This is WIP. For now, it's C++ library without documentation, but when I finish it should have Doxygen comments and Python bindings (using pybind)
HWDG is a graph implementation written in C++ with heavy emphasis on time complexity. Internally, it uses unordered maps from STL to store nodes and edges. Because of this, it is very efficient when it comes to adding new nodes/edges, or checking if an edge exists within a graph (constant time complexity for each). The downside of this approach is space-complexity.
- Graph representation using list of successors (except list is replaced with map)
- Serialization of graphs (and most of other types)
- Addition of edge, removal or check of existence has constant time complexity.
- Heap-based Dijkstra algorithm.
- Bellman-Ford algorithm.
- Graph union, intersection, difference, several algorithms for graph similarity check.
- and more.
Graphs are built using Nodes (also called Vertices in literature) and weighted Edges that points from source Node to target Node. Two edges are considered identical if their source and target nodes have the same ID - weight is omitted during comparison. Nodes are identified by ID - unsigned 32bit integer. If you want to store some other datatype inside your graph, like strings, you can use externally implemented dictionary and hashing functions to do so. For any node A and B, within the graph, there can be only one edge with source node A and target node B.
Nodes DO NOT have to have consecutive ID numbers, I've been using such in examples only for simplicity. It's an unordered map, so ID can be any unsigned 32bit integer.
Given there's no documentation yet, I've decided to make quick instruction on how-to-use.
Following code generates a random graph of size 10 with density=50%, minimal weight of edge=10 and maximal=400, with loops allowed. Then, a string representation of this graph is displayed to standard output. Finally, the graph is saved to file "graph" in binary form.
#include <iostream>
#include "hwdg.hpp"
int main()
{
HWDG::Graph graph = HWDG::RandomLowDensityGraph(10, 0.5, 10, 400, true);
std::cout << "Generated random graph: " << graph.str();
HWDG::SaveGraphBinFile(graph, "graph");
return 0;
}Let's load previously generated graph, generate new one, and try some basic operations: union, difference, intersection
#include <iostream>
#include "hwdg.hpp"
int main()
{
HWDG::Graph graph_a = HWDG::RandomGraph(10, 0.5, 10, 400, true);
HWDG::Graph graph_b = HWDG::LoadGraphBinFile("graph.txt");
std::cout << "Union: " << HWDG::Union(graph_a, graph_b).str() << std::endl;
std::cout << "Difference: " << HWDG::Difference(graph_a, graph_b).str() << std::endl;
std::cout << "Intersection: " << HWDG::Intersection(graph_a, graph_b, 0.5).str() << std::endl;
return 0;
}And now, let's create the graph manually:
#include <iostream>
#include "hwdg.hpp"
int main()
{
// Creating blank graph
HWDG::Graph graph;
// Creating list of nodes (vertices)
HWDG::Node n[6] = { HWDG::Node(0), HWDG::Node(1), HWDG::Node(2), HWDG::Node(3), HWDG::Node(4), HWDG::Node(5) };
// Adding nodes to graph
graph.add(n[0]);
// It supports initializer list too
graph.add({ n[1], n[2], n[3], n[4], n[5] });
// Adding edges
graph.add(HWDG::Edge(n[0], n[1], 3)); // Creating edge from n[0] to n[1] with weight=3
graph.add({ // initializer list is supported here too
HWDG::Edge(n[0], n[4], 3),
HWDG::Edge(n[1], n[2]), // if weight isn't specified, it defaults to 1
HWDG::Edge(n[2], n[3], 3),
HWDG::Edge(n[2], n[5], 1),
HWDG::Edge(n[3], n[1], 3),
HWDG::Edge(n[4], n[5], 2),
HWDG::Edge(n[5], n[0], 6),
HWDG::Edge(n[5], n[3], 1)
});
// Getting some information
std::cout << "Density: " << graph.density() << std::endl
<< "Nodes: " << graph.size_nodes() << std::endl
<< "Edges: " << graph.size_edges() << std::endl
<< "Sum of weights: " << graph.weight_sum() << std::endl
<< "Has negative weights: " << graph.has_negative_weights() << std::endl;
// Check for nodes/edges
std::cout << "Has node 3? " << graph.has(n[3]) << std::endl
<< "Has edge 2->3? " << graph.has(HWDG::Edge(n[2], n[3])) << std::endl
<< "Has edge 3->2? " << graph.has(HWDG::Edge(n[3], n[2])) << std::endl;
// Saving to file in text form
HWDG::SaveGraphTxtFile(graph, "manual.txt");
return 0;
}Now, Dijkstra algorithm. I'll use the graph from the previous example (which was saved in manual.txt)
#include <iostream>
#include "hwdg.hpp"
int main()
{
HWDG::Graph graph = HWDG::LoadGraphTxtFile("manual.txt");
try {
HWDG::Dijkstra vessel(graph, HWDG::Node(0)); // Dijkstra algorithm is executed in constructor
auto pathtable = vessel.Results();
std::cout << "Pathtable: node_id path_weight previous_node" << std::endl << pathtable.str() << std::endl;
HWDG::Path path_to_node_3 = pathtable.GetPath(HWDG::Node(3));
std::cout << "Path to node 3: " << path_to_node_3.str() << std::endl;
}
catch (const std::invalid_argument& e)
{
// This section will be triggered if graph contains negative edges
std::cout << "Exception occured: " << e.what() << std::endl;
}
return 0;
}Traversing graph (through nodes and edges originating from each node)
#include <iostream>
#include "hwdg.hpp"
int main()
{
HWDG::Graph graph = HWDG::LoadGraphTxtFile("manual.txt");
for (const auto& node : graph)
{
for (const auto& edge : node)
{
std::cout << "Traversing: " << node.id() << " - " << edge.str() << std::endl;
}
}
return 0;
}You could see in examples above Save/LoadGraphTxtFile functions. Those are wrappers for more raw functions that allow you to store most of datatypes in files (or streams). All serialization functions are written as static member functions of classes, and have no checksum control or any sanity check for loaded data, so be careful.
SaveTxt stores datatype with basic string representation that can be viewed in any text editor, and it's actually a viable way to create small graphs. Txt representation also works the same for any computer architecture, regardless of big endian / little endian. Downsides are: it's slower and wasteful when it comes to space.
SaveBin stores as little data as necessary, representing attributes with their binary form. It's fast and space efficient, but you can't even safely open such files, and it depends on computer architecture.
#include <iostream>
#include <fstream>
#include "hwdg.hpp"
int main()
{
std::ofstream txt_file; txt_file.open("serial.txt"); // File to save TXT representation
std::ofstream bin_file; bin_file.open("serial", std::ios::out | std::ios::binary); // File to save BIN representation
HWDG::Node node(420);
HWDG::Node::SaveTxt(txt_file, node); // Readable and platform-independant, but slow and spaceful way of serialization
HWDG::Node::SaveBin(bin_file, node); // Unreadable and platform-dependant, but fast and compact way of serialization
HWDG::Edge edge(HWDG::Node(0), HWDG::Node(1));
HWDG::Edge::SaveTxt(txt_file, edge);
HWDG::Edge::SaveBin(bin_file, edge);
return 0;
}#include <iostream>
#include <fstream>
#include "hwdg.hpp"
int main()
{
std::ifstream txt_file; txt_file.open("serial.txt");
std::ifstream bin_file; bin_file.open("serial", std::ios::in | std::ios::binary);
HWDG::Node n1 = HWDG::Node::LoadTxt(txt_file);
HWDG::Node n2 = HWDG::Node::LoadBin(bin_file);
HWDG::Edge e1 = HWDG::Edge::LoadTxt(txt_file);
HWDG::Edge e2 = HWDG::Edge::LoadBin(bin_file);
return 0;
}Operating on graphs is fast. All basic operations are implemented properly, with constant/linear complexity. Pathfinding algorithms are also well-implemented, with Dijkstra complexity equal nodes*ln(nodes). Below I've attached results of the performance test:
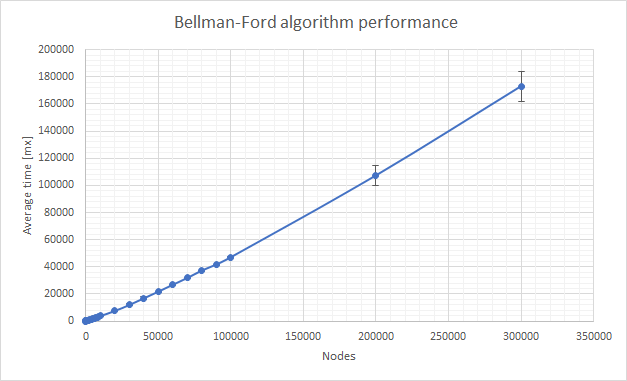
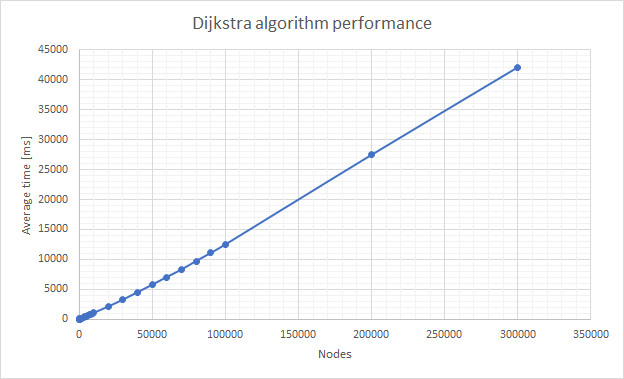
Test were conducted for fixed amount of edges per node (100), minimal weight of edge (50) and maximal weight (500), repeated for 10 different, randomly generated graphs. Standard deviation for the Dijkstra algorithm was negligible and isn't included in the chart.
While time complexity of my implementation is good, space complexity is not. Here are some graph sizes I've tested:
20000 nodes, density 0.1 ⇾ 9.6 GB of RAM occupied
10000 nodes, density 0.2 ⇾ 5.1 GB of RAM occupied
5000 nodes, density 0.5 ⇾ 3.3 GB of RAM occupied
1000 nodes, density 1.0 ⇾ 250 MB of RAM occupied
This is because I'm using hashtables, not only to store nodes in the graph, but also to store edges for each node. Note that for 20k nodes and density 0.1, it still means there are 2000 edges per node, totaling to 4 M edges.