Add neuron benchmarking to automation and other enhancements #1099
Conversation
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
413e952 to
0d37b0b
Compare
0d37b0b to
ddf6d6d
Compare
docker/Dockerfile.dev
Outdated
| && git clone https://github.com/pytorch/serve.git \ | ||
| && cd serve \ | ||
| && git checkout ${BRANCH_NAME} \ | ||
| && git checkout --track origin/release_0.4.0 \ |
There was a problem hiding this comment.
Why is the branch being hardcoded? It was parameter earlier
There was a problem hiding this comment.
This is a dev-change that should've been reverted in the cleanup, fixed.
test/benchmark/instances.yaml
Outdated
| test_vgg16_benchmark: | ||
| inf1.6xlarge: | ||
| instance_id: i-04b6adea9c066ad0f | ||
| key_filename: /Users/nikhilsk/nskool/serve/test/benchmark/ec2-key-name-6028.pem |
There was a problem hiding this comment.
Can we the keys from a common shared location and not have user specific items here?
There was a problem hiding this comment.
Removed, and this file has been added to .gitignore.
test/benchmark/instances.yaml
Outdated
| test_vgg16_benchmark: | ||
| inf1.6xlarge: | ||
| instance_id: i-04b6adea9c066ad0f | ||
| key_filename: /Users/nikhilsk/nskool/serve/test/benchmark/ec2-key-name-6028.pem |
There was a problem hiding this comment.
@nskool pls fix this line as in this test it was not required and key got generated and placed in fixed directory.
There was a problem hiding this comment.
Removed, and this file has been added to .gitignore.
| DEFAULT_REGION = "us-west-2" | ||
| IAM_INSTANCE_PROFILE = "EC2Admin" | ||
| S3_BUCKET_BENCHMARK_ARTIFACTS = "s3://torchserve-model-serving/benchmark_artifacts" | ||
| S3_BUCKET_BENCHMARK_ARTIFACTS = "s3://nikhilsk-model-serving/benchmark_artifacts" |
There was a problem hiding this comment.
@nskool pls make sure we can pass this s3 bucket as an argument.
There was a problem hiding this comment.
Since this is a non-trivial and non-breaking change, I've added it to the issue which describes changes in phase 3 of the automation: #1121
There was a problem hiding this comment.
@nskool Why is the URL change to s3://torchserve-model-serving/xxx vs your personal S3 bucket a non-trivial change? Whatever tests we have can be put in the main s3://torchserve-model-serving bucket
| 8. For generating benchmarking report, modify the argument to function `generate_comprehensive_report()` to point to the s3 bucket uri for the benchmark run. Run the script as: | ||
| ``` | ||
| python report.py | ||
| ``` |
There was a problem hiding this comment.
@nskool as discussed, it might be good to add report.py as part of the automation as well.
There was a problem hiding this comment.
Will make this part of a separate CR, with an all-inclusive report.
There was a problem hiding this comment.
This is now fixed in the current PR
30b1a68 to
6ce3107
Compare
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
docker/Dockerfile.neuron.dev
Outdated
| RUN if [ "$MACHINE_TYPE" = "gpu" ]; then export USE_CUDA=1; fi \ | ||
| && git clone https://github.com/pytorch/serve.git \ | ||
| && cd serve \ | ||
| && git checkout --track origin/release_0.4.0 \ |
There was a problem hiding this comment.
Please parameterize the branch name
docker/build_image.sh
Outdated
| DOCKER_BUILDKIT=1 docker build --file Dockerfile --build-arg BASE_IMAGE=$BASE_IMAGE --build-arg CUDA_VERSION=$CUDA_VERSION -t $DOCKER_TAG . | ||
| else | ||
| DOCKER_BUILDKIT=1 docker build --file Dockerfile.dev -t $DOCKER_TAG --build-arg BUILD_TYPE=$BUILD_TYPE --build-arg BASE_IMAGE=$BASE_IMAGE --build-arg BRANCH_NAME=$BRANCH_NAME --build-arg CUDA_VERSION=$CUDA_VERSION --build-arg MACHINE_TYPE=$MACHINE . | ||
| DOCKER_BUILDKIT=1 docker build --pull --network=host --no-cache --file Dockerfile.neuron.dev -t $DOCKER_TAG --build-arg BUILD_TYPE=$BUILD_TYPE --build-arg BASE_IMAGE=$BASE_IMAGE --build-arg BRANCH_NAME=$BRANCH_NAME --build-arg CUDA_VERSION=$CUDA_VERSION --build-arg MACHINE_TYPE=$MACHINE . |
There was a problem hiding this comment.
Please verify there is impact on the benchmark when using --network=host
There was a problem hiding this comment.
Reverted, it's not needed anymore because I've changed the neuron benchmark to use a local torchserve installation on an ec2 instance rather than a docker installation.
| The final benchmark report will be available in markdown format as `report.md` in the `serve/` folder. | ||
|
|
||
| **Example report for vgg16 model** | ||
| **Example report for vgg11 model** |
There was a problem hiding this comment.
What is the reason for switching to vgg11 here?
There was a problem hiding this comment.
The results quoted below are vgg11 results, this 'vgg16' was just a typo that was corrected.
| requests: 10000 | ||
| concurrency: 100 | ||
| backend_profiling: True | ||
| backend_profiling: False |
There was a problem hiding this comment.
Is there any reason for this change?
There was a problem hiding this comment.
Benchmarking results have been recorded so far with 'backend_profiling' False - this 'True' was only used to feature-test that specifying 'True' works. Benchmarking with backend_profiling: True gives worse results than with backend_profiling:False.
test/benchmark/tests/test_vgg16.py
Outdated
|
|
||
| INSTANCE_TYPES_TO_TEST = ["p3.8xlarge"] | ||
|
|
||
| @pytest.mark.skip() |
There was a problem hiding this comment.
