메모리상에 데이터를 기록하기 위한 공간
- 값에 의미를 부여 (가독성이 좋아짐)
- 한 번 값을 저장해두고 계속 사용할 목적으로 사용
- 유지보수에 용이
- 한 개의 값만 담을 수 있음
- 자료형에 맞는 값만 담을 수 있음
- 새로운 값을 다시 대입할 수 있음
자료형 변수명;
변수명 = 값;
=> 자료형 변수명 = 값;
- 기본형 (8개)
- 논리형 (논리값 = true / false)
- boolean (1byte)
- 숫자형
- 정수형
- byte : 1byte (-128 ~ 127)
- short : 2byte
- int : 4byte (기본형)
- long : 8byte
- 실수형
- float : 4byte
- double : 8byte (기본형)
- 정수형
- 문자형
- char : 2byte
- 논리형 (논리값 = true / false)
- 참조자료형
- String ...
-
변수명 중복 불가 (대소문자는 구분)
-
변수명으로 예약어 사용 불가

-
숫자 포함 가능 (숫자로 시작 불가)
-
특수문자(_, $) 가능
-
낙타표기법 준수
-
한글 가능
- 값 변경 불가
- 상수명 전체 대문자로 작성
final 자료형 상수이름;
import java.util.Scanner;
Scanner sc = new Scanner(System.in);- 문자열
- next() : 공백 이전까지의 값만 읽어들임
- nextLine() : 공백 포함 사용자가 입력한 한 줄 다 읽어들임
- 정수 : nextInt()
- 실수 : nextDouble()
- 문자값 : 문자열.charAt(뽑고자 하는 인덱스)
- 문자열의 부적절한 인덱스 접근시 StringIndexOutOfBoundsException 발생
- sc.nextLine() : nextLine()메소드 외의 메소드로 값을 가져온 후 버퍼에 남아있는 '엔터'를 비워주는 역할
- System.out.print(출력하고자 하는 값); : 값 출력 (줄바꿈 없음)
- System.out.println(출력하고자 하는 값); : 값 출력 후 줄바꿈
- System.out.printf("출력하고자 하는 형식 (포맷)", 출력하고자 하는 값, 값, 값, ...); : 제시한 형식에 맞춰 출력하고자 하는 값 출력 (줄바꿈 없음)
- 키워드
- %d : 정수 자리
- %c : 문자 자리 / %C : 대문자
- %s : 문자열 자리 (문자 가능) / %S : 대문자
- %f : 실수 자리 (소수점 아래 6자리)
- %b : 논리형 자리
- % 입력하기 : %%
- 출력하고자 하는 값의 갯수가 더 많으면 첫번째 값만 출력
출력 형식(포맷)의 자리가 더 많으면 에러 발생 - 정렬방법
- %5d : 5칸 확보하고 오른쪽 정렬
- %-5d : 5칸 확보하고 왼쪽 정렬
- %.2f : 소수점 아래 2자리까지만 표시
- Escape 문자
- \t (tab) : 정해진 공간만큼 띄어쓰기
- \n (new line) : 출력하고 다음 라인으로 옮김
- \u (유니코드)
- 특수문자 사용시 백슬래시 ()를 넣고 특수문자 넣어야 함
- 키워드
- 형변환이란? 값의 자료형을 바꾸는 것 (boolean 제외)
- 자동 형변환
자료형이 다른 두 값의 연산 시 자동의로 값의 범위가 작은 자료형이 큰 자료형으로 변환되어 처리

- 강제 형변환
큰 크기의 자료형을 작은 크기의 자료형으로 강제로 바꾸는 것
- 데이터 손실 발생 가능

- ! 논리부정 연산자
- 논리값 (true / false)을 반대로 바꾸는 연산자
- 논리값을 가지고 연산하고 그 결과도 논리값
- 증감 연산자
- ++ : 변수에 담긴 값을 1 증가시켜주는 연산자
- -- : 변수에 담긴 값을 1 감소시켜주는 연산자
- 전위 / 후위연산
- 전위연산 : (증감연산자)변수 => "선증감"후처리
- 후위연산 : 변수(증감연산자) => 선처리"후증감"
- 산술 연산자
- / % * > + -
- 비교 연산자 / 관계 연산자
- 대소비교 연산자 : < > <= >=
- 동등비교 연산자 : == !=
- 문자와 숫자간 대소 비교 가능
- 논리 연산자
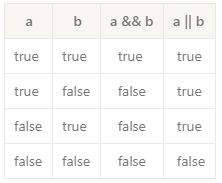
- 논리값 && 논리값
- 왼쪽, 오른쪽 둘 다 true일 경우 결과값 true
- 둘 중 하나라도 false일 경우 결과값 false
- ~이고, 그리고, ~이면서, ~뿐만아니라
- && 연산자를 기준으로 앞의 결과가 false일 경우 뒤쪽 조건검사는 굳이 실행되지 않음
- 논리값 || 논리값
-
왼쪽, 오른쪽 둘 중 하나라도 true일 경우 결과값 true
-
두 개의 조건 모두 false일 경우 결과값 false
-
~이거나, 또는
-
|| 연산자를 기준으로 앞의 결과가 true일 경우 뒤쪽 조건검사는 굳이 실행되지 않음
-
- 논리값 && 논리값
조건식?조건식이 true일 경우 돌려줄 결과값:조건식이 false일 경우 돌려줄 결과값
- 조건식 : 반드시 true / false가 나오도록 작성
- 비교 / 논리 연산자를 이용해 작성
- 삼항 연산자 중첩 사용 가능
num > 0 ? "양수이다." : (num < 0 ? "음수이다." : "0이다.");a = a + 3; => a += 3;
a = a - 3; => a -= 3;
a = a * 3; => a *= 3;
a = a / 3; => a /= 3;
a = a % 3; => a %= 3;
- 특이케이스
- 문자열 연이어 줄 때는 +=만 사용 가능
- 문자열과 숫자도 연이어 줄 수 있음
- 단독 if문
if(조건식){
실행시키고자 하는 코드
...
}
- 조건식이 true일 경우 중괄호 블럭 안의 코드 실행
- 조건식이 flase일 경우 중괄호 블럭 무시하고 넘어감
- if-else문
if(조건식){
실행코드1;
} else{
실행코드2;
}
- 조건식이 true일 경우 실행코드1 수행 후 if-else문 빠져나감
- 조건식이 false일 경우 무조건 실행코드2 수행
- if-else if문
if(조건식1){
실행코드1;
} else if(조건식2){
실행코드2;
} else{
위의 조건들이 다 false일 경우 실행할 코드
}
- else문 생략 가능
- return; 해당 메소드를 호출했던 곳으로 빠져나가는 구문
- 조건문 중첩 사용 가능
switch(동등 비교할 대상자){
case 값1: 실행코드1; break;
case 값2: 실행코드2; break;
...
default: 위의 값들과 모두 일치하지 않을 경우 실행코드;
}
=> default 생략 가능
-
if문과의 차이점
- if문 안의 조건식은 자유롭게 기술 가능 (범위에 대한 조건, 동등 비교 등)
- switch문은 동등비교만 가능
- 실행할 구문만 실행하고 자동으로 빠져나오지 못함 (직접 break문 작성)
-
break없는 switch문
등급별 권한
1 : 읽기권한, 글쓰기권한, 관리권한
2 : 읽기권한, 글쓰기권한
3 : 읽기권한Scanner sc = new Scanner(System.in); System.out.print("등급(정수) : "); int level = sc.nextInt(); switch(level) { case 1 : System.out.println("관리권한"); case 2 : System.out.println("글쓰기권한"); case 3 : System.out.println("읽기권한"); }
for(초기식;조건식;증감문){
반복적으로 실행시키고자 하는 코드;
}
- 초기식 : 반복문이 수행될 때 처음에 단 한번만 실행되는 구문
(반복문 안에서 사용될 변수를 선언과 동시에 초기화) - 조건식 : 반복문이 수행될 조건을 작성하는 구문
조건식이 true일 경우 해당 구문 실행
조건식이 false일 경우 반복을 멈추고 빠져나감
(초기식에 제시된 변수를 가지고 조건식 작성) - 증감식 : 반복문을 제어하는 변수 값을 증감 시키는 구문 (초기식에 제시된 변수를 가지고 증감연산자 (++, --)와 함께 작성)
- 무한반복
- 조건식 == true
- for(;;){}
- 원하는 횟수만큼 반복문 돌리고자 할 때
for(int i=0; i<횟수; i++){} - 중첩 for문
- 바깥쪽 for문 : 행 조건
- 안쪽 for문 : 열 조건
초기식;
while(조건식){
반복적으로 실행할 코드;
증감식;
}
=> 초기식, 증감식 생략 가능
do{
반복적으로 실행할 코드;
} while(조건식);
- 처음에 조건검사 없이 무조건 한번 실행
=> 조건검사 => true일 경우 실행
------------반복------------
=> 조건검사 => false일 경우 실행하지 않고 반복문 종료
- break문
break;- 반복문 안에 사용되는 분기문
- break; 실행 시 현재 속해있는 반복문을 빠져나감
- 유의사항
- switch문 안에서의 break;은 오로지 switch문만 빠져나감
- continue문
continue;- 반복문 안에 사용되는 분기문
- continue; 실행 시 그 뒤의 구문들 실행되지 않고 곧바로 현재 속해있는 반복문 위로 올라감
- 변수 : 하나의 공간에 하나의 값을 담을 수 있음
- 배열 : 하나의 공간에 여러 개의 값을 담을 수 있음
단, 같은 자료형의 값으로만 담을 수 있음
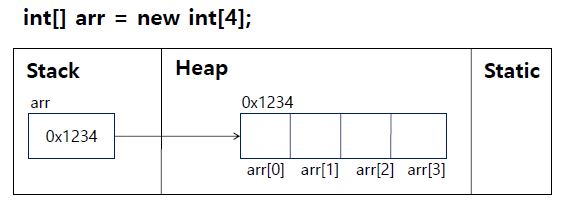
자료형 배열명[];
자료형[] 배열명;
배열명 = new 자료형[배열크기];
=> 자료형[] 배열명 = new 자료형[배열크기];
배열명[인덱스] = 값;
=> 자료형[] 배열명 = new 자료형[]{값, 값, ...}
자료형[] 배열명 = {값, 값, ...}
- 기본자료형으로 선언된 변수 : 실제 리터럴값을 바로 담는 변수 => 일반 변수
- 그 외 자료형으로 선언된 변수 : 주소값을 담는 변수 => 참조 변수 (레퍼런스 변수)
- Heap에는 빈 공간이 존재할 수 없음 => JVM이 기본값을 초기화 해줌 => 각 인덱스에 직접 값 대입하지 않아도 초기화 되어있음
- 한번 지정된 배열의 크기는 변경 불가 => 새로운 크기의 배열 다시 만들어야 함
- 연결이 끊긴 기존 배열은 그 어디에도 참조되고 있지 않은 불필요한 존재가 되어 일정 시간 지나면 가비지컬렉터(GC)가 지워줌 => 자동메모리 관리
- 배열을 강제로 삭제시키고자할 경우 => 연결고리 끊기
arr = null;
-
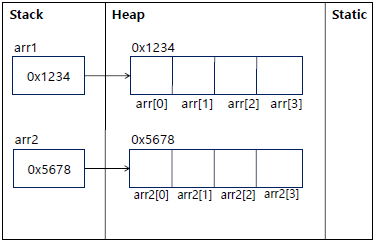
얕은 복사

int[] origin = {1, 2, 3, 4, 5}; int[] copy = origin; copy[2] = 99; System.out.println(Arrays.toString(origin)); // [1, 2, 99, 4, 5] System.out.println(Arrays.toString(copy)); // [1, 2, 99, 4, 5] System.out.println(origin == copy); // true
- 주소값만을 복사
- 같은 곳을 참조
-
깊은 복사
- for문 활용
새로운 배열 생성 후 반복문 활용하여 원본배열의 각 인덱스 값을 새로운 배열에 대입
int[] origin = {1, 2, 3, 4, 5}; int[] copy = new int[5]; for(int i=0; i<origin.length; i++) { copy[i] = origin[i]; } copy[2] = 99; System.out.println(Arrays.toString(origin)); // [1, 2, 3, 4, 5] System.out.println(Arrays.toString(copy)); // [1, 2, 99, 4, 5] System.out.println(origin == copy); // false
- System클래스의 arraycopy메소드 활용
System.arraycopy(원본배열명, 복사시작할인덱스, 복사본배열명, 복사본배열의복사될시작인덱스, 복사할갯수);int[] origin = {1, 2, 3, 4, 5}; int[] copy = new int[10]; System.arraycopy(origin, 2, copy, 5, 3) System.out.println(Arrays.toString(copy)); // [0, 0, 0, 0, 0, 3, 4, 5, 0, 0] System.out.println(origin == copy); // false
- Arrays클래스의 copyOf메소드 활용
내가 제시한 길이만큼의 새로운 배열생성
복사본배열 = Arrays.copyOf(원본배열명, 복사할길이);
=> 내가 제시한 길이가 원본 배열보다 클 경우 기존의 배열에 담겨 있는 값 복사 후 나머지 자리는 0
=> 내가 제시한 길이가 원본 배열보다 작을 경우 기존의 배열에 담겨 있는 값 제시한 길이만큼만 복사int[] origin = {1, 2, 3, 4, 5}; int[] copy = Arrays.copyOf(origin, 10); System.out.println(Arrays.toString(copy)); // [1, 2, 3, 4, 5, 0, 0, 0, 0, 0] System.out.println(origin == copy); // false
- clone()메소드 활용
복사본배열 = 원본배열.clone();int[] origin = {1, 2, 3, 4, 5}; int[] copy = origin.clone(); System.out.println(Arrays.toString(copy)); // [1, 2, 3, 4, 5] System.out.println(origin == copy); // false
- for문 활용
새로운 배열 생성 후 반복문 활용하여 원본배열의 각 인덱스 값을 새로운 배열에 대입

- 사전적 정의 : 현실세계에 독립적으로 존재하는 모든 것들
- 자바에서의 정의 : 메모리영역 중 Heap 영역에 생성되는 모든 것들
클래스에 정의된 내용대로 new 연산자를 통해 메모리 영역에 생성된 것
: 현실세계의 객체들간의 상호작용 프로그래밍을 통해 가상세계로 구현하는 과정
- 프로그램상에 필요한 객체들을 만들기 위해서
⇒ 클래스(틀) 생성 (객체들의 속성값들을 담아낼 그릇같은 존재)
⇒ 추상화 + 캡슐화 접목
① 내가 구현할 프로그램상에 필요한 객체들을 생각해보기
② 그 객체들이 가지고 있는 공통적인 속성, 기능들을 모두 추출할 것
③ 추출한 것들을 가지고 내가 구현하고자 하는 프로그램의 "실질적인 목적"에 맞춰 불필요한것들 제거해나가기
④ 최종적으로 추려진 속성들을 어떤 자료형으로, 어떤 변수명으로 할 건지 생각
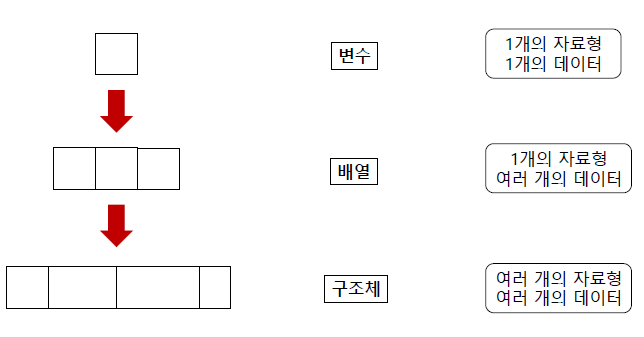
- "변수"만으로 프로그래밍을 한다면?
- 변수 : 하나의 자료형의 하나의 값만 보관
- 어떤문제? => 수백명의 객체들을 만들고자할때 수천개의 변수가 만들어짐
- "배열"만으로 프로그래밍을 한다면?
- 배열 : 하나의 자료형의 여러개의 값들을 보관
- 어떤문제? => 기존의 정보를 지울때 잘못 지우면 값이 변질될 수 있음
새로운 정보를 추가할 때 배열의 크기 변경 불가로, 배열 복사 후 값 추가하는 번거로움 발생
- "구조체" 개념
-
구조체 : 여러개의 자료형의 여러개의 값들을 보관할 수 있음
-
String값도 담고, int값도 담고, double값 등도 담을 수 있는 나만의 배열같은 자료형 => 클래스
클래스 만들기 ⇒ model.vo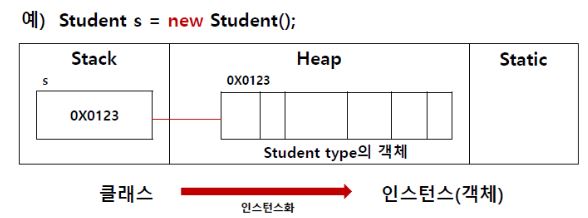
-
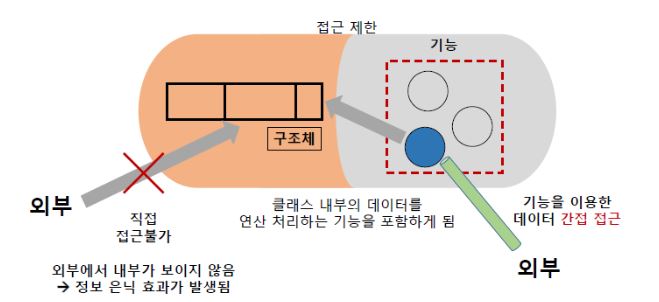
: "데이터의 접근제한"을 원칙으로 외부로부터 "데이터의 직접 접근을 막고" 대신에 "간접적으로나마 처리(값을 대입, 값을 대돌려주거나)"할 메소드를 클래스 내부에 작성
- 정보은닉 : 직접 접근을 막기 위해 private 접근제한자 이용
-
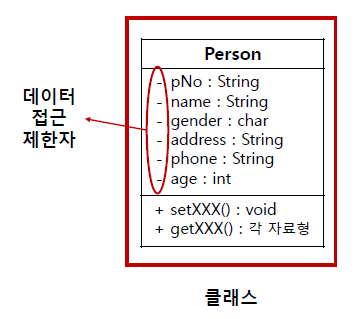
캡슐화 원칙
- 클래스의 멤버 변수에 대한 접근 권한은 private을 원칙으로 한다.
- 클래스의 멤버 변수에 대한 연산처리를 목적으로 하는 함수들을 클래스 내부에 작성한다.
- 멤버 함수는 클래스 밖에서 접근할 수 있도록 public으로 설정한다.
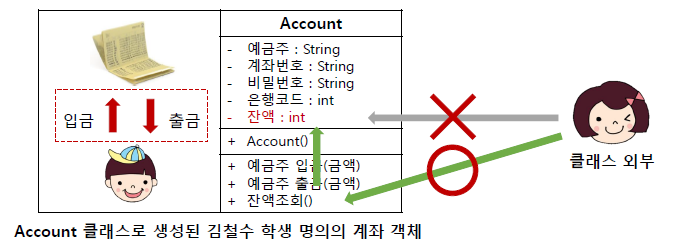
- 객체를 생성하기 위해 필요한 개념
- 객체의 특성에 대한 정의를 한 것으로 캡슐화를 통해 기능을 포함
- 사물이나 개념의 공통 요소를 추상화(abstraction)하여 정의
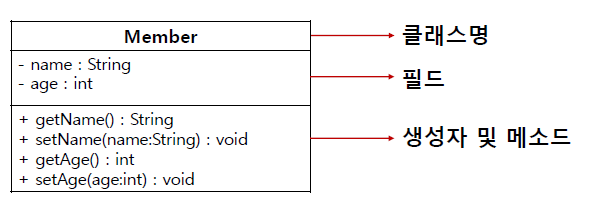
[접근제한자][예약어]class클래스명 {
1. 필드부
필드 == 멤버변수 == 인스턴스변수
<표현법>
접근제한자[예약어]자료형 변수명[=초기값];
2. 생성자부
객체를 생성하기 위한 일종의 메소드
<표현법>
접근제한자 클래스명(){
}
3. 메소드부
기능을 구현하는 부분
<표현법>
접근제한자[예약어]반환형 메소드명([매개변수]){
수행내용;
[return 결과값;]
}
}
- public : 같은 패키지 내에서든 다른 패키지에서든 해당 클래스를 사용 가능
- default : 같은 패키지 내에서만 사용 가능 (다른 패키지에서는 사용 불가) => 접근제한자 생략
- 전역 변수 : 클래스영역 안에 바로 선언한 변수 => 클래스 내에서 어디서든 전역으로 다 사용 가능
- 멤버변수 == 인스턴스변수
- 생성시점 : new 연산자를 통해서 객체 생성시
- 소멸시점 : 객체 소멸시 같이 소멸
- 멤버변수의 초기화 : 객체 생성시 JVM이 기본값으로라도 초기화
- 클래스변수 == static변수
- 생성시점 : 프로그램 실행과 동시에 무조건 메모리영역(static)에 할당
- 소멸시점 : 프로그램 종료될 때 소멸
- 멤버변수 == 인스턴스변수
- 지역 변수 : 클래스영역 내의 어떤 특정한 구역({})에 선언한 변수(매개변수 포함) => 선언된 해당 지역에서만 사용 가능
=> 메소드{}, 제어문(if,for){} 등등- 생성시점 : 지역변수가 속해있는 특정한 구역{} 실행(호출)시 메모리영역에 할당
- 소멸시점 : 특정한 구역{} 종료시 소멸
- 매개변수의 초기화 : 메소드 호출시 반드시 값이 전달되어 올 것이기 때문에 초기화
- 지역변수의 초기화 : 내가 초기화를 직접하지 않으면 텅 빈 상태
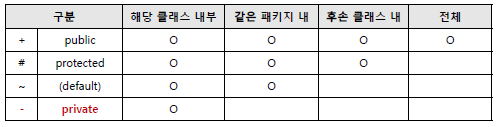
- public => 어디서든(같은 패키지, 다른 패키지 모두) 접근 가능
- protected => 같은 패키지 접근 가능, 다른 패키지일 경우 상속구조에서는 접근 가능
- default => 같은 패키지에서만 접근 가능 (다른 패키지일때는 절대 불가능)
- private => only 해당 클래스에서만 접근 가능
- 클래스 변수 (static 변수)
- 공유의 개념
- 프로그램 실행과 동시에 메모리의 static 영역에 올라감
- 프로그램 실행시 딱 한번 메모리상에 올려두고 여기저기 가져다 쓸 수 있음
- 객체생성 필요없이 클래스명.변수명으로 접근
- 값 변경 가능
- 상수필드 (static final)
- 상수의 개념(한번 지정된 값 변경 x)
- 프로그램 시작시 값이 저장되면 더이상 변경되지 않고 공유하면서 사용할 목적
- 반드시 초기화
- 필드명은 모두 대문자로 표현
- 객체 생성
- 객체 생성과 동시에 각 필드에 값 대입
- 반환형X (반환형을 쓰면 메소드가 됨)
- 생성자명 == 클래스명
- 매개변수 생성자를 명시적으로 작성할 경우 기본 생성자를 JVM이 자동으로 만들어주지 않음
=> 기본 생성자 작성 습관 들이기
- 매개변수 없는 생성자
- 객체 생성만을 목적으로 함
- 기본 생성자 생략 시 => JVM이 자동으로 만들어 줌
[접근제한자]클래스명(){
}
- 객체 생성과 동시에 전달값들을 매개변수로 받아 해당 각 필드에 초기화할 목적
- 초기화하지 않은 나머지 필드는 JVM의 초기값으로 초기화
- alt+Shift+s => o (매개변수생성자 창) => enter
[접근제한자]클래스명(매개변수){
(this.)필드명 = 매개변수;
}
- this
- 모든 인스턴스의 메소드에 숨겨진 채 존재하는 레퍼런스로, 할당된 객체를 가리킴
- 함수 실행 시 전달되는 객체의 주소를 자동으로 받음
- this()
- 생성자, 같은 클래스의 다른 생성자를 호출할 때 사용
- 반드시 첫 번째 줄에 선언해야 함
- 호출을 통해 사용, 전달 값이 없는 상태로 호출을 하거나 어떤 값을 전달하여 호출을 하며, 함수 내에 작성된 연산 수행
- 수행 후 반환 값 / 결과 값은 있거나 없을 수 있음
- 클래스명.메소드명();로 호출
- 호출 시 메소드명 기울인꼴로 나타남
- alt+Shift+s => r (getter/setter 창) => alt+a (모든필드 체크) => alt+r (generate)
- setter 메소드
- 해당 필드에 대입시키고자 하는 값 전달받아 해당 필드에 대입시켜주는 기능의 메소드 (변경)
- setter메소드명은 setXXX으로 낙타표기법을 지킨채로 지어주기 ex) setName, setAge, ...
필드명 - 매개변수명 == 필드명
- getter 메소드
- 해당 필드에 담긴 값을 반환시켜주는 기능 (조회)
- 반환하고자하는 값의 자료형을 반환형 자리에 기재
- return 이용하여 필드에 담긴 값이 반환
- boolean자료형의 getter 메소드는 isXXX으로 작성
한 클래스 내에 동일한 이름의 메소드명으로 정의할 수 있는 것
- 조건
- 같은 메소드 명
- 매개변수의 개수/타입/순서가 달라야 함
- 매개변수명, 반환 타입은 상관없음
-
선언
클래스명[] 배열명; 클래스명 배열명[]; -
할당
배열명 = new 클래스명[배열크기];=> 선언과 동시에 할당
클래스명[] 배열명 = new 클래스명[배열크기]; -
초기화
배열명[i] = new 클래스명();=> 선언과 동시에 할당 및 초기화
클래스명[] 배열명 = {new 클래스명(), new 클래스명(), ...} -
객체배열 구조
Example arr[] = new Example[2];
=> Example 객체를 2개 담을 수 있는 배열을 만든 것 뿐 객체를 생성한 것은 아님
arr[0]. 으로 직접 접근할 경우 NullPointException 오류 발생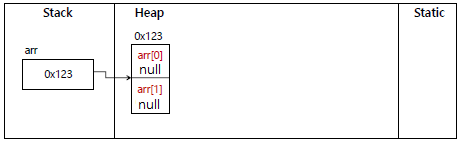
arr[0] = new Example(); arr[1] = new Example();
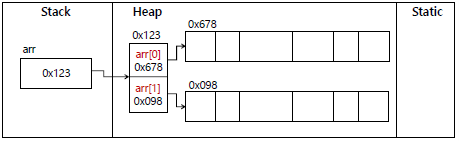
-
향상된 for문 (for each문)
- 배열 또는 컬렉션과 함께 사용되는 for문
- 0번 부터 마지막까지 순차적으로 접근할 목적 => 향상된 for문(for each문)
- 조회할 때 사용 (생성시에는 for loop문 사용)
- 자바 5버전 이상부터 사용 가능
for(순차적으로 접근한 값을 담을 변수 선언 : 순차적으로 접근할 배열 또는 컬렉션) { 반복적으로 실행할 내용 }- 반복횟수 == 배열 또는 컬렉션의 크기
- 변수의 자료형 대입될 값과 일치시키기
- 부모(상위) 자식(하위) 간의 구조로 클래스를 구성하는 것
- 다른 클래스가 가지고 있는 필드 및 메소드들을 새로 작성할 필요 없이 마치 내 것처럼 사용할 수 있는 기술
[접근제한자]class클래스명 extends 클래스명{}
자식 ----------> 부모
후손 조상
하위 상위
this super
- 공통적인 코드들을 부모 클래스로 한번 정의해두면 새로운 클래스 작성시 보다 적은 양의 코드로 작성 가능
- 중복된 코드를 별도로 관리하기 때문에 코드의 추가나 변경에 용이 (프로그램의 생산성과 유지보수에 크게 기여)
- super.
- 상속을 통한 자식 클래스 정의 시 해당 자식 클래스의 부모 객체를 가리키는 참조변수
- 자식 클래스 내에서 부모 클래스 객체에 접근하여 필드나 메소드 호출 시 사용
- super()
- 부모 객체의 생성자를 호출하는 메소드로 기본적으로 후손 생성자에 부모 생성자 포함
- 후손 객체 생성 시에는 부모부터 생성이 되기 때문에 후손 클래스 생성자 안에는 부모 생성자를 호출하는 super()가 첫 줄에 존재
(부모 생성자가 가장 먼저 실행되어야 하기때문에 명시적으로 작성 시에도 반드시 첫 줄에만 작성) - 매개변수 있는 부모 생성자 호출 => super(매개변수, 매개변수)
- 클래스간의 상속은 다중상속 불가 (단일상속만 가능 => 부모는 하나다)
- 부모클래스에 정의되어있는 protected 필드는 자식클래스에서 직접 접근 가능
- 자식객체는 부모클래스에 있는 메소드를 마치 내 것처럼 호출 가능
부모클래스에 있는 메소드가 맘에 안들면 자식클래스에서 재정의 가능 (오버라이딩) - 명시되어있진 않지만 모든 클래스(자바에서 제공하는 클래스, 직접 만든 클래스)는 Object클래스의 후손
=> Object클래스에 있는 메소드들 마음대로 호출 가능
=> 오버라이딩을 통해서 재정의 가능
- 오버라이딩이란?
- 자식 클래스가 상속 받은 부모 메소드를 재작성 하는 것
- 부모가 제공하는 기능을 자식이 일부 고쳐 사용하는 것
- 자식 객체를 통한 실행 시 자식 것이 우선권을 가짐
- 오버라이딩 성립 조건
- 부모메소드명과 동일
- 매개변수 갯수, 자료형, 순서 동일 (매개변수명은 상관없음)
- 부모메소드의 반환형과 동일 (jdk버전업되면서 부모메소드 반환형의 자식자료형들까지 가능)
- 부모메소드의 접근제한자보다 같거나 커야함 (private 메소드 오버라이딩 불가)
ex) 부모메소드가 protected일 경우 오버라이딩 메소드는 protected, public 가능
- @Override 어노테이션
- 생략가능
- 어노테이션 붙이는 것 권장
- 자식메소드 기술시 오타가 있을 경우 ⇒ 오류 발생
부모메소드가 변경 됐을 경우 ⇒ 오류 발생 - 이 메소드가 오버라이딩 된 메소드임을 알림
- 자식메소드 기술시 오타가 있을 경우 ⇒ 오류 발생
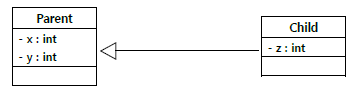
- ‘여러 개의 형태를 갖는다’
- 부모타입으로부터 파생된 여러타입의 자식 객체들을 부모타입 하나로 다룰수 있는 기술
-
부모타입 레퍼런스로 부모객체를 다루는 경우
Parent p = new Parent(); p.printParent();

=> p 레퍼런스로 Parent에만 접근 가능
-
자식타입 레퍼런스로 자식객체를 다루는 경우
Child c1 = new Child(); c.printChild(); c.printParent();

=> c 레퍼런스로 Child1, Parent 둘 다 접근 가능
=> ((Parent)c).printParent(); ⇒ 자동형변환 -
부모타입 레퍼런스로 자식객체를 다루는 경우 (다형성)
Parent p = /*(Parent)*/new Child(); p.printParent(); ((Child)p).printChild();
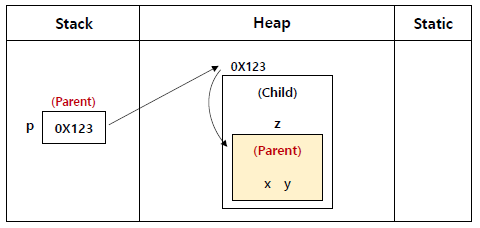
=> p 래퍼런스는 당장 Parent에만 접근 가능
=> Child타입으로 강제형변환 하면 Child까지도 접근 가능
- “상속구조”의 클래스들 간 형변환 가능
- ClassCastException : 부적절한 클래스 형변환시 나타나는 오류
- 업 캐스팅 (Up Casting)
- 자식 타입 -> 부모 타입
- 자동 형변환
- 다운 캐스팅 (Down Casting)
- 부모 타입 -> 자식 타입
- 강제 형변환
- 현재 참조형 변수가 어떤 클래스 형의 객체 주소를 참조하고 있는지 확인 할 때 사용
- 클래스 타입이 맞으면 true, 맞지 않으면 false 반환
if(레퍼런스 instanceof 클래스타입){
true일 때 처리할 내용, 해당 클래스타입으로 down casting
}
- 정적 바인딩 : 프로그램 실행되기 전 "컴파일시" 모든 메소드는 정적 바인딩 됨 (레퍼런스타입의 메소드를 가리킴)
- 동적 바인딩 : 실질적으로 참조하는 자식클래스에 해당 메소드가 오버라이딩 되어있다면 프로그램 "실행시(런타임시)" 동적으로 자식클래스에 오버라이딩 된 메소드를 찾아서 실행
- 다형성을 이용하여 상속 관계에 있는 하나의 부모 클래스 타입의 배열 공간에 여러 종류의 자식 클래스 객체 저장 가능
- 다형성을 이용하여 메소드 호출 시 부모타입의 변수 하나만 사용해 자식 타입의 객체를 받을 수 있음
- 부모타입의 배열로 다양한 자식객체들을 받을 수 있음
- 메소드 정의시 다형성 개념을 적용시키면 메소드 개수가 줄어듦
- 추상메소드 (abstract method)
- 미완성된 메소드로 몸통부({})가 구현되어 있지 않은 메소드
- 추상 메소드의 선언부에 abstract 키워드 사용
- 자식클래스에서 해당 메소드를 오버라이딩하여 완성
[접근제한자] abstract 반환형 메소드명(자료형 변수명); - 추상클래스 (abstract class)
- 미완성된 클래스
- 추상 클래스 선언부에 abstract 키워드 사용
- 일반멤버변수 + 일반메소드 [+ 추상메소드]
=> 추상메소드 생략가능
[접근제한자] abstract class 클래스명 {}
- 특징
- 자체적으로 객체 생성 불가 -> 반드시 상속하여 객체 생성 (다형성 적용 가능) 단, 참조형 변수 타입(레퍼런스)으로는 사용 가능
- abstract 메소드가 없어도 abstract 클래스 선언 가능
- 개념적 : 단지 이 클래스가 미완성된 클래스다 라는 걸 부여할 목적
- 프로그래밍적 : 객체 생성이 불가하게끔 하고자 할 때
- 클래스 내에 일반 변수, 메소드 포함 가능
- 장점
- 자식클래스마다 실행시킬 내용은 다르지만 동일한 형태의 메소드로 구현했으면 할 때 일관된 인터페이스 제공 (메소드 통일성 확보) => 표준화
- 꼭 필요한 기능 강제화 (공통적이나 자식클래스에서 특수화 되는 기능)
- 상수형 필드와 추상 메소드만을 작성할 수 있는 추상 클래스의 변형체
- 메소드의 통일성을 부여하기 위해 추상 메소드만 따로 모아놓은 것으로 상속 시 인터페이스 내에 정의된 모든 추상메소드 구현
[접근제한자] interface 인터페이스명 {
[public static final] 자료형 변수명 = 초기값;
[public abstract] 반환자료형 메소드명([자료형 매개변수]);
}
- 특징
- 모든 인터페이스의 메소드는 묵시적으로 public이고 abstract
- 변수는 묵시적으로 public static final => 인터페이스 변수의 값 변경 시도 시 컴파일 시 에러 발생
- 객체 생성은 안되나 참조형 변수로는 가능
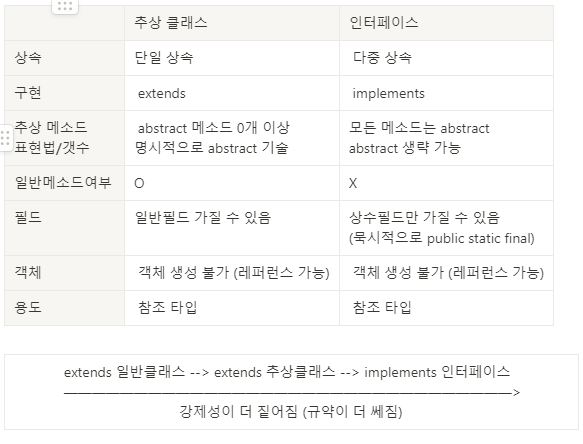
- 추상클래스 : 일반멤버변수 + 일반메소드 + 추상메소드
- 인터페이스 : only 상수필드 + only 추상메소드
- 클래스에서 클래스를 상속 받을 때 : 클래스 extends 클래스 (단일상속만 가능) : 화살표 "실선"
- 클래스에서 인터페이스를 구현할 때 : 클래스 implements 인터페이스, 인터페이스, ... (다중상속 가능) : 화살표 "점선"
- 인터페이스에서 인터페이스를 상속 : 인터페이스 extends 인터페이스, 인터페이스, ... (다중상속 가능) : 화살표 "실선"
- 클래스도 상속 받고 인터페이스도 구현할 때 : 클래스 extends 클래스 implements 인터페이스
- Math 특징
- java.lang.Math ⇒ import 필요 없음
- 모든 필드 상수필드, 모든 메소드 static 메소드!
즉, 프로그램 실행과 동시에 이미 static 메모리 영역에 다 올라가있음
=> 클래스명. 으로 접근 가능 - 생성자 아예 private으로 되어있음 => 생성 불가 ex) Math m = new Math(); 불가
- 한번만 메모리 영역에 올려놓고 재사용하는 개념 => 싱글톤 패턴
- 상수필드
System.out.println(Math.PI); // 3.141592653589793
- abs 메소드 : 절대값을 알고자할 때
int num1 = -10; Math.abs(num1); // 10
- ceil 메소드 : 올림
=> 실수값으로 반환. 정수값 필요하면 int로 강제 형변환
double num2 = 4.349; Math.ceil(num2); // 5.0
- round 메소드 : 반올림
Math.round(num2); // 4
- floor 메소드 : 버림
Math.floar(num2); // 4.0
- rint 메소드 : 가장 가까운 정수값 알아내기
Math.rint(num2); // 4.0
- sqrt 메소드 : 제곱근(루트)
Math.sqrt(4); // 2.0
- pow 메소드 : 제곱
Math.pow(2, 10); // 1024.0
-
생성자를 통한 문자열 생성
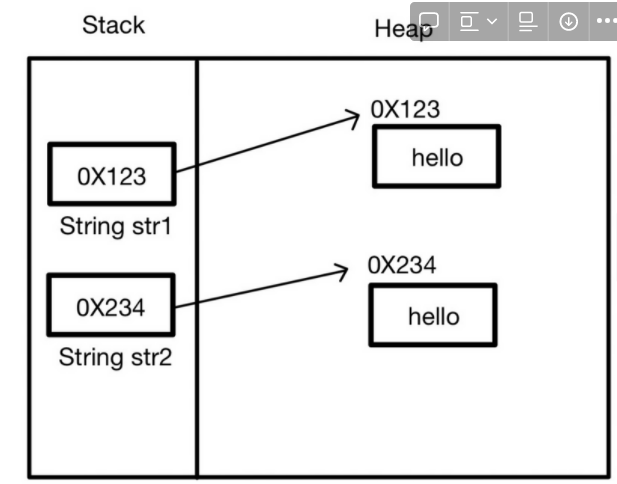
String str1 = new String("hello"); String str2 = new String("hello"); System.out.println(str1); // hello System.out.println(str2/*.toString()*/); // hello
=> String클래스에 toString메소드 이미 오버라이딩 되어있음 (실제 담긴 문자열 반환하도록)
System.out.println(str1 == str2); // false System.out.println(str1.equals(str2)); // true
=> “==”으로 비교시 주소값 비교라서 false
=> String클래스에 equals메소드 이미 오버라이딩 되어있음 (주소값이 아닌 실제 담긴 문자열간 비교)System.out.println(str1.hashCode()); System.out.println(str2.hashCode());
=> 같은 주소값 출력
=> String클래스에 hashCode메소드 이미 오버라이딩 되어있음 (주소값이 아닌 실제 담긴 문자열가지고 만듦)
=> 진짜 주소값을 알고자 할 경우 System.identityHashCode(레퍼런스) -
문자열을 리터럴값으로 생성
- 리터럴 제시시 상수풀(String pool) 영역에 올라감
- String pool 특징 : 동일한 문자열을 가질 수 없음

String str1 = "hello"; String str2 = "hello"; System.out.println(str1.hashCode()); System.out.println(str2.hashCode()); // 같음 System.out.println(str1 == str2); // true (주소값 일치) System.out.println(System.identityHashCode(str1)); System.out.println(System.identityHashCode(str2)); // 같음
-
String 클래스 == 불변클래스
- 변경이 가능하긴 하나 그 자리에서 수정되는 개념 아님
- 변경하는 순간 새로운 곳을 참조하도록 주소값 바뀜
- 빈번하게 값을 변경해야 될 경우 GC가 계속 기존의 값들을 지워줘야하는 단점
- 변경이 적고 한번 값을 담은 후에 단지 조회만 할 경우 String 클래스가 용이
-
String 메소드
- 문자열.charAt(int index) : char
- 문자열에서 전달받은 index위치의 문자만을 추출해서 리턴
- 문자열.concat(String str) : String
- 문자열과 전달된 또다른 문자열을 하나로 합쳐서 새로운 문자열로 리턴
- 문자열.equals(Object obj) : boolean
- 실제 문자열값을 가지고 동등비교 해줌
- "=="는 주소값 비교
-
- 문자열.contains(CharSequence s) : boolean
- 문자열에 전달된 문자열이 포함되어있으면 true 아니면 false 반환 (키워드 검색)
- CharSequence는 String의 부모 인터페이스 (다형성적용됨)
- 문자열.length() : int
- 해당 문자열의 길이(글자수) 반환
- 문자열.substring(int beginIndex) : String => 문자열의 beginIndex위치에서부터 끝까지 다 추출해서 반환
문자열.substring(int beginIndex, int endIndex) : String => 문자열의 beginIndex에서부터 endIndex "이전"까지 문자열을 추출해서 반환 - 문자열.replace(char oldChar, char newChar) : String
- 문자열에서 oldChar를 newChar로 변환한 새 문자열 리턴
- 원본 문자열은 그대로 유지
- 문자열.toUpperCase() : String => 문자열을 다 대문자로 변경한 새 문자열 리턴
문자열.toLowerCase() : String => 문자열을 다 소문자로 변경한 새 문자열 리턴 - 문자열.trim() : String
- 문자열의 앞 뒤 공백을