0.0840) #
17.0951 (-0.0343) #
17.0905 (-0.0389) #
# Final result:
17.1294 +- 0.0447 seconds time elapsed ( +- 0.26% )
```
After:
```
16,910.66 msec task-clock # 0.999 CPUs utilized ( +- 0.27% )
3,495 context-switches # 0.207 K/sec ( +- 18.34% )
3 cpu-migrations # 0.000 K/sec ( +- 6.25% )
101,769 page-faults # 0.006 M/sec ( +- 0.45% )
33,460,776,952 cycles # 1.979 GHz ( +- 0.28% ) (50.03%)
69,243,346,925 instructions # 2.07 insn per cycle ( +- 0.17% ) (50.02%)
11,229,930,860 branches # 664.074 M/sec ( +- 0.14% ) (50.03%)
72,273,324 branch-misses # 0.64% of all branches ( +- 0.55% ) (50.03%)
# Table of individual measurements:
16.9530 (+0.0246) #
17.0898 (+0.1614) #
16.8493 (-0.0791) #
16.8282 (-0.1002) #
16.9217 (-0.0067) #
# Final result:
16.9284 +- 0.0464 seconds time elapsed ( +- 0.27% )
```
1.1% cycles win, 0.38% instructions win, both apparently outside noise level
Reviewed By: smessmer
Differential Revision: D26793481
fbshipit-source-id: b035b3ad20f9e22ae738d91163641031b1130ce6
* [PyTorch] Add c10::MaybeOwned and Tensor::expect_contiguous (#53317)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53317
This seems like it might help in cases where we have to call
`Tensor::contiguous`, but we expect that the tensor in question will
be contiguous a good portion of the time.
ghstack-source-id: 123203771
Test Plan:
Profiled AdIndexer on inline_cvr; time spent in
clip_ranges_gather_sigrid_hash_each_feature<int> was cut in half from
1.37% to 0.66%
Reviewed By: smessmer
Differential Revision: D26738036
fbshipit-source-id: b5db10783ccd103dae0ab3e79338a83b5e507ebb
* move rnn cell size check to cpp (#51964)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/32193.
Possible further improvements:
- do the same for quantized cells
- reuse newly written functions in https://github.com/pytorch/pytorch/blob/56034636b9f37b54dacfab8794e93ba6b10bdfc7/torch/csrc/api/src/nn/modules/rnn.cpp#L699-L715
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51964
Reviewed By: albanD
Differential Revision: D26757050
Pulled By: ngimel
fbshipit-source-id: 9c917d9124de2b914ad9915c79af675ae561295a
* fix channels_last bug in upsample kernels (#53535)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53535
During the port to structured kernels for upsample kernels, I missed that a subset of them explicitly pass `memory_format` information from the input to the output tensors.
Note 1:
I added the logic into the `meta` function of each op, which feels morally correct since this logic affects the output shape/metadata. One consequence is that all backend implementations will get the logic. I synced with fmassa that this seems reasonable.
Note 2:
This logic used to happen in the following operators, which this PR fixes:
- upsample_nearest3d
- upsample_trilinear3d
- upsample_nearest2d
- upsample_bilinear2d
I explicitly didn't patch the other upsample kernels, which look like they never forwarded memory_format information:
- `upsample_bicubic2d` (maybe this should though? `UpSampleBicubic2d.cpp` isn't currently written to do anything different for `channels_last` tensors)
- All of the `upsample_{mode}1d` operators. Probably because, afaik, channels_last isn't supported for 3d tensors
- The corresponding backwards operator for every upsample op.
Note 3:
I'm also wondering why memory_format isn't just directly a part of the `tensor::options()` method, which would cause all ops to universally forward memory_format information from input to output tensors, rather than just the upsample ops. My guess is:
- BC-breakage. I'm not sure whether this would really *break* people, but it's an API change
- performance. `tensor::options()` is called everywhere, and adding a call to `suggest_memory_format()` would probably noticeably hit microbenchmarks. We could probably deal with that by making `memory_format` a precomputed field on the tensor?
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D26891540
Pulled By: bdhirsh
fbshipit-source-id: b3845f4dd5646b88bf738b9e41fe829be6b0e5cf
* Remove hacky wrapper from a lot of unary operators. (#52276)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/52276
Test Plan: Imported from OSS
Reviewed By: walterddr, nikithamalgifb
Differential Revision: D26732399
Pulled By: bdhirsh
fbshipit-source-id: 4189594e938c9908a4ea98a0b29d75a494d0dc35
* Port sin to structured. (#52277)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/52277
Test Plan: Imported from OSS
Reviewed By: walterddr, nikithamalgifb
Differential Revision: D26732398
Pulled By: bdhirsh
fbshipit-source-id: fa1a3c2359e2bf8fe326d2f74d2f9041ba189d24
* [FX] Make TracerBase._find_user_frame private (#53654)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53654
Test Plan: Imported from OSS
Reviewed By: suo, Chillee
Differential Revision: D26924950
Pulled By: jamesr66a
fbshipit-source-id: 23e641bbcabff148c18db0edeff0a12c10b8c42d
* [JIT] Enable ModuleList non-literal indexing (#53410)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53410
**Summary**
This commit enables indexing into `ModuleList` using a non-literal
index if the LHS of the assignment statement of which the indexing is
the RHS is annotated with an interface type.
This feature already exists for `ModuleDict`, and this commit builds on
top of that implementation. A `prim::ModuleContainerIndex` operator is
emitted for any statement of the form `lhs: InterfaceType =
module_container[idx]`. The same operator has to be used for both
`ModuleDict` and `ModuleList` because serialization does not preserve
the metadata that indicates whether a `Module` is a `ModuleDict` or
`ModuleList`.
**Testing**
This commit extends the existing unit tests for non-literal `ModuleDict`
indexing to test non-literal `ModuleList` indexing.
**Fixes**
This commit fixes #47496.
Test Plan: Imported from OSS
Reviewed By: gmagogsfm
Differential Revision: D26857597
Pulled By: SplitInfinity
fbshipit-source-id: d56678700a264d79aae3de37ad6b08b080175f7c
* [Static Runtime] Fix bug in static_runtime::to_copy (#53634)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53634
Make the op signature of `static_runtime::to_copy` consistent with that of native_functions.yaml so it works with 2-5 args:
```
- func: to.dtype(Tensor self, ScalarType dtype, bool non_blocking=False, bool copy=False, MemoryFormat? memory_format=None) -> Tensor
variants: method
device_guard: False
```
(Note: this ignores all push blocking failures!)
Reviewed By: ajyu
Differential Revision: D26906726
fbshipit-source-id: b9203eb23619aba42b1bfed1a077401f9fe2ddf0
* Editing pass on native/README.md updates (#53638)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53638
Mostly slight edits, and deleting some outdated sections.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: heitorschueroff
Differential Revision: D26920600
Pulled By: ezyang
fbshipit-source-id: e3bda80ecb622a1fcfde64e4752ba89a71056340
* use DimVector for sizes and strides (#53001)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53001
Test Plan: Imported from OSS
Reviewed By: swolchok
Differential Revision: D26719508
Pulled By: bhosmer
fbshipit-source-id: 4053d632e11b2de1576c59c5a6b881a195d6206b
* [GraphModule] Improve buffer registration during init (#53444)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53444
GraphModule construction has two options when constructing the base nn.Module: a dict of names to attrs to assign to the GraphModule, or another nn.Module to copy attrs from.
- For the dict case, add logic to explicitly register `nn.Tensors` that are not `nn.Parameter` as buffers on the GraphModule, else fall back to `__setattr__`.
- For the other `nn.Module` case, update so that it checks in the other module whether the attr to copy in is a buffer, and register it as such, else fall back to `__setattr__`.
Test Plan: Added tests for fetching params and buffers from a GraphModule using both dict and module `__init__`s
Reviewed By: jamesr66a
Differential Revision: D26860055
fbshipit-source-id: 8d9999f91fef20aaa10969558006fc356247591f
* Print onnxifi failed status code in readable format (#53648)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53648
Reviewed By: hl475
Differential Revision: D26838564
fbshipit-source-id: 6e0e5695a58422d573f9c97bfb241bce2688f13b
* [JIT] Fix backward compatibility test broken by #53410 (#53683)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53683
**Summary**
This commit fixes the BC test broken by #53410. There are no promises
about operator-level BC with the operators added and modified by that
PR, so this test failure does not represent a real backward
compatibility issue.
**Test Plan**
Ran the BC test locally by runniing `dump_all_schemas.py` and then
`check_backward_compatibility.py`.
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26936505
Pulled By: SplitInfinity
fbshipit-source-id: 829d5d78e4cba44feea382d0fbd66e77dee7eed2
* Convert type annotations in nn/functional.py to py3 syntax (#53656)
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/53656
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D26926018
Pulled By: jamesr66a
fbshipit-source-id: 2381583cf93c9c9d0c9eeaa6e41eddce3729942d
* Adds a bool is_available() method to the backend contract (#53068)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53068
Adds a ```bool is_available()``` method to the backend contract: it returns ```true``` if ```compile()``` and ```execute()``` can be called; ```false``` otherwise.
It is used to implement the following changes in the ```LoweredModule```:
* ```compile()``` in ```__setstate__``` will run if ```is_available()```, else ```__setstate__``` throws an exception (“Backend not available.”).
* ```compile()``` at ```LoweredModule``` creation will run if ```is_available()```, else a WARNING will be thrown.
* ```execute()``` will only be executed if ```is_available()``` returns true; else throws an exception (“Backend not available.”).
The goal of these changes is to ensure we have a well defined behaviour for the different combinations of backend availability on-host and on-target.
More specifically, backends may have different capabilities to compile and/or execute the Module, depending whether this happens on-host (i.e. where the program is being written) or on-target (where the program is being executed).
First of all, we know that "preprocess" always takes place, and that only happens on-host at creation time. So, we can assume that any compilation is needed/possible on-host then all of it could be pushed here.
Overall, we want to ensure the following:
**On host**
| compile | execute | Outcome |
| -- | -- | -- |
| No | No | On module creation, LoweredModule is generated, with a warning (since compilation and execution can still take place on-target). On module load, throws an exception (since execution is not possible). |
| No | Yes | This configuration should not be possible. This assumes the full compiler is not available, even if some work was done in preprocess the program cannot be finalized for execution. |
| Yes | No | In this case, the expectation would be for is_available() to return false, and compilation logic to move into preprocess. |
| Yes | Yes | All good. This is the only case that is_available() should return true. |
**On target**
| compile | execute | Outcome |
| -- | -- | -- |
| No | No | Loading the LoweredModule throws an exception. Since execution is not possible. |
| No | Yes | Basically this is another instance of Yes/Yes: compilation per se may not be possible on device, which means compile() can be called without issue but it is a no-op, and thus is_available should return true. Consequently, loading the LoweredModule: Succeeds, if the preprocessed module is ready for execution. Fails with exception otherwise. |
| Yes | No | This configuration should not be possible. Just putting here for completeness. |
| Yes | Yes | All good. This, along with No/Yes case (because compilation is assumed to have happened on-host, so it's just another instance of Yes/Yes), are the cases where is_available() should return true. |
**Refactoring existing code**
This change also updates other backends (Glow) code, to implement the is_available() method to have the same behaviour as before this change (i.e. always available).
This should not cause backward incompatibilities with already saved models since we're adding a new method to the PyTorchBackendInterface.
Models saved with the old interface that didn't have is_available() will still find the other 2 methods in the bound object (i.e. compile and execute), and the saved LoweredModule logic will be the old one.
**Future**
We plan to use is_available() to implement support for fallback to the PyTorch interpreter.
ghstack-source-id: 123498571
Test Plan: Added C++ (test_backend.cpp) and Python (test_backends.py) tests to validate the exceptions.
Reviewed By: jackm321, spaugh, iseeyuan
Differential Revision: D26615833
fbshipit-source-id: 562e8b11db25784348b5f86bbc4179aedf15e0d3
* Filter 0's returned by exponential distribution (#53480)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/48841 for half datatype (it was fixed for other datatypes before).
The reason for https://github.com/pytorch/pytorch/issues/48841 happening for half was that `exponential_` for half was producing 0s.
Exponential distribution implementation on cuda is here https://github.com/pytorch/pytorch/blob/e08aae261397b8da3e71024bbeddfe0487185d1d/aten/src/ATen/native/cuda/DistributionTemplates.h#L535-L545
with `transformation::exponential` defined here
https://github.com/pytorch/pytorch/blob/e08aae261397b8da3e71024bbeddfe0487185d1d/aten/src/ATen/core/TransformationHelper.h#L113-L123
It takes a uniformly distributed random number and takes `log` of it. If necessary, the result is then converted to low precision datatype (half). To avoid 0's, before applying `log`, ones are replaced with std::nextafter(1,0). This seems fine, because log(1-eps) is still representable in half precision (`torch.tensor([1.], device="cuda").nextafter(torch.tensor([0.], device="cuda")).log().half()` produces 5.96e-8) , so casting to `scalar_t` should work. However, since fast log approximation is used (`__logf`), the log result is ~3e-9 instead of more accurate 5.96e-8, and underflows when casting to half. Using `::log` instead of fast approximation fixes it, however, it comes with ~20% perf penalty on exponential kernel for fp32 datatype, probably more for half.
Edit: alternative approach used now is to filter all small values returned by transformation. The result is equivalent to squashing of 1's to 1-eps that was used before, and computing correct log of 1-eps (which is -eps, exactly equal even for doubles). This doesn't incur noticeable performance hit.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53480
Reviewed By: mruberry
Differential Revision: D26924622
Pulled By: ngimel
fbshipit-source-id: dc1329e4773bf91f26af23c8afa0ae845cfb0937
* If distributed module isn't available, don't run distributed/pipeline tests (#53547)
Summary:
Following up https://github.com/pytorch/pytorch/issues/52945
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53547
Reviewed By: mrshenli
Differential Revision: D26946364
Pulled By: ezyang
fbshipit-source-id: 9f93e76e2420d19b46d4eb3429eac5f263fd5c23
* [RELAND] Deduplicate shared params before constructing Reducer in DDP (#53279)
Summary:
Original PR https://github.com/pytorch/pytorch/pull/51929 seemed to trigger failures in `pytorch_linux_xenial_py3_clang5_asan_test2`. Resubmitting to figure out why, and hopefully reland.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53279
Reviewed By: mrshenli
Differential Revision: D26916701
Pulled By: zhaojuanmao
fbshipit-source-id: 75c74c8ad8ad24154eb59eddb2b222da0a09897e
* Convert a few more checks to raise NotImplementedError (#53610)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53610
I noticed these because I was running the test suite under
meta device and triggered these error checks without getting
a NotImplementedError. Well, now they raise.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D26918376
Pulled By: ezyang
fbshipit-source-id: 20d57417aa64875d43460fce58af11dd33eb4a23
* Fix inaccurate dispatch table for fill_ (#53611)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53611
fill_ now uses DispatchStub which means it only works for
CPU/CUDA.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D26918374
Pulled By: ezyang
fbshipit-source-id: fc899c28f02121e7719b596235cc47a0f3da3aea
* Marginally improve pytest collection for top-level test files (#53617)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53617
I'm trying to make `pytest test/*.py` work--right now, it fails during
test collection. This removes a few of the easier to fix pytest
collection problems one way or another. I have two remaining problems
which is that the default dtype is trashed on entry to test_torch.py and
test_cuda.py, I'll try to fix those in a follow up.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D26918377
Pulled By: ezyang
fbshipit-source-id: 42069786882657e1e3ee974acb3ec48115f16210
* Remove reference to 9.2 as it's been removed from nightlies (#53716)
Summary:
Removing a tiny bit of unneeded reference to cuda92 for windows binary. Note that the config.yml did not change.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53716
Reviewed By: VitalyFedyunin
Differential Revision: D26947029
Pulled By: janeyx99
fbshipit-source-id: 3bbf1faa513756eda182d2d80033257f0c629309
* Improve logic for S3 stats gathering. Uses automatic SLOW_TESTS. (#53549)
Summary:
This PR:
1. refactors the logic for S3 stats gathering.