Yes, apologies, a leftover from testing. Unskipped.
| ) | ||
| docker_repo_tag_for_current_instance = docker_repo_tag | ||
| cuda_version_for_instance = cuda_version | ||
| cuda_version_for_instance = None |
There was a problem hiding this comment.
Have we validated on GPU/CUDA after these changes?
There was a problem hiding this comment.
Yes, in fact validation on CPU was failing and hence this 'cuda_version_for_instance' change was a bug fix, the value should have been None. I've validated the GPU docker image is used after these changes.
|
|
||
| GPU_INSTANCES = ["p2", "p3", "p4", "g2", "g3", "g4"] | ||
|
|
||
| # DLAMI with nVidia Driver ver. 450.119.03 (support upto CUDA 11.2), Ubuntu 18.04 |
There was a problem hiding this comment.
Is this description still valid for the new AMI?
There was a problem hiding this comment.
Yes, that it still holds true.
test/benchmark/tests/utils/report.py
Outdated
| # Download the s3 files | ||
| run(f"mkdir -p /tmp/report") | ||
| run(f"aws s3 cp --recursive {s3_bucket_uri} /tmp/report") | ||
| # run(f"mkdir -p /tmp/report") |
There was a problem hiding this comment.
Do we need these commented lines?
There was a problem hiding this comment.
We do - currently 'report.py' needs to be run separately from automation. I've added a task here to automate that as well: #1121
There was a problem hiding this comment.
Fixed in the current PR now.
test/benchmark/tests/utils/report.py
Outdated
| config_header = f"{model} | {mode} | {instance_type} | batch size {batch_size}" | ||
|
|
||
| markdownDocument.add_paragraph(config_header, bold=True, newline=True) | ||
| #markdownDocument.add_paragraph(config_header, bold=True, newline=True) |
test/benchmark/tests/utils/report.py
Outdated
|
|
||
| # Clean up | ||
| run(f"rm -rf /tmp/report") | ||
| # run(f"rm -rf /tmp/report") |
There was a problem hiding this comment.
Is this needed? It might be better to put logic in code such that it can automatically create the report folder if it does not exists so that one does not have to keep commenting/uncommenting out these lines to reruns.
There was a problem hiding this comment.
Agreed, that's the plan - but will be done later as part of a couple other changes listed here: #1121. The reason is that the 'wiring' that needs to be done to automate this i.e. make the 's3 folder' available to the report.py script is non-trivial, and will need additional testing.
There was a problem hiding this comment.
This has been fixed in the current PR itself.
|
Documenting how benchmarking a CPU only model worked for me
1,2,3 just need mentions in the README 4 is a bit tricky because and could be simplified. I haven't tried local benchmarks instead of docker benchmarks yet 5 is a simple fix but is just annoying still getting a weird error https://gist.github.com/msaroufim/fb9ceb5be8ad710ae46e4464f56490c7 And did not expect to see 3 instances created on my AWS account instead of just 1 |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
|
Alright I'm really glad to see the improvements For example I was trying to run CPU benchmarks after setting In a future PR would be great to just make the S3 bucket configurable in Also an awkward change was needed in Master benchmarks throughput: ~190 im/s But it was cool because I could validate that the metrics were printed to my console That they were indeed in the S3 bucket I configured Actual metrics on the im threads = 1 branch: 267 im/s
In I tried out a GPU instance as well and that also worked easily
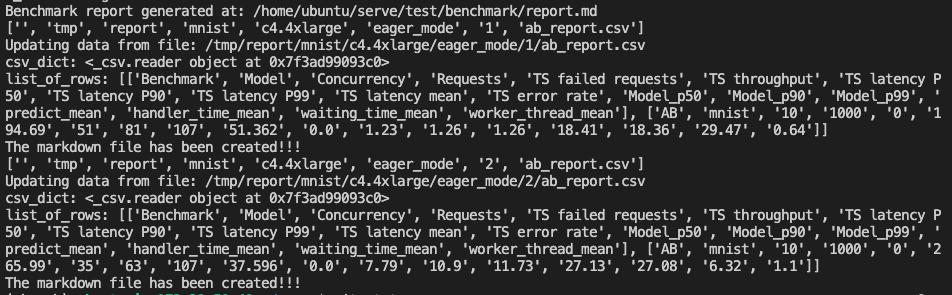
list_of_rows: [['Benchmark', 'Model', 'Concurrency', 'Requests', 'TS failed requests', 'TS throughput', 'TS latency P50', 'TS latency P90', 'TS latency P99', 'TS latency mean', 'TS error rate', 'Model_p50', 'Model_p90', 'Model_p99', 'predict_mean', 'handler_time_mean', 'waiting_time_mean', 'worker_thread_mean'], ['AB', 'mnist', '10', '1000', '0', '2253.33', '3', '5', '79', '4.438', '0.0', '1.35', '1.37', '1.37', '1.61', '1.57', '0.25', '0.92']] |

d06fa02 to
09d54a3
Compare
ec0bd82 to
ddd9d27
Compare
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
AWS CodeBuild CI Report
Powered by github-codebuild-logs, available on the AWS Serverless Application Repository |
Description
Adds support for automating benchmarks using AWS neuron for BERT model.
Fixes part of #1067
Type of change
Please delete options that are not relevant.
Feature/Issue validation/testing
Please describe the tests [UT/IT] that you ran to verify your changes and relevent result summary. Provide instructions so it can be reproduced.
Please also list any relevant details for your test configuration.
Test A
Test B
UT/IT execution results
Logs
Benchmark report
Checklist: