Pattern matching messes the network architecture wih custom quantization #550
Description
Hi,
I am trying to perform custom quantization for a n/w with Conv+BN+ReLU pattern. As expected, this pattern is matched and then replaced. E.g. Consider the following model definition
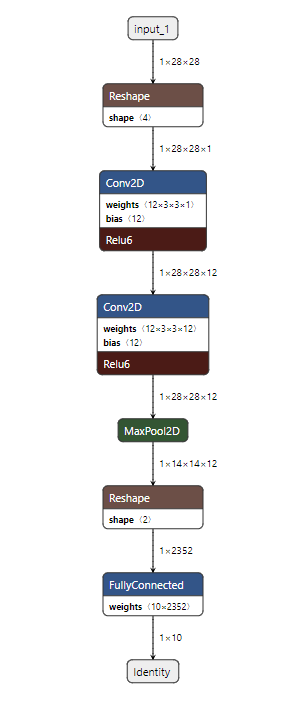
With custom quantization, this model architecture is completely messed up as shown below. Here I am showing only the back to back [Conv+BN+ReLU] patterns for better visibility.
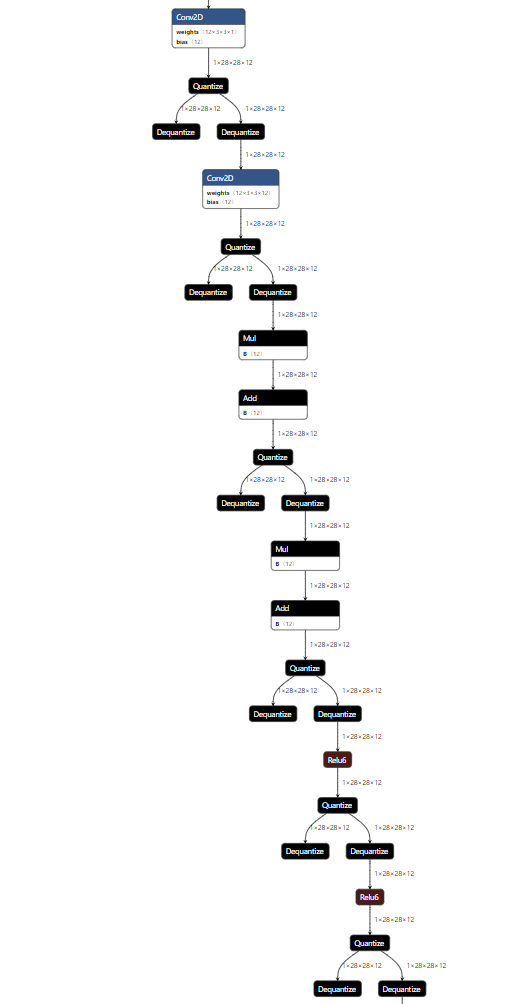
As we can see above, two Conv layers come back to back, followed by two BN and two ReLU. After looking into the matching part, i figured out that there is some indexing error while replacing a matched pattern. this is happening in line# 377 of tensorflow_model_optimization/python/core/quantization/keras/graph_transformations/model_transformer.py.
Current implementation
first_layer_removed = layers_to_remove[-1] # layers_to_remove is reversed.
Proposed change
first_layer_removed = layers_to_remove[0] # layers_to_remove is reversed.
Code to reproduce the issue
I have modified the example code a bit to reproduce the issue.
####
import tensorflow as tf
import numpy as np
import tensorflow_model_optimization as tfmot
from tensorflow import keras
from tensorflow_model_optimization.python.core.quantization.keras.default_8bit import default_8bit_quantize_configs
quantize_annotate_layer = tfmot.quantization.keras.quantize_annotate_layer
quantize_annotate_model = tfmot.quantization.keras.quantize_annotate_model
quantize_scope = tfmot.quantization.keras.quantize_scope
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), use_bias=False, activation=None, padding='same'),
keras.layers.BatchNormalization(),
keras.layers.ReLU(max_value=6.0),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), use_bias=False, activation=None, padding='same'),
keras.layers.BatchNormalization(),
keras.layers.ReLU(max_value=6.0),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
#save the float model
converter = tf.lite.TFLiteConverter.from_keras_model(model)
float_tflite_model = converter.convert()
float_file = 'float.tflite'
with open(float_file, 'wb') as f:
f.write(float_tflite_model)
#Quantization
LastValueQuantizer = tfmot.quantization.keras.quantizers.LastValueQuantizer
MovingAverageQuantizer = tfmot.quantization.keras.quantizers.MovingAverageQuantizer
class CustomQuantizeConfig(tfmot.quantization.keras.QuantizeConfig):
# Configure how to quantize weights.
def get_weights_and_quantizers(self, layer):
return [(layer.kernel, LastValueQuantizer(num_bits=8, symmetric=True, narrow_range=False, per_axis=False))]
# Configure how to quantize activations.
def get_activations_and_quantizers(self, layer):
return [(layer.activation, MovingAverageQuantizer(num_bits=8, symmetric=False, narrow_range=False, per_axis=False))]
def set_quantize_weights(self, layer, quantize_weights):
# Add this line for each item returned in `get_weights_and_quantizers
# in the same order
layer.kernel = quantize_weights[0]
def set_quantize_activations(self, layer, quantize_activations):
# Add this line for each item returned in `get_activations_and_quantizers`
# , in the same order.
layer.activation = quantize_activations[0]
# Configure how to quantize outputs (may be equivalent to activations).
def get_output_quantizers(self, layer):
return []
def get_config(self):
return {}
def annotate_custom_quantization(layer):
if isinstance(layer, (tf.keras.layers.Conv2D, tf.keras.layers.Dense)):
return quantize_annotate_layer(layer, CustomQuantizeConfig())
elif isinstance(layer, (tf.keras.layers.BatchNormalization)):
return quantize_annotate_layer(layer, default_8bit_quantize_configs.Default8BitOutputQuantizeConfig())
else:
return quantize_annotate_layer(layer)
def apply_custom_quantization(model):
# Use `tf.keras.models.clone_model` to apply `apply_quantization_to_dense`
# to the layers of the model.
annotated_model = tf.keras.models.clone_model(
model,
clone_function= annotate_custom_quantization,
)
# `quantize_apply` requires mentioning `TIDLQuantizeConfig` with `quantize_scope`:
with quantize_scope({'CustomQuantizeConfig': CustomQuantizeConfig}):
# Use `quantize_apply` to actually make the model quantization aware.
quant_aware_model = tfmot.quantization.keras.quantize_apply(annotated_model)
return quant_aware_model
q_aware_model = apply_custom_quantization(model)
#save the quant model
converter = tf.lite.TFLiteConverter.from_keras_model(q_aware_model)
quant_tflite_model = converter.convert()
quant_file = 'quant.tflite'
with open(quant_file, 'wb') as f:
f.write(quant_tflite_model)
###
System information Linux
TensorFlow version (installed from source or binary): 2.2(binary)
TensorFlow Model Optimization version (installed from source or binary): 0.3 (binary)
Python version: 3.7