The goal of this project was to write lambda functions that would automatically name an EC2 instance upon its creation. A unique and memorable alias makes the server easy to track and manage within the AWS infrastructure.
There are two distinct parts to this project: a) Create a dictionary of words from which to draw the names. This dictionary must fulfill particular criteria. b) Build the AWS infrustrature to automate the task.
This was a great exersize in puzzling out problems associated with langauge data and NLTK. It also proved to be an excellent introduction into the vast world of AWS.
The words in the dictionary had to fulfill a set of requirements:
- All entries must start with the letter "H."
- The dictionary must contain no proper nouns
- The dictionary must contain no stop words
- No entries have punctuation
- All entries relatively common word (up to interpretation)
- Each lexeme must appear only once. For example, "coding" and "coded" are both forms of the same lemma, "code," so only one may may be included.
I began with a list of English words from /usr/share/dict/. While there are other lits of English words, this is comprehensive, accessible, and in a simple format, making it easy to modify. I considered an alternative approach: starting from a list of the most common English words. My thought was that this would easily fufill the common words requirement and possibly reduce the remaining work, since the list would be considerably smaller and most likely contain only root words. This would fufill the unique lexeme requriment. However, I discovered an issue. All websites offered at most only the top 5000 most frequent words, and a few small number (144) of them started with the letter "H." (A full list of English words by frequency was available at https://www.wordfrequency.info/, but for pay only.) Although there was no minimum number of entries required, I concluded that was too few and would also make for a less interesting learning experience.
Once I had the list of words, I immediately cut off all words that didn't begin with "H," all capital words, and all words with punctuation. This is simple enough using grep, e.g.:
echo word_list.txt | grep "^[a-z]+$" > final_word_list.text
results in a final word list whose entries contain lowercase letters only (and no other characters.)
I chose to do the rest of the processing in Python, since it's NLTK contains great tools for the task. NLTK has a set of stopwords, which makes removing stopwords a quick task.
The most difficult requirement was removing duplicate lexeme. At first I looked into NLTK's stemmer and lemmatizers, neither of which accomplished that goal. The stemmer chops words off at the stem, which is often a root, not a word in itself. The lemmatizer was only marginally better and relied on context to identify the part of speech of each word. In a dictionary, of course, there is no context. So, I created rules from scratch.
I complied a list of suffixes. When a regular expression matched an entry in the word list, I executed a corresponding function that returned a modified version of the word to be appended to the final set of entries. (If that form had been added previously, it wouldn't be added again, since all items in a set are unique.) Some of these suffix functions returned an empty string instead of a word, a way of signling to skip over that entry instead of appending it to the final set.
Finally, I realized that many of the entries were legitimate although obscure words. Names should be easily identifiable. Since I had no statistics on word frequency (and didn't want to purchase them,) what constituted a "common" word was up to interpretation. I decided to to remove all words over 11 chararacters, which elimated a fair portion of the obscure words. Shorter words are also overall easier to identify and remember.
Working with such a huge wordlist was an experiment, which I purposefully choose, because it would provide more puzzles and challenges to solve. The biggest issue was that it resulted in a large number of obscure words added to the final dictionary.
I also found it difficult (but fun) to form rules that accurately transformed a word containing a sufix into it's root form. For example, my gerund rule would have to transform "running" into "run." In a lot of cases, I dropped the suffixed form from the final list entirely realizing that if "running" was in the list, "run" probably was as well. However, not all words that end in "ing" contain a suffix. "Cling" is a counter example. So, that solution is flawed. A related issue is that each suffix transforming function accept the final dictionary of accepted words as a parameter. (The final list is still incomplete.) This is clunky and time/space consuming. Ideally each suffix transforming function would be independent of the final list and depend solely on the word being transformed.
In the future, I would further refine each suffix transforming function to more accurately process the data, so as to both not eliminate viable entries and not duplicate entries. I structured the code, so each function is independent and flexible - it's easy to build upon.
The biggest and most effective change is to use a smaller word list. One normally won't have more than 20 EC2 instances per region. If we add another parameter to this project and set the maximum number of entries to N < 500, the results are common and recognizable words. (500 is an arbitrary number but well above what most architectures would call for.)
Running the script on the most common 144 words that start with "H" results in very little prepocessing, since most words do not contain suffixes, and only a couple of duplicate lexememes (e.g. "hunt" and "hunter.")
- Every EC2 instance must automatically be assigned a name upon creation
- Each name must come from the dictionary of words described in Section A
- All servers that have not been terminated must have unique names
Executing this task requires the following AWS services:
- EC2 instances
- Lambda function(s) that get triggered when an EC2 instance changes stage
- Cloudwatch to monitor the state of the EC2 instances and to trigger the lambda function
- A table in DynamoDB to hold the dictionary of names
I first wrote a script that would load the dictionary of words into the database. All my scripts are in Python and Boto3 (AWS's sdk) in keeping with the language of the firest section of this project. A queue is the obvious solution to the requirement of uniquely named servers. Every active server must have a unique name, but names can be used more than once. When a server is created, a name gets pulled from the queue, and when a server is terminated, it gets added to the end of the queue. AWS has a queuing service, but it's not built for long term data. (Messages have a maximum life of 14 days.) As I'm not a database engineer, I quickly realized that learning how to use a database table as a queue would be beyond the scope of this project. Instead, I created two lambda functions: one would pull a name from the database, assign it to a new server and delete that item from the database. A second lambda function would trigger when an EC2 instance is terminating. The function would add an entry to the database with the name of the server, putting that name back in circulation. The order items are drawn or added back to the database table doesn't matter, as the names of the servers will always be unique.
The following diagram illustrates the 2 processes:
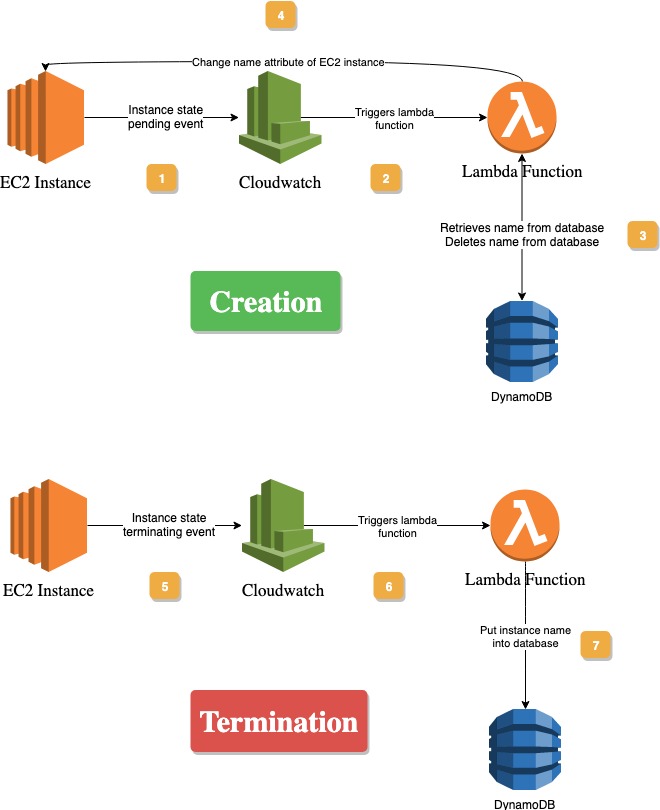
- The new EC2 instance gets created. It's state is pending.
- Cloudwatch triggers a lambda function once any EC2 instance enters the pending state
- The lambda function has access to both DynamoDB and EC2. It pulls a nanme from the database
table.scan(Limit=1) - The identity of the EC2 server was passed to the lambda function as the event. "Name" is one of the tags assigned to an instance. It's assigned the new value that was just pulled from the server. Finally, the that entry is deleted from the database
- An EC2 instance gets destroyed and it's state becomes terminating.
- Cloudwatch triggers a lambda function whenever any EC2 instance state becomes terminating.
- The lambda function gets passed the triggering instance's information. It puts it's name (
table.put_item()) back into the database
The two lambda function effectively assign unique names to each EC2 instance. I would improve the script that loads the dictionary into the dataabase. It currently adds only one item at a time, which is time consuming, when it could add items in bulk.
In the future, I would also add more error handling to my lambda functions. What would happen when a name gets assigned to a server but doesn't successfully delete from the database? Or when names don't get pulled from the database? It's easy to see how duplicates could arise or servers with empty names.
Another potential improvement would be to implement a proper queue where entries woudl have a time stamp and get withdrawn in the order of creation and later added to the tail of the queue.