add memory_tracker tool to help profiling memory usages #88825
Conversation
🔗 Helpful Links🧪 See artifacts and rendered test results at hud.pytorch.org/pr/88825
Note: Links to docs will display an error until the docs builds have been completed. ✅ No FailuresAs of commit 0bf8642: This comment was automatically generated by Dr. CI and updates every 15 minutes. |
22f1a95 to
49c2f52
Compare
65fb257 to
dab82f6
Compare
|
@zhaojuanmao has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator. |
There was a problem hiding this comment.
Besides these global stats, it will also be helpful to tell how much memory is activation, how much is temporary, etc.
There was a problem hiding this comment.
Those will be added in followup PRs
dab82f6 to
9a66a5f
Compare
|
@zhaojuanmao has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator. |
9a66a5f to
53aadda
Compare
|
@zhaojuanmao has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator. |
53aadda to
2325e4b
Compare
|
@zhaojuanmao has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator. |
|
failures are not related |
|
@pytorchbot merge |
Merge startedYour change will be merged once all checks pass (ETA 0-4 Hours). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
Merge failedReason: The following mandatory check(s) failed (Rule Dig deeper by viewing the failures on hud Details for Dev Infra teamRaised by workflow job |
|
@pytorchbot merge |
2325e4b to
0bf8642
Compare
Merge startedYour change will be merged once all checks pass (ETA 0-4 Hours). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
|
@zhaojuanmao has imported this pull request. If you are a Meta employee, you can view this diff on Phabricator. |
|
@pytorchbot merge |
|
The merge job was canceled. If you believe this is a mistake,then you can re trigger it through pytorch-bot. |
|
@pytorchbot merge -f "flaky CI" |
Merge startedYour change will be merged immediately since you used the force (-f) flag, bypassing any CI checks (ETA: 1-5 minutes). Learn more about merging in the wiki. Questions? Feedback? Please reach out to the PyTorch DevX Team |
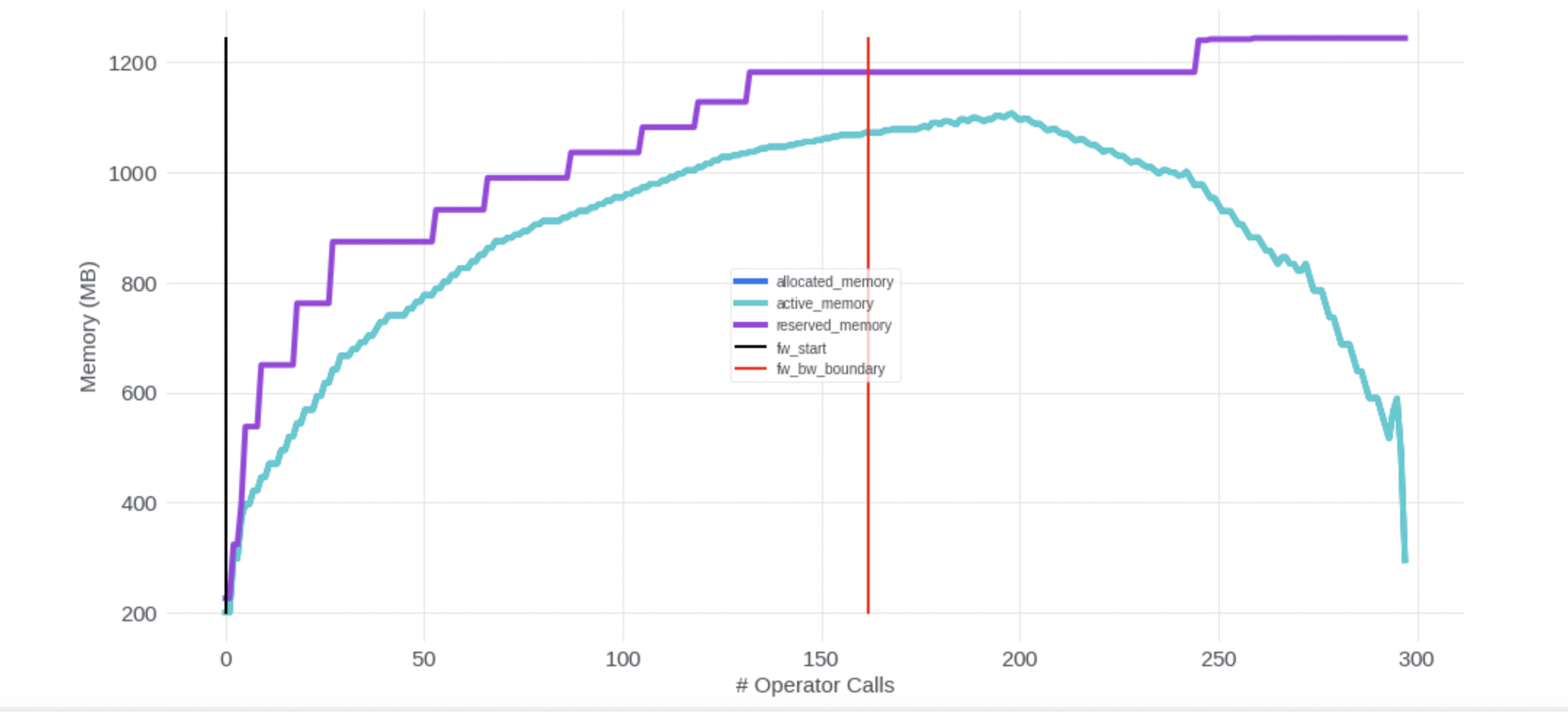
Adding a memory_tracker API to show operator level memory traces for allocated_memory, active_memory and reserved memory stats, it gave the summary about top 20 operators that generate memories as well. The implementation mainly uses torchDispatchMode and module hooks to get traces and add markers. Will add following up PRs: 1. allow tracing more than 1 iteration 2. dump json data for visualization 3. add unit test for DDP training 4. add unit test for FSDP training 5. add unit test for activation checkpointing + DDP/FSDP training 6. add traces for activation memories and top operators that generate activation memories 7. print summaries for more breakdowns like model size, optimizer states, etc 8. add traces for temporary memories or memories consumed by cuda streams or nccl library if possible 9. connect the tool with OOM memory debugging 10. add dynamic programming (dp) algorithm to find best activation checkpointing locations based on the operator level activation memory traces 11. add same traces & dp algorithm for module level memory stats, as FSDP wrapping depends on module level memories, for some model users/not model authors, if they have to apply activation checkpointing on module level, they need module level memory traces as well ====================================================== Current test result for the memory_tracker_example.py on notebook: Top 20 ops that generates memory are: bn1.forward.cudnn_batch_norm.default_0: 98.0009765625MB maxpool.forward.max_pool2d_with_indices.default_0: 74.5MB layer1.0.conv1.backward.max_pool2d_with_indices_backward.default_0: 49.0MB layer1.0.bn1.forward.cudnn_batch_norm.default_1: 24.5009765625MB layer1.0.bn2.forward.cudnn_batch_norm.default_2: 24.5009765625MB layer1.1.bn1.forward.cudnn_batch_norm.default_3: 24.5009765625MB layer1.1.bn2.forward.cudnn_batch_norm.default_4: 24.5009765625MB layer1.2.bn1.forward.cudnn_batch_norm.default_5: 24.5009765625MB layer1.2.bn2.forward.cudnn_batch_norm.default_6: 24.5009765625MB layer1.0.conv1.forward.convolution.default_1: 24.5MB layer1.0.conv2.forward.convolution.default_2: 24.5MB layer1.1.conv1.forward.convolution.default_3: 24.5MB layer1.1.conv2.forward.convolution.default_4: 24.5MB layer1.2.conv1.forward.convolution.default_5: 24.5MB layer1.2.conv2.forward.convolution.default_6: 24.5MB maxpool.backward.threshold_backward.default_32: 23.5MB layer2.0.downsample.backward.convolution_backward.default_26: 12.2802734375MB layer2.0.bn1.forward.cudnn_batch_norm.default_7: 12.2509765625MB layer2.0.bn2.forward.cudnn_batch_norm.default_8: 12.2509765625MB layer2.0.downsample.1.forward.cudnn_batch_norm.default_9: 12.2509765625MB <img width="1079" alt="Screen Shot 2022-11-10 at 10 03 06 AM" src="https://user-images.githubusercontent.com/48731194/201172577-ddfb769c-fb0f-4962-80df-92456b77903e.png"> Pull Request resolved: pytorch#88825 Approved by: https://github.com/awgu
{kind=link}
Adding a memory_tracker API to show operator level memory traces for allocated_memory, active_memory and reserved memory stats, it gave the summary about top 20 operators that generate memories as well.
The implementation mainly uses torchDispatchMode and module hooks to get traces and add markers.
Will add following up PRs:
======================================================
Current test result for the memory_tracker_example.py on notebook:
Top 20 ops that generates memory are:
bn1.forward.cudnn_batch_norm.default_0: 98.0009765625MB
maxpool.forward.max_pool2d_with_indices.default_0: 74.5MB
layer1.0.conv1.backward.max_pool2d_with_indices_backward.default_0: 49.0MB
layer1.0.bn1.forward.cudnn_batch_norm.default_1: 24.5009765625MB
layer1.0.bn2.forward.cudnn_batch_norm.default_2: 24.5009765625MB
layer1.1.bn1.forward.cudnn_batch_norm.default_3: 24.5009765625MB
layer1.1.bn2.forward.cudnn_batch_norm.default_4: 24.5009765625MB
layer1.2.bn1.forward.cudnn_batch_norm.default_5: 24.5009765625MB
layer1.2.bn2.forward.cudnn_batch_norm.default_6: 24.5009765625MB
layer1.0.conv1.forward.convolution.default_1: 24.5MB
layer1.0.conv2.forward.convolution.default_2: 24.5MB
layer1.1.conv1.forward.convolution.default_3: 24.5MB
layer1.1.conv2.forward.convolution.default_4: 24.5MB
layer1.2.conv1.forward.convolution.default_5: 24.5MB
layer1.2.conv2.forward.convolution.default_6: 24.5MB
maxpool.backward.threshold_backward.default_32: 23.5MB
layer2.0.downsample.backward.convolution_backward.default_26: 12.2802734375MB
layer2.0.bn1.forward.cudnn_batch_norm.default_7: 12.2509765625MB
layer2.0.bn2.forward.cudnn_batch_norm.default_8: 12.2509765625MB
layer2.0.downsample.1.forward.cudnn_batch_norm.default_9: 12.2509765625MB