Conversation
I don't see anything obvious, but this is slightly worrying in my opinion. 504 seconds for 70 documents is a lot, especially considering that some of our organisations (e.g. parliament) have around 60k documents. We may want to profile this code to find out what's taking so long and to see if we can come with a solution for it to run faster before merging this PR. I'd be happy to help you with that if needed, though |
|
There was a problem hiding this comment.
this will stop the yielding if any of the rows does not have a text column
There was a problem hiding this comment.
you can add it now by document.get('uri', None)
There was a problem hiding this comment.
sam added this as 'url' in his latest PR so using that instead of 'uri'
|
Also note that this change does not affect the Reach tool as you would need to change the airflow task exact match. You need to search in the full text index not only in reference section index. You should add this before we merge. |
 nsorros
left a comment
nsorros
left a comment
There was a problem hiding this comment.
You need to implement the change for the Ariflow DAG as well
|
There is a package I used in a previous role which is significantly faster than regex, and could be used in |
|
Found it We had good results with this. https://www.analyticsvidhya.com/blog/2017/11/flashtext-a-library-faster-than-regular-expressions/ |
There was a problem hiding this comment.
@hblanks could you check that these lines are performing as you think they should/are parts of it redundant? My first thought is that if document[section_column]: should make the try redundant (i.e. if it passes the if then it should also pass the try in this case)? And as @nsorros says below, if there is no 'sections' part of the dict for a document then this will stop all the rest of the documents being processed.
|
@SamDepardieu or @hblanks please can you check my commit changing the airflow stuff if you have time? Tests passed, but I'm not confident the arguments of |
|
also (@ivyleavedtoadflax @SamDepardieu ) I've given up on making the local running of refparse quicker in this PR since it won't effect the product performance anyway. I've created an issue #257, if someone wants to pick it up in the future. |
There was a problem hiding this comment.
es_index is not a good name, all indices in elastic search are es_index. i suggest full_text_index or es_full_text index
Did you run the DAG? Did the exact matcher found matches? Test pass as I think there are no tests testing the exact matcher. |
The best way to test the dag is to run the |
There was a problem hiding this comment.
for simple tests like this it is probably preferable to use pytest which means you can do away with creating a test class, and define everything as functions. It's no biggie, especially because pytest understand unittest tests, but pytest is much more user friendly to write.
|
The policy test dag is broken (not even running) and I'm not sure why. The error in Airflow is |
|
@lizgzil - yes, the place for debugging dags is unfortunately in the airflow web (and maybe scheduler logs), using Your branch also could stand to be rebased on top of the reach rename. Would you like it if I did this and after we debugged the DAG together? |
@hblanks Yes please, thatd be great! |
552db8d to
2a18a80
Compare
|
The error log for an full text task is: Not sure if this is to do with my connection or not (after a quick google of what a socket.gaierror is? Will try with my dns not being 8.8.8.8 when I get back off holiday, but if anyone else want to try running the test-dag in the mean time then that's be great :) |
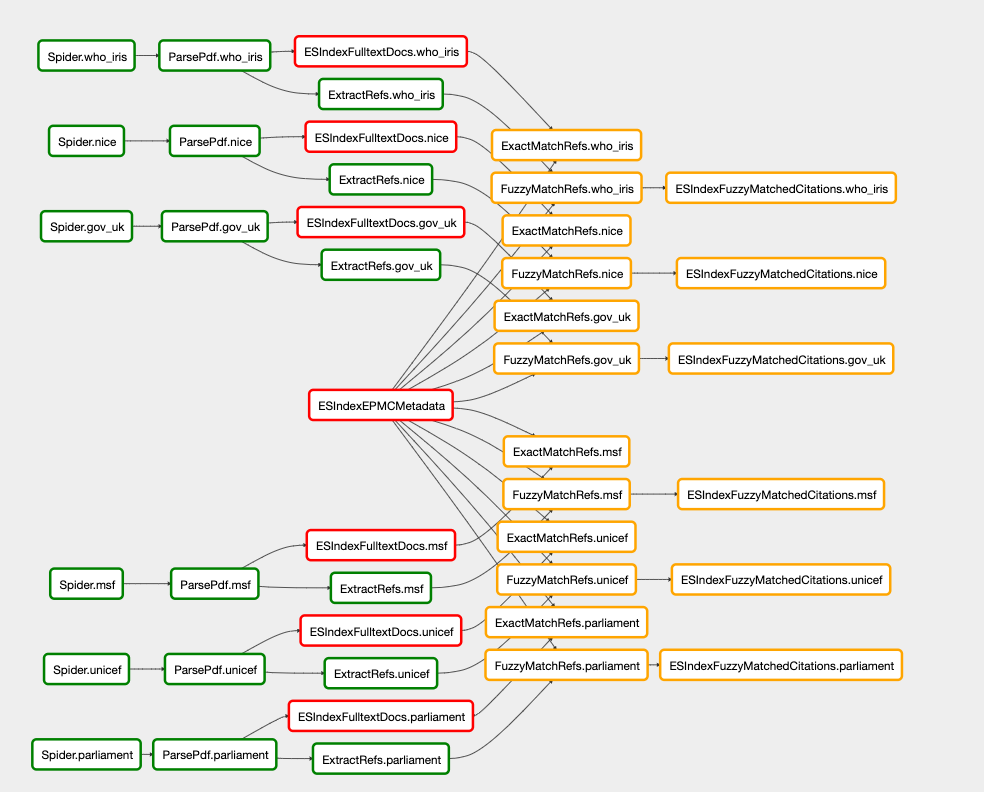
…ns, and add an optional argument in filemanager which allows you to decide which columns to include in the scraper output dictionary. This will mean we can include the text column needed to exact match on all the text, rather than just the sections
…t the name of the sections column is called, create brand new function 'transform_scraper_text_file' whcih specifically transforms for the text column in the scraper, adding new argument 'scraping_columns' to get_file which deals with allowing the user to query any column names theyd like
…policy.py, and define threshold variable
edb68cc to
edc0def
Compare
- The new connection method added the port twice to the host, leading the lib to try to connecto 'http://elasticsearch9200:9200. Changed the conenction method to split the port from the configuration variable.
…EPMCMetadata task, query correct column names in the exact match, save publications doi and pmid is exact match output, add logger information, fix keys for elasticsearch paths
|
Thanks to @SamDepardieu and @hblanks I've fixed my issues with Airflow. I ran It'd be great to get this merged so we could see if the policy-test dag succeeds not using my computer, so a review of the code / suggestions on how to speed up performance / help fixing issue #183 would be very much appreciated :) |
…c, where pdfs will be interpreted differently
|
@lizgzil - thanks for keeping this going. A couple thoughts:
So, my two cents would be that we create a separate dag, |
|
OK! This branch is rebased to a new branch,
|
|
Closing this and opening a rebased version #285 |
Fix #202
Description
This PR adapts the code to look for exact matches in all the policy text, rather than just in the references sections.
get_scraping_resultsin file_manager.py which allows you to input which columns to include in the scraper output dictionary. This will mean we can include the text column needed to exact match on all the text. I did this rather than just updating the global variableSCRAPING_COLUMNSwith 'text' since for the fuzzy match it is unneeded to store the large text data in memory.transform_scraper_text_fileinrefparse.pyto specifically transform the scraped full text for the exact match. This function is v simliar totransform_scraper_file, but I chose to create another function rather than using an if statement in the same one - perhaps this would be better though?exact_match_refs_operator.pyandpolicy.py).test_pdf_objectsto allow for these tests to be run (or skipped) on a mac (this should be fixed properly at some point, see issue Fix PDF extraction for OS X(in pdf_parser.py) #273 )Type of change
Please delete options that are not relevant.
Fix #(issue)to your PR)Running time increases a lot!
A ran locally for the 70 documents in the latest MSF scrape, using:
this took 504 seconds and finds 10 doc-publication matches.
Without these changes this took 8 seconds and found 2 doc-publication matches (reassuring also found in the 10 full text search matches).
pip install spacyandpython -m spacy download en_core_web_sm) but aborted trying this out, since in airflow we dont need it, so it doesnt matter if refparse ran locally is slowI've created an issue #257, if someone wants to pick it up this performance issue in the future.
How Has This Been Tested?
I ran:
it took about 3 hours to run and processed 5377194 publications and found 8132 matches.
I noticed my results have duplicates in, fixing this might help speed things up if we delete duplicate policy docs before the exact matcher runs. I added some info about this duplication to issue #183