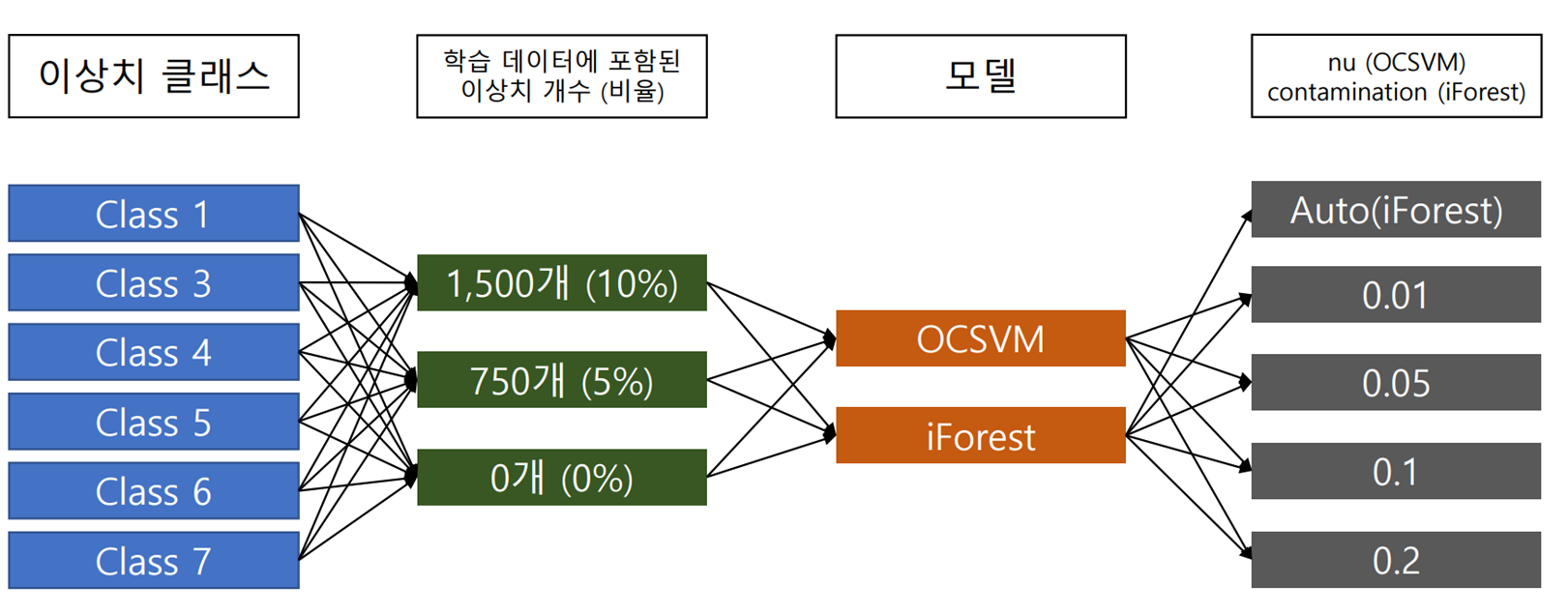
Anomaly Detection 튜토리얼 페이지 입니다. 본 튜토리얼에서는 이상치 탐지를 위한 Machine Learning 기법 중 활용도가 높은 One-Class SVM과 Isolation Forest에 대해 다루어 보겠습니다.
 https://www.sciencedirect.com/science/article/pii/S0031320314002751
https://www.sciencedirect.com/science/article/pii/S0031320314002751
One-Class SVM 은 SVM과 같이 데이터를 잘 구분 할 수 있는 최적의 Support Vector를 구하게 됩니다. 라벨이 주어진 상태에서 지도 학습으로 각 라벨을 구분 할 수 있는 결정 경계를 학습하는 SVM과는 달리, One-Class SVM에서는 라벨이 없이 주어진 데이터를 설명 할 수 있는 결정 경계를 구하고 그 밖의 데이터를 outlier로 간주하게 됩니다. 위 그림에서, 정상 데이터 셋을 원점에서 먼 쪽에 위치 시키고 이상 데이터를 원점에 가깝도록 데이터의 분포를 학습하게 됩니다.
