This repository was archived by the owner on Jul 7, 2023. It is now read-only.
This repository was archived by the owner on Jul 7, 2023. It is now read-only.
LayerNorm is extremely time consuming when computing gradient #149
Description
Hi @lukaszkaiser I use run_metadata to generate timeline for the transformer model, and check which block is time consuming. I have found that layer_norm is extremely cost in gradient computation, as showed in the figure:

The SymbolicGradient in red circle is the gradient computation of the layer norm for each encoder and decoder layer. It nearly cost most of the time. And in feed forward stage, it's not that time consuming, but also heavy, showed in this figure:
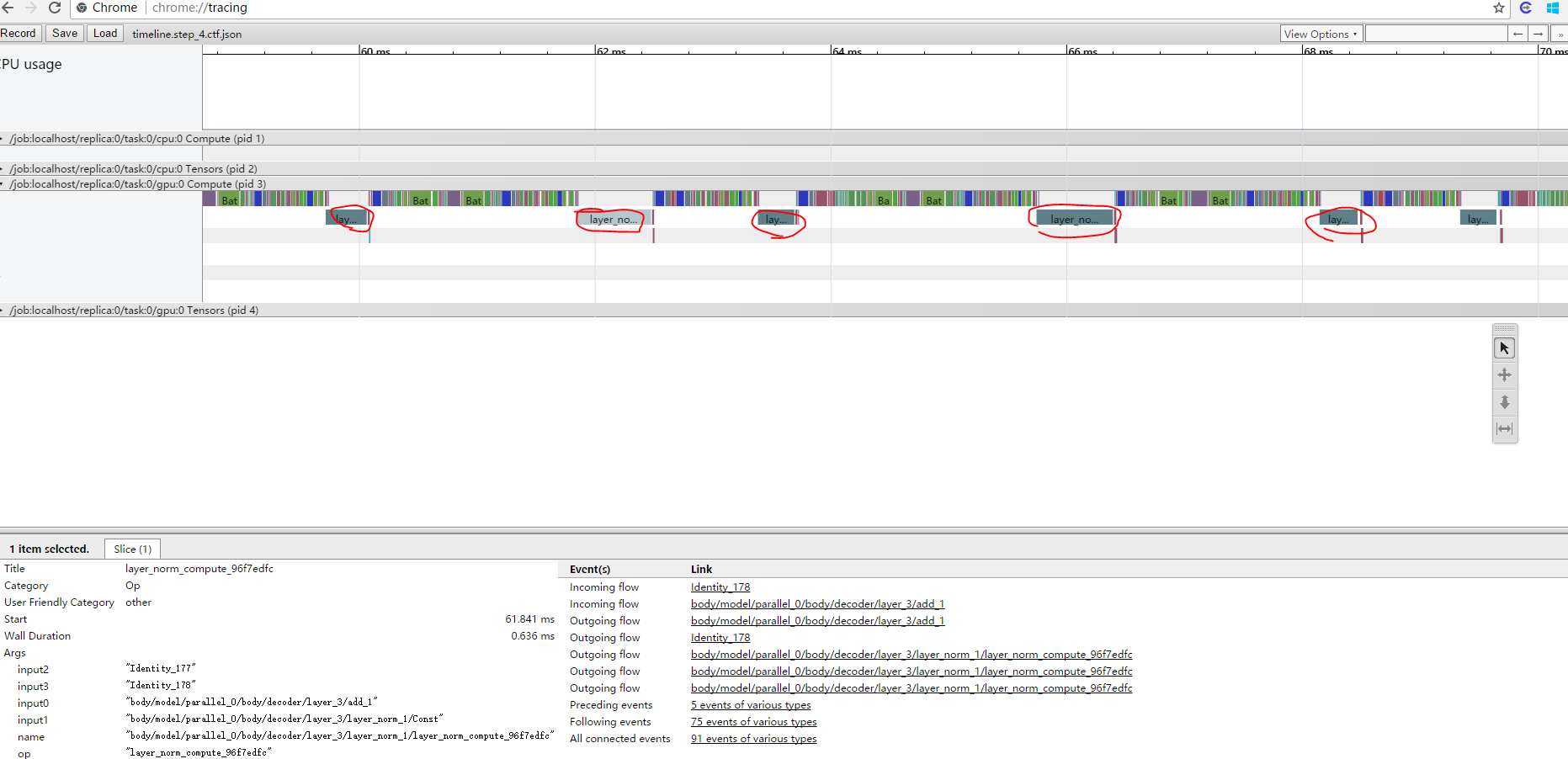
I have check the layer norm implementation, and found that you define the "layer_norm_compute" and "layer_norm_compute_grad" function by yourself.
So I don't quite understand why the layer norm is so time consuming, do you have any ideas?