如果你是 Codex,并且用户让你把本仓库集成到某个项目里:请阅读 AI_INSTALL.md。
下面内容是给人看的,AI无需阅读。
大家也知道,Codex 现在模型越来越叼,干活越来越猛,写代码、拆任务、审方案那叫一个丝滑。
但问题也很现实:模型越叼,额度烧起来越快。
穷则思变,富则...算了,富哥就不需要用这套工作流了!
于是有了这套穷鬼工作流:让 Codex 继续当最聪明的 leader,负责规划、拆解、调度和验收;真正吃 token 的脏活累活,交给 Codex 子代理里的 Claude Code,再通过 CC Switch 把后端切到 DeepSeek。
这样一来,Codex Plus 基本就可以爽用无忧。主线程保持清醒,子代理疯狂干活,DeepSeek 靠夸张缓存命中率把成本压下去,长任务、多代理、大范围代码探索都能放开玩。
这一切都基于 DeepSeek 的离谱低价!六千万token的使用量,缓存命中98.5%,花费俩块钱,按照这套工作流,有codex统筹规划和结果验收,子代理只需要无脑干活,用deepseek 4 flash模型都绰绰有余。
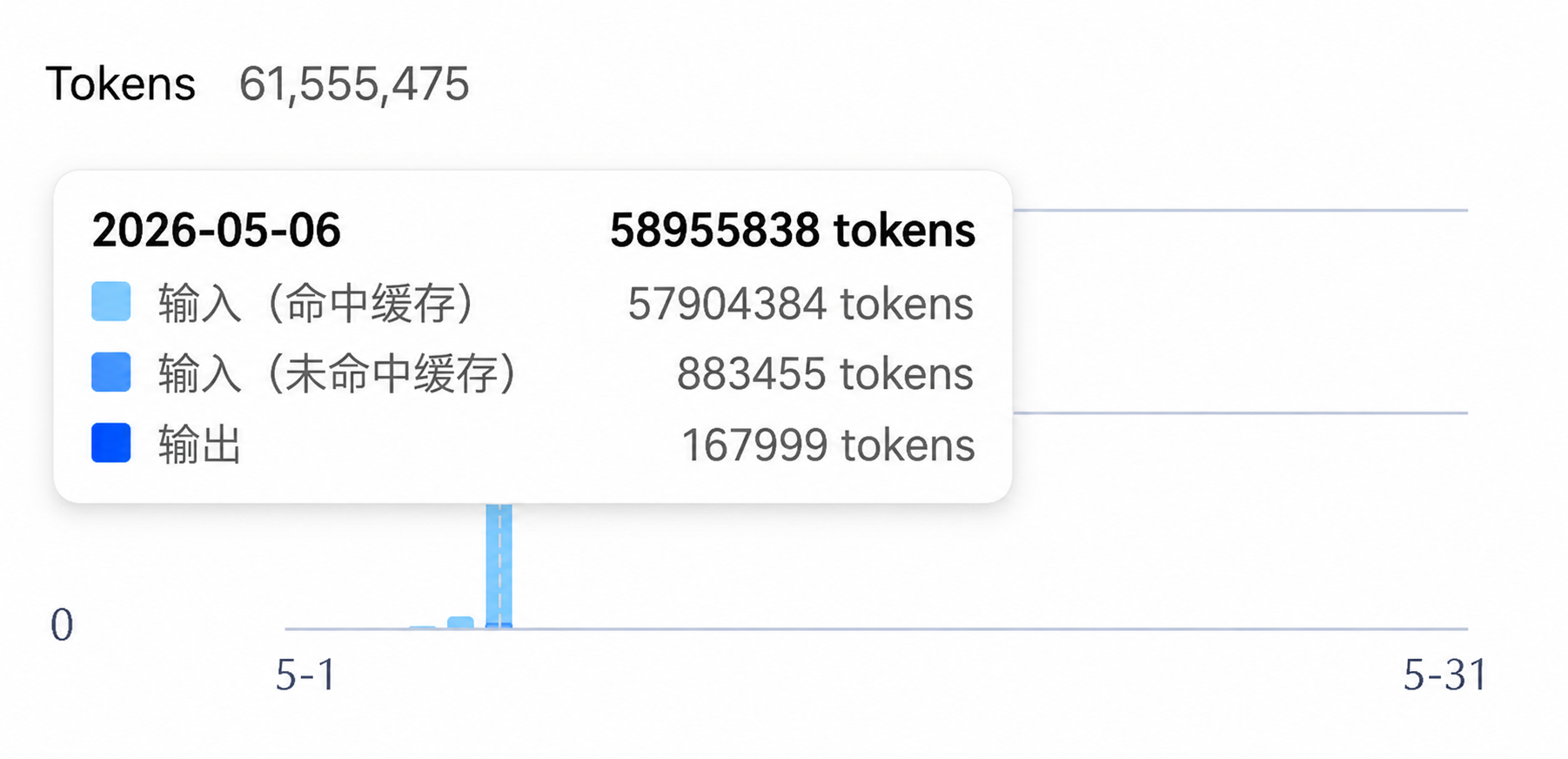
DeepSeek的api价格表,缓存命中0.02元/百万token,这和白送有什么区别?这个缓存命中折扣好像是永久折扣,没有时间限制。
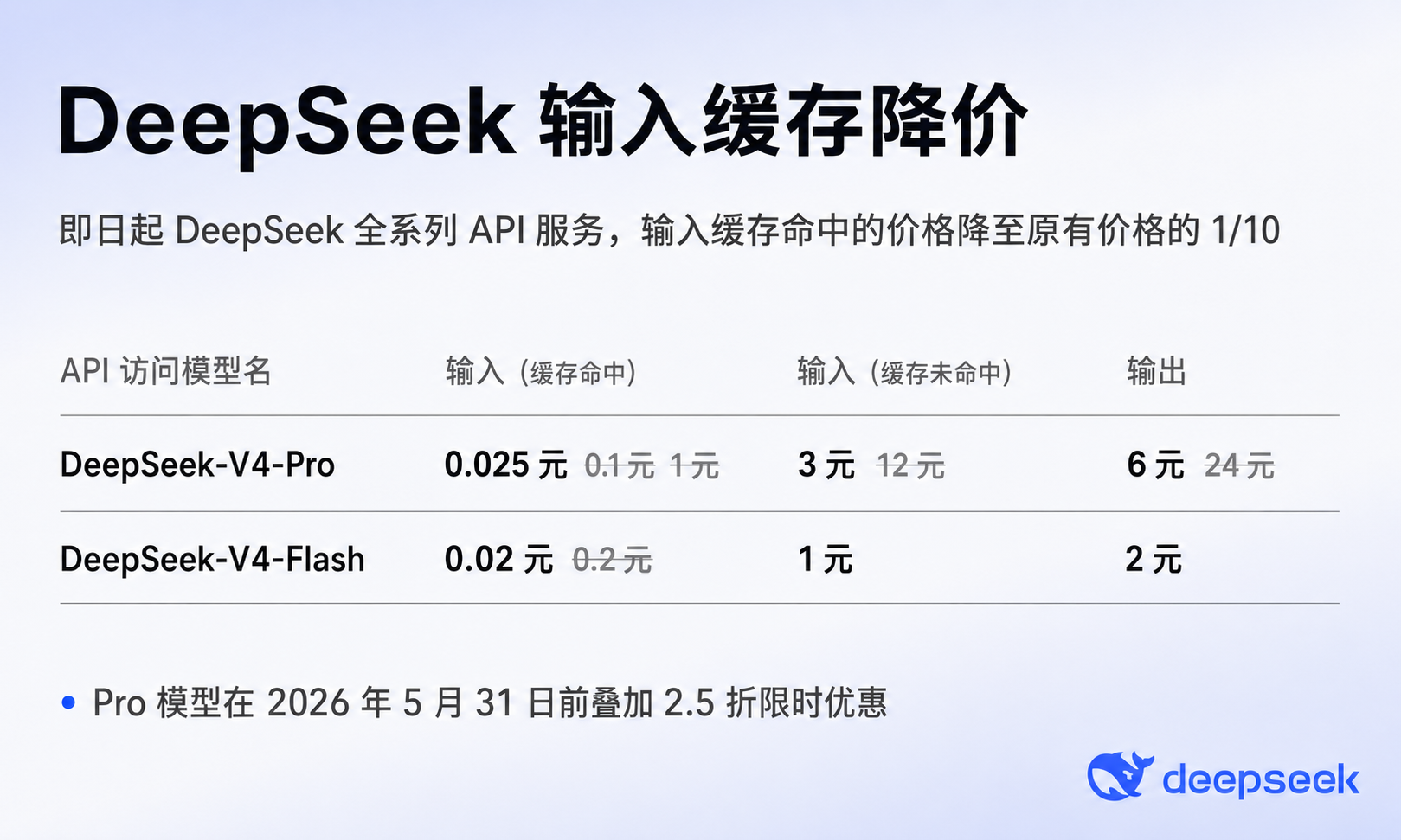
人民的 DeepSeek,小 D 的恩情还不完😭

- 安装 Claude Code。
- 安装 CC Switch。
- 在 CC Switch 里把 Claude Code 的后端 API 切到 DeepSeek。
- 准备一个你想接入这套工作流的目标项目。
- 打开 Codex;如果本机还没有
codexCLI,就先让 Codex 按官方命令自动安装。
没有 codex CLI 也不用慌,按上面的安装口令交给 Codex,它会先把自己的官方 CLI 装好,再继续接入这套工作流。
把下面这句扔给目标项目里的 Codex。
请把 https://github.com/aiskyhub/codex_with_cc 子代理工作流安装或更新到当前 Codex 环境。
- 提示词
你现在委派三个子代理,让他们深度分析项目,给出项目中的优化计划书,对于三份计划书中矛盾的点,需要反复打回让他们再去验证再去制定,直到一致,然后你汇总出一份优化计划书。
- 创建子代理
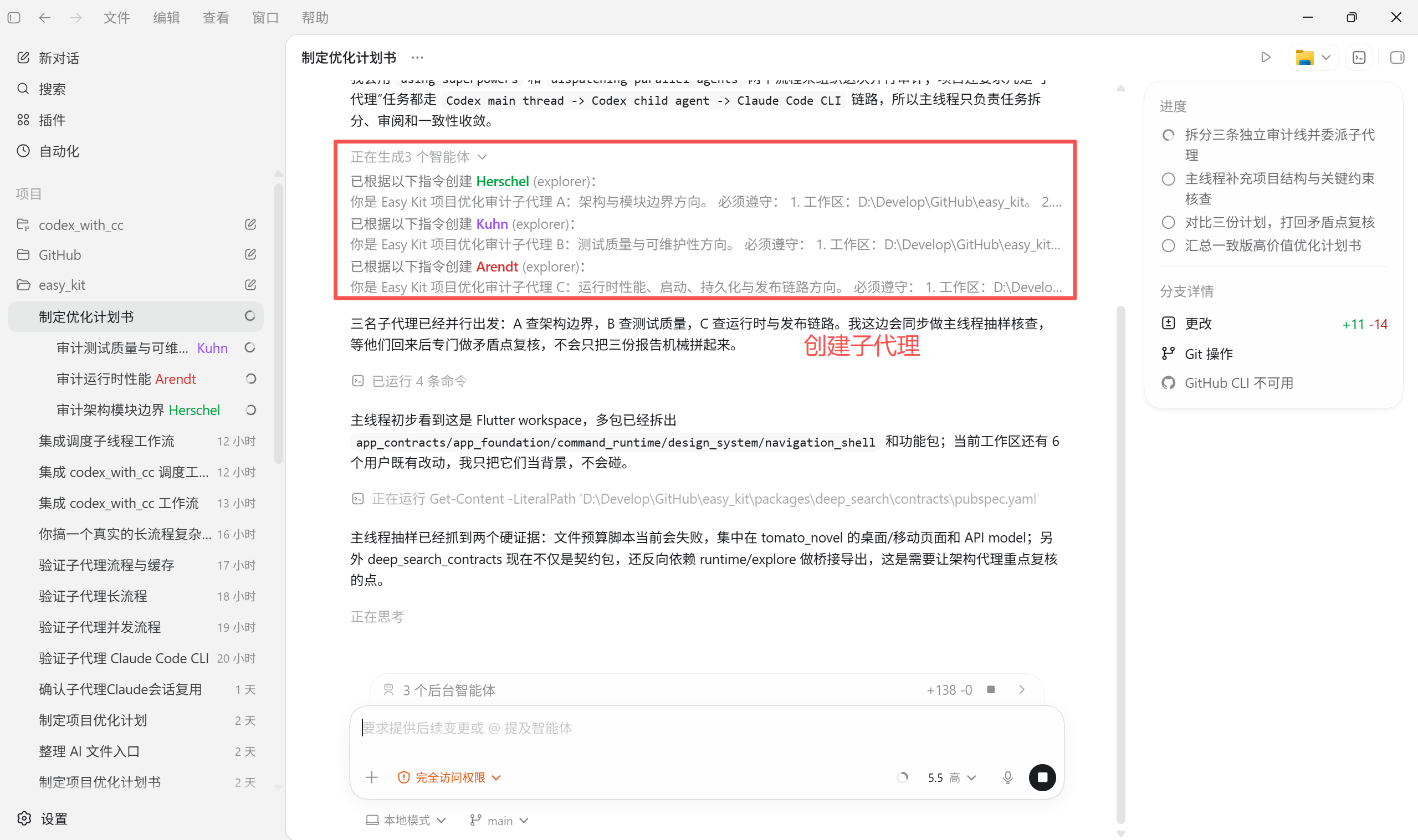
- 子代理执行Claude cli
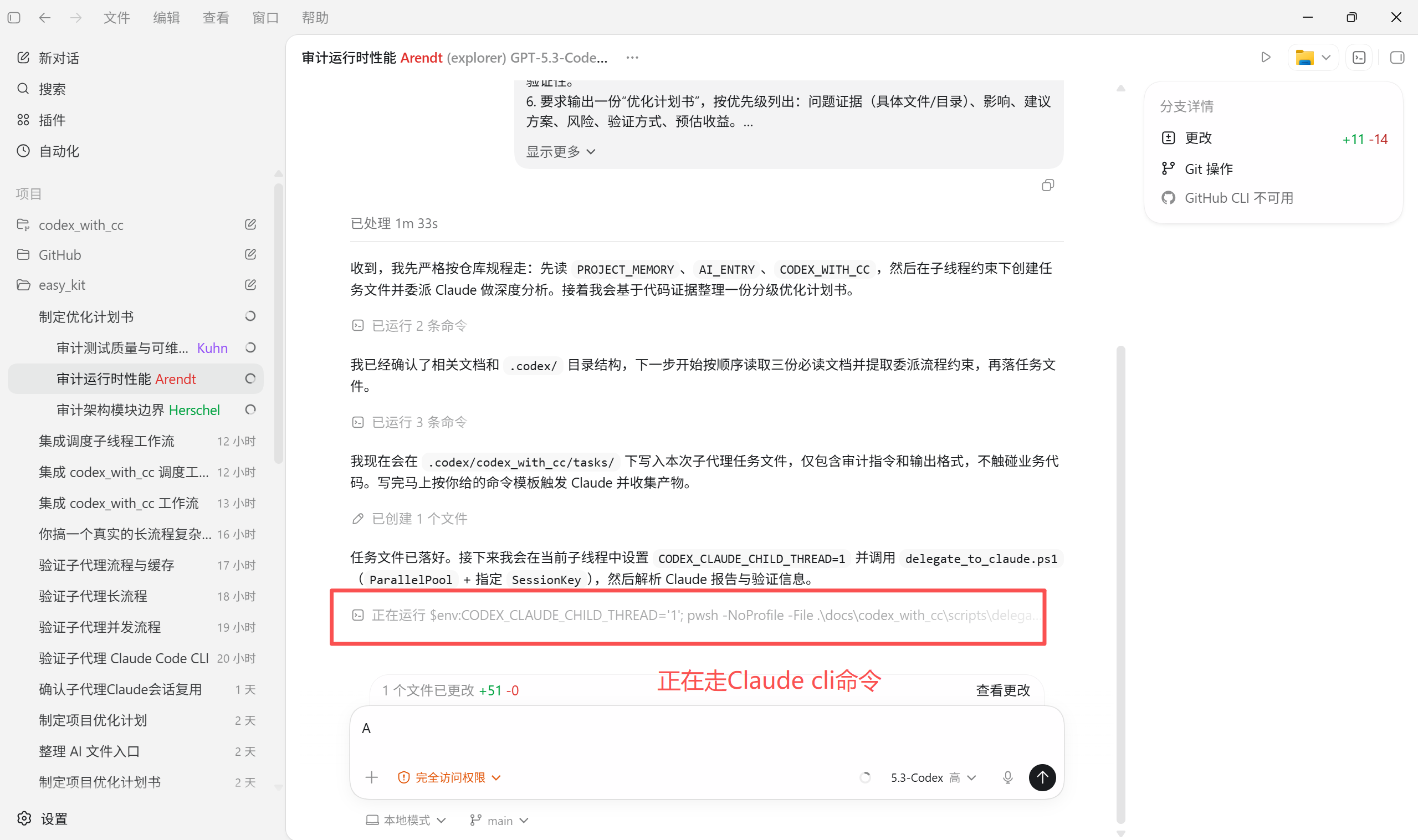
- 结果打回,重新验证
核心心法只有一句:让 Codex 做 leader,让子代理当大头兵。
你可以这样安排活:
你拆解 xxx 任务,安排给多个子代理实现。你负责审核子代理结果,不符合要求就打回让他们重改,直到符合要求为止。
适合大任务拆分:
你先阅读项目,拆成 3 个互不冲突的实现任务,分别交给子代理处理。每个子代理必须给出变更文件、验证命令和风险说明。你最后统一 review、整合,并跑最终验证。
适合多方案头脑风暴:
请启动多个子代理分别提出 xxx 的实现方案。每个方案需要说明优缺点、复杂度、风险和迁移成本。你汇总后给出推荐方案,不要直接照抄任何一个子代理。
适合互相找茬:
安排一个子代理实现 xxx,再安排另一个子代理专门做代码审查和边界情况攻击。你负责判断 review 是否成立,成立就打回实现代理修改,不成立就说明理由。
适合长上下文探索:
请把项目里的 xxx 模块交给子代理做深度调查,要求输出调用链、关键文件、潜在风险和建议修改点。你只保留结论,别把所有噪音塞回主上下文。
它内置了 Claude session 复用池:PrimaryReuse 负责串行主会话续跑,PrimaryAnchor 负责并行批次的上下文锚点,ParallelPool 负责独立支线任务的会话池化。简单说,就是尽量让相似任务复用稳定 session,把上下文热起来,把 DeepSeek/Claude Code 的缓存命中率吃满。长任务不再每次冷启动,重复阅读、重复建模、重复烧 token 的部分能少一点是一点。
它还有任务指纹、租约锁和会话回收机制:每次委派都会基于任务内容、作用域和验证命令生成 fingerprint;并行 worker 通过 lease 管理 session 占用;卡死、过期、进程消失的 lease 会被识别和回收。听起来像后端服务调度那套东西,对,它就是把那套脏活搬到了 AI 子代理调度里。
同时,委派链路不是“让 AI 自觉点”这种玄学约束。脚本会检查 CODEX_CLAUDE_CHILD_THREAD=1,强制 Claude Code 委派只能发生在 Codex 子线程里;主线程不能直接下场跑 claude,避免上下文污染、审计断链和结果没人兜底。Codex 主线程只做规划、派工、review、返工裁决,子代理才是执行层。
每次运行还会落审计产物:config_<RunId>.json、status_<RunId>.json、prompt_<RunId>.md、stream_<RunId>.jsonl、trace_<RunId>.log、claude_<RunId>.md。也就是说,任务怎么发出去的、用了哪个 session、有没有 resume、输出是什么、链路有没有断,都能查。不是“AI 说它干了”,而是有 artifacts 能验尸。
最后还有验证脚本兜底:运行时验证、session pool 验证、artifact 验证、delegate chain 验证都配好了。多子代理并行不是凭感觉开派对,而是有 session state、RunId、SessionKey、artifact root 和链路校验把它们串起来。逼格说法叫:可审计、可复用、可并发、可回放的多代理委派协议。、
人话说法叫:让 Codex 当老板的时候,至少给它配了办公室制度和打卡机。
主 Codex 线程负责理解需求、拆任务、创建子代理、审核结果、打回返工和最终交付。
Codex 子代理负责作为可追踪的对话树节点,调用委派脚本,把具体实现、调查、审查这些高 token 消耗任务交给 Claude Code CLI。
Claude Code CLI 负责执行被委派的具体任务,按要求修改文件或做调查,运行验证,并输出结构化报告。
这样主线程不会被海量代码和日志淹掉,子代理干苦活,主 Codex 保持清醒。项目越大,这个分工越香。
- 大范围代码阅读和模块梳理。
- 多文件实现任务。
- 重复但费 token 的测试修复。
- 让多个代理分别给方案,再由 Codex 汇总决策。
- 一个代理写代码,另一个代理专门 review。
- 迁移、重构、补测试、查调用链这类脏活累活。
不太适合:
- 只有一两行的小改动。
- 需要主线程实时交互判断的需求。
- 文件冲突极高、边界还没想清楚的并行任务。
Codex 不是不能自己干活,但它更适合当架构师、项目经理、审稿人和最终责任人。真正吃 token 的苦力活,交给 Claude Code 后面的 DeepSeek 去啃。你要做的,就是学会给 Codex 下这种命令:
你负责拆解、派工、审核和最终交付。子代理负责执行。结果不合格就返工,直到符合我的要求。
然后坐好,看小 D 把 token 焦虑按在地上摩擦。