The question in tutorial optimizers_conditionalgradient frobenius_norm graph and pytorch version of me #1293
Description
I am looking for the tutorial https://github.com/tensorflow/addons/blob/master/docs/tutorials/optimizers_conditionalgradient.ipynb
And the graph about frobenius norm calculate in this way
def frobenius_norm(m):
"""This function is to calculate the frobenius norm of the matrix of all
layer's weight.
Args:
m: is a list of weights param for each layers.
"""
total_reduce_sum = 0
for i in range(len(m)):
total_reduce_sum = total_reduce_sum + tf.math.reduce_sum(m[i]**2)
norm = total_reduce_sum**0.5
return norm
and which is obtain by
CG_get_weight_norm = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda batch, logs: CG_frobenius_norm_of_weight.append(
frobenius_norm(model.trainable_weights).numpy()))
And I want to ask is that
1.when in the network update , we calculate the frobenius norm by gt(gradient value) , is the "model.trainable_weights" equal to gradient value?
2. The update formula is
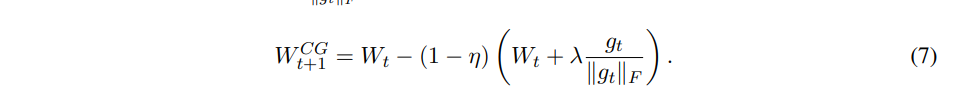 by the paper
by the paper
And this means that each layer update by this rule, and why the definition above calculate frobenius norm by add all layer together not sperately? (which means each epoch has 6 frobenius norm , beacuse there have 6 parameter according to network architecture)