2. Renames SLOW_TESTS to TARGET_DET_LIST to disambiguate and remove confusion with slowTest
2. detects slow tests (tests with time > 5min) to add to the TARGET_DET_LIST based on results in S3 from the previous nightly.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53549
Test Plan:
Set CIRCLE_JOB to your favorite CI job (like `pytorch_linux_bionic_py3_8_gcc9_coverage_test1`).
Run `python test/run_test.py --determine-from=<your fave pytorch files>`
e.g., `python test/run_test.py --determine-from=test/run_test.py`
Reviewed By: mrshenli
Differential Revision: D26904478
Pulled By: janeyx99
fbshipit-source-id: 9576b34f4fee09291d60e36ff2631753a3925094
* [fix] nn.Embedding: allow changing the padding vector (#53447)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53368
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53447
Reviewed By: albanD
Differential Revision: D26946284
Pulled By: jbschlosser
fbshipit-source-id: 54e5eec7da86fa02b1b6e4a235d66976a80764fc
* Added CUDA support for torch.orgqr (#51348)
Summary:
**Update:** MAGMA support was dropped from this PR. Only the cuSOLVER path is implemented and it's used exclusively.
**Original PR message:**
This PR adds support for CUDA inputs for `torch.orgqr`.
CUDA implementation is based on both [cuSOLVER](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) and MAGMA. cuSOLVER doesn't have a specialized routine for the batched case. While MAGMA doesn't have a specialized GPU native (without CPU sync) `orgqr`. But MAGMA has implemented (and not documented) the batched GPU native version of `larft` function (for small inputs of size <= 32), which together with `larfb` operation form `orgqr` (see the call graph [here at the end of the page](http://www.netlib.org/lapack/explore-html/da/dba/group__double_o_t_h_e_rcomputational_ga14b45f7374dc8654073aa06879c1c459.html)).
So now there are two main codepaths for CUDA inputs (if both MAGMA and cuSOLVER are available):
* if `batchsize > 1` and `tau.shape[-1] <= 32` then MAGMA based function is called
* else [cuSOLVER's `orgqr`](https://docs.nvidia.com/cuda/cusolver/index.html#cuSolverDN-lt-t-gt-orgqr) is used.
If MAGMA is not available then only cuSOLVER is used and vice versa.
Documentation updates and possibly a new name for this function will be in a follow-up PR.
Ref. https://github.com/pytorch/pytorch/issues/50104
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51348
Reviewed By: heitorschueroff
Differential Revision: D26882415
Pulled By: mruberry
fbshipit-source-id: 9f91ff962921932777ff108bedc133b55fe22842
* Use native ctc loss for target length 256 (#53557)
Summary:
Apparently cudnn (8.1) does not like 256-long targets.
Thank you raotnameh for reporting.
Fixes https://github.com/pytorch/pytorch/issues/53505
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53557
Reviewed By: VitalyFedyunin
Differential Revision: D26947262
Pulled By: albanD
fbshipit-source-id: df6da7db8fd8e35050b4303ff1658646ebc60141
* [android] bump gradle version to 6.8.3 (#53567)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53567
Updating gradle to version 6.8.3
Proper zip was uploaded to aws.
Successful CI check: https://github.com/pytorch/pytorch/pull/53619
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D26928885
Pulled By: IvanKobzarev
fbshipit-source-id: b1081052967d9080cd6934fd48c4dbe933630e49
* [andoid] publishing to maven central (#53568)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53568
Bintray, JCenter are going to be unavailable on May 1st
https://jfrog.com/blog/into-the-sunset-bintray-jcenter-gocenter-and-chartcenter/
Migrating publishing to Maven Central the same way as other fb oss projects, reference PR h…
xsacha
pushed a commit
to xsacha/pytorch
that referenced
this pull request
Mar 31, 2021
Summary: Pull Request resolved: pytorch#53514 Test Plan: ``` tools/test_history.py columns --ref=0ca029b22d17d236d34bcecad44b94b35b1af4bb test_common_errors pytorch_linux_xenial_cuda11_1_cudnn8_py3_gcc7_test1 ``` Reviewed By: janeyx99 Differential Revision: D26886385 Pulled By: samestep fbshipit-source-id: d3d79282e535707616d992ab8cf6216dfb777639
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
4 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Test plan: