RAPP Speech Detection using Sphinx4
In our case we desire a flexible speech recognition module, capable of multi-language extension and good performance on limited or generalized language models. For this reason, Sphinx-4 was selected. Since we aim for speech detection services for RApps regardless of the actual robot at hand, we decided to install Sphinx-4 in the RAPP Cloud and provide services for uploading or streaming audio, as well as configuring the ASR towards language or vocabulary-specific decisions.
Before proceeding to the actual description, it should be said that the RAPP Sphinx4 detection was create in order to handle limited vocabulary speech recognition in various languages. This means that it is not suggested for detecting words in free speech or words from a vocabulary larger than 10-15 words.
Before describing the actual implementation, it is necessary to investigate the Sphinx-4 configuration capabilities. In order to perform speech detection, Sphinx-4 requires:
- An acoustic model containing information about senones. Senones are short sound detectors able to represent the specific language's sound elements (phones, diphones, triphones etc.). In order to train an acoustic model for an unsupported language an abundance of data must be available. CMU Sphinx supports a number of high-quality acoustic models, including US English, German, Russian, Spanish, French, Dutch, Mexican and Mandarin. In the RAPP case we desire multi speakers support, thus as Sphinx-4 suggests, 50 hours of dictation from 200 different speakers are necessary ref, including the knowledge of the language's phonetic structure, as well as enough time to train the model and optimize its parameters. If these resources are unavailable (which is the current case), a possibility is to utilize the US English acoustic model and perform grapheme to phoneme transformations.
- A language model, used to restrict word search. Usually n-gram (an n-character slice of a bigger string) language models are used in order to strip non probable words during the speech detection procedure, thus minimizing the search time and optimizing the overall procedure. Sphinx-4 supports two language models: grammars and statistical language models. Statistical language models include a set of sentences from which probabilities of words and succession of words are extracted. A grammar is a more ''strict'' language model, since the ASR tries to match the input speech only to the provided sentences. In our case, we are initially interested in detecting single words from a limited vocabulary, thus no special attention was paid in the construction of a generalized Greek language model.
- A phonetic dictionary, which essentially is a mapping from words to phones. This procedure is usually performed using G2P converters (Grapheme-to-Phoneme), such as Phonetisaurus or sequitur-g2p3. G2P converters are used in almost all TTSs (Text-to-Speech converters), as they require pronunciation rules to work correctly. Here, we decided to not use a G2P tool, but investigate and document the overall G2P procedure of translating Greek graphemes directly into the CMU Arpabet format (which Sphinx supports).
The overall Speech Detection architecture utilizing the Sphinx4 library is presented in the figure below:
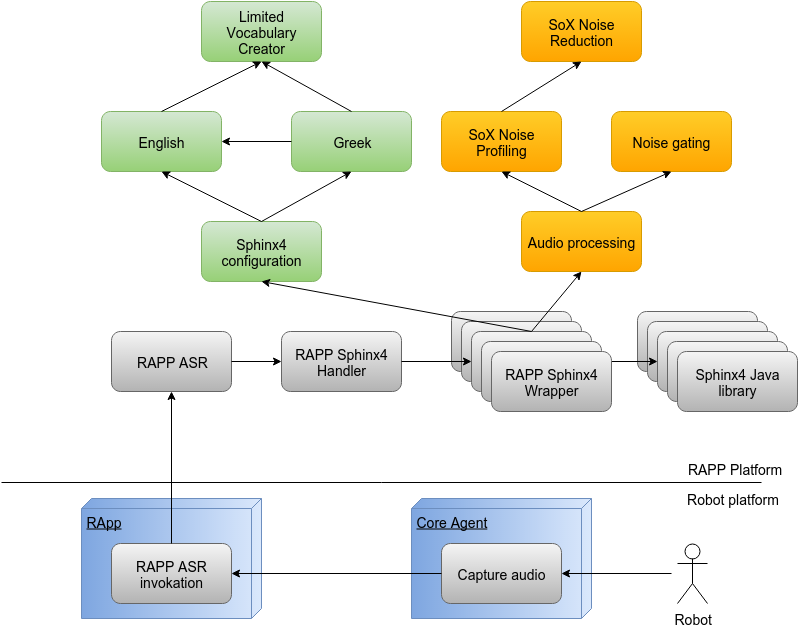
As evident, two distinct parts exist: the NAO robot and RAPP Cloud part. Let’s assume that a robotic application (RApp) is deployed in the robot, which needs to perform speech detection. The first step is to invoke the Capture Audio service the Core agent provides, which in turn captures an audio file via the NAO microphones. This audio file is sent to the cloud RAPP ASR node in order to perform ASR. The most important module of the RAPP ASR is the Sphinx-4 wrapper. This node is responsible for receiving the service call data and configuring the Sphinx-4 software according to the request. The actual Sphinx-4 library is executed as a separate process and Sphinx-4 wrapper is communicating with it via sockets.
Between the RAPP ASR and the Sphinx-4 wrapper lies the Sphinx-4 Handler node which is responsible for handling the actual service request. It maintains a number of Sphinx wrappers in different threads, each of which is capable of handling a different request. The Sphinx-4 handler is responsible for scheduling the Sphinx-4 wrapper threads and for this purpose maintains information about the state of each thread (active/idle) and each thread's previous configuration parameters. Three possible situations exist:
- If a thread is idle and its previous configuration matches the request's configuration, this thread is selected to handle the request as the time consuming configuration procedure can be skipped.
- If no idle thread's configuration matches the request's configuration, an idle thread is chosen at random.
- If all threads are active, the request is put on hold until a thread is available.
Regarding the Sphinx-4 configuration, the user is able to select the ASR language and if they desire ASR on a limited vocabulary or on a generalized one stored in the RAPP cloud. If a limited vocabulary is selected, the user can also define the language model (the sentences of the statistical language model or the grammar). The configuration task is performed by the Sphinx-4 Configuration module. There, the ASR language is retrieved and the corresponding language modules are employed (currently Greek, English and their combination). If the user has requested ASR on a limited vocabulary, the corresponding language module must feed the Limited vocabulary creator with the correct grapheme to phoneme transformations, in order to create the necessary configuration files. In the English case, this task is easy, since Sphinx-4 provides a generalized English vocabulary, which includes the words' G2P transformations. When Greek is requested, a simplified G2P method is implemented, which will be discussed next. In the case where the user requests a generalized ASR, the predefined generalized dictionaries are used (currently only English support exists).
The second major task that needs to be performed before the actual Sphinx-4 ASR is the audio preparation. This involves the employment of the SoX audio library utilizing the Audio processing node. Then the audio file is provided to the Sphinx4 Java library and the resulting words are extracted and transmitted back to the RApp, as a response to the HOP service call.
Regarding the Greek support, first a description of some basic rules of the Greek language will be presented. The Greek language is equipped with 24 letters and 25 phonemes. Phonemes are structural sound components defining a word’s acoustic properties. Some pronunciation rules the Greek language has follow:
- Double letters are two letters that contain two phonemes.
- Two digit vowels are two-letter combinations that sound like a single vowel phoneme.
- There is a special “s” letter, which is placed at the word’s end instead of the “normal” 's' letter.
- The common consonants are two common letter combinations that sound exactly like the single case letter.
- There are some special vowel combinations that are pronounced differently according to what letter is next.
- A grammatical symbol is the acute accent (Greek tonos), denoting where the word is accented.
- Another special symbol is diaeresis.
- There are some sigma rules, where if sigma is followed by specific letters it sounds like z.
Finally, there are several other trivial and rare rules that we did not take under consideration in our approach.
Let’s assume that some Greek words are available and we must configure the Sphinx4 library in order to perform speech recognition. These words must be converted to the Sphinx4-supported Arpabet format which contains 39 phonemes. The individual steps followed are:
- Substitute upper case letters by the corresponding lower case
- Substitute two-letter phonemes and common consonants with CMU phonemes
- Substitute special vowel combinations
- Substitute two digit vowels by CMU phonemes
- Substitute special sigma rules
- Substitute all remaining letters with CMU phonemes
Then, the appropriate files are created (custom dictionary and language model) and the Sphinx4 library is configured. Then the audio pre-processing takes place, performing denoising similarly to the Google Speech Recognition module by deploying the ROS services of the Audio processing node.
The RAPP Speech Detection using Sphinx component diagram is depicted in the figure.

It should be stated that the language model is created based on the ARPA model for the sentences and on the JSGS for the grammar parameters, nevertheless only pure sentences are supported (i.e. the advanced JSGF uses cannot be employed). More information on the Sphinx language model can be found here.
The Sphinx4 ROS node provides a ROS service, dedicated to perform speech recognition.
Service URL: /rapp/rapp_speech_detection_sphinx4/batch_speech_to_text
Service type:
#The language we want ASR for
string language
#The limited vocabulary. If this is empty a general vocabulary is supposed
string[] words
#The language model in the form of grammar
string[] grammar
#The language model in the form of sentences
string[] sentences
#The audio file path
string path
#The audio file type
string audio_source
#The user requesting the ASR
String user
---
#The words recognized
string[] words
#Possible error
string errorThe speech_recognition_sphinx RPS is of type 3 since it contains a HOP service frontend, contacting a RAPP ROS node, which utilizes the Sphinx4 library. The speech_recognition_sphinx RPS can be invoked using the following URI:
Service URL: localhost:9001/hop/speech_recognition_sphinx4
The speech_recognition_sphinx RPS has several input arguments, which are encoded in JSON format in an ASCII string representation.
The speech_detection_sphinx RPS returns the recognized words in JSON forma.
Input = {
“language”: “gr, en”
“words”: “[WORD_1, WORD_2 …]”
“grammar”: “[WORD_1, WORD_2 …]”
“sentences”: “[WORD_1, WORD_2 …]”
“file”: “AUDIO_FILE_URI”
“audio_source”: “nao_ogg, nao_wav_1_ch, nao_wav_4_ch, headset”
}
Output = {
“words”: “[WORD_1, WORD_2 …]
“error”: “Possible error”
}
The request parameters are:
-
language: The language to perform ASR (Automatic Speech Recognition). Supported values: -
en: English -
el: Greek (also supports English) -
words[]: The limited vocabulary from which Sphinx4 will do the matching. Must provide individual words in the language declared in the language parameter. If left empty a generalized vocabulary will be assumed. This will be valid for English but the results are not good. -
grammar[]: A form of language model. Contains either words or sentences that contain the words declared in the words parameter. If grammar is declared, Sphinx4 will either return results that exist as is in grammar or if no matching exists. -
sentences[]: The second form of language model. Same functionality as grammar but Sphinx can return individual words contained in the sentences provided. This is essentially used to extract probabilities regarding the phonemes succession. -
file: The audio file path. -
audio_source: Declares the source of the audio capture in order to perform correct denoising. The different types are: - headset: Clean sound, no denoising needed
- nao_ogg: Captured ogg file from a single microphone from NAO. Supposed to have 1 channel.
- nao_wav_1_ch: Captured wav file from one microphone of NAO. Supposed to have 1 channel, 16kHz.
- nao_wav_4_ch: Captured wav file from all 4 NAO's microphones. Supposed to have 4 channels at 48kHz.
-
user: The user invoking the service. Must exist as username in the database to work. Also a noise profile for the declared user must exist (check rapp_audio_processing node for set_noise_profile service)
The returned parameters are:
-
error: Possible errors -
words[]: The recognized words
The full documentation exists here