Add DxBVHSpace #58
Add DxBVHSpace #58
Conversation
Add a new space based on a dynamic AABB tree. The AABB tree implementation is a slightly modified port of https://github.com/turbulenz/turbulenz_engine/blob/master/tslib/aabbtree.ts
|
Cool! I added the code to the main branch. I also added some creation methods (also for SAPSpace2) to the OdeHelper factory class, including some basic JavaDoc. |
|
I also added a comment on the Wiki. If you have time, maybe you could double check it? Technically I'm wondering how the BVH tree works. It seems that the term BVH is not very specific and simply denotes any index structure that is a 'Bounding Volume Hierarchy'. If you had a look at my TinSpin project, it contains R-Tree, STR-Tree and R*Tree, they are all in the class of BVH trees (except that TinSpin has some optimization for more than 3 dimension, which may hurt when using only 3D). While porting the code, did you recognize any specific type of tree in the BVH? |
|
Hi Til, Yes, BVH is just an umbrella term for any type of hierarchical space partitioning based on any kind of bounding volumes like spheres, AABBs, OBBs etc. There are also some ideas how to avoid tree rebuilding - see e.g. https://www.codeproject.com/Articles/832957/Dynamic-Bounding-Volume-Hiearchy-in-Csharp) but I could not make it run fast enough. In my tests it was faster to use a stackless tree (one containing escape indices) and rebuild the whole tree. Some more references on AABB trees: |
|
Interesting, thanks for the details :-). My background is less in computer graphics but more in databases, where these structures are called R-Trees. It seems that the AABB tree (as described in the 'azurefromthetrenches' article) is identical to an R-Tree, except that R-Trees have in the inner nodes usually 10-20 children, rather than just 2. The different variants of R-Trees (STR-Tree, R*Tree) vary only in how they determine the best branch for insertion of new AABB and how to handle removal. For example, STR-Tree (actually: STR-Loaded-R-Tree = sort-tile-recursive loaded R-Tree) are bulk loaded, this allows them to find a near optimal structure for the tree (optimal for searches). The bulk loading (building the tree from scratch) is also very fast. However, the tree does not behave well with removal and insertion of individual elements. R*Trees are much better for dynamic updates, but they are a bit slower during the initial loading process. Due to the insertion/update algorithm, the R*Tree does not get slower with ongoing updates of it's elements. In fact, it can often be observed that it actually gets faster. Generally, the larger 'inner' nodes of all R-Trees variants also mean that most of its leaf nodes or sub-nodes can be resized (if an element moves) without having to resize the parent node. This should make continuing updates quite fast. |
This PR adds a new space based on a dynamic AABB tree.
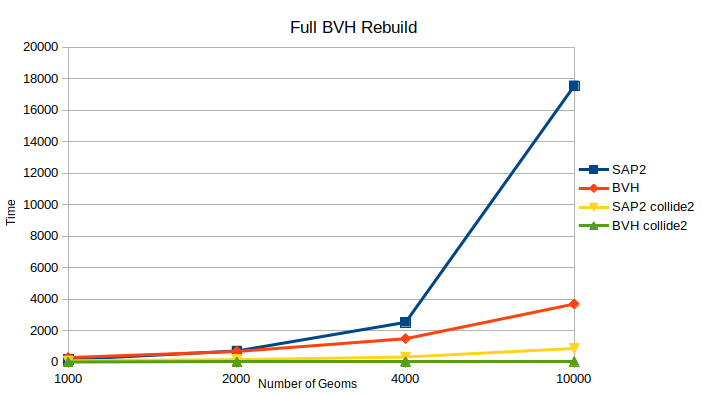
Even though the existing DxSAPSpace2 works quite well for small and medium-sized worlds (up to roughly 1500-2000 geoms), it does not scale well when the worlds grow beyond that. The attached graphs were created based on the output of SpacePerformanceTest and clearly show the issue.
On the other hand, BVH space seems to address the scalability issue much better.
I tried to keep the implementation as simple as possible. I have found a neat dynamic stackless AABB tree implementation in Turbulenz Engine (https://github.com/turbulenz/turbulenz_engine/blob/master/tslib/aabbtree.ts) which is licensed under the MIT license and I ported it to Java.
The implementation tends to rebuild the tree quite often, but the rebuild process is relatively fast and the data structures quite efficient. There are also a few minor improvements introduced by me compared to the original implementation in Typescript.