 https://velog.io/@vvakki_/Isolation-Forest-%EB%AF%B8%EC%99%84%EC%84%B1
https://velog.io/@vvakki_/Isolation-Forest-%EB%AF%B8%EC%99%84%EC%84%B1
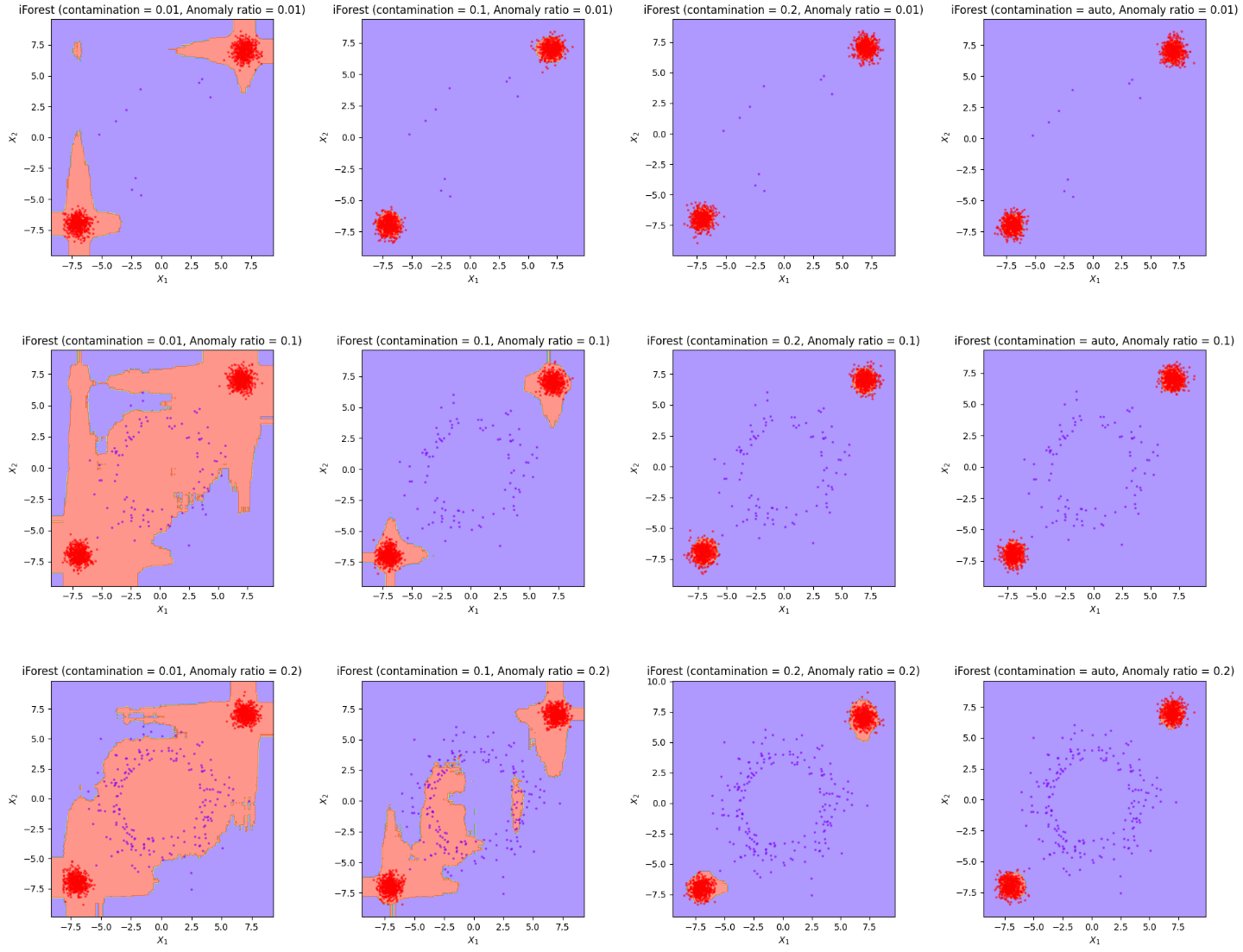
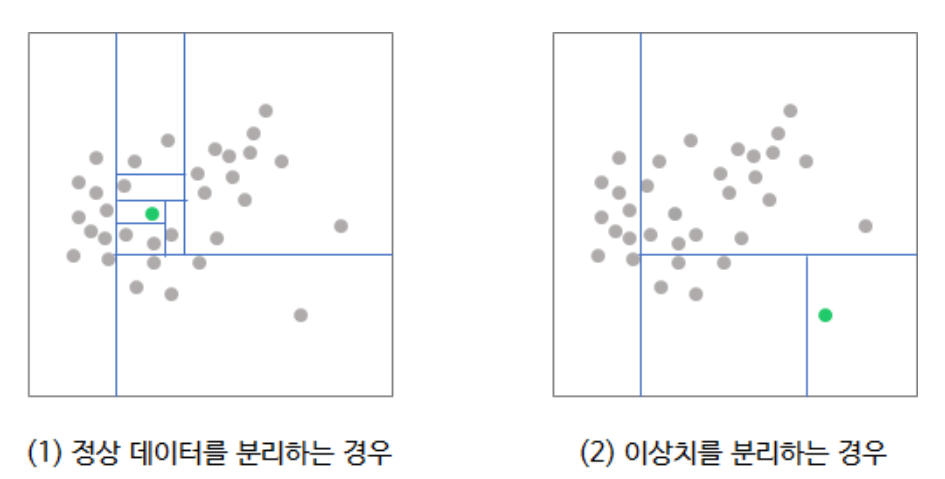
Isolation Forest의 경우 조금 더 간단합니다. 이상 데이터가 정상 데이터보다 고립 시키는 것이 쉬울 것이라는 간단한 아이디어에서 출발합니다. 위의 그림에서 왼쪽 초록점은 정상 데이터, 오른쪽 초록점은 이상 데이터라고 할 때, 왼쪽 초록점은 7번의 split이 필요하지만 오른쪽의 초록점은 3번의 split이 필요합니다.
각 모델에 대한 더 자세한 설명 및 실험 결과는 Notebook을 참고 해주세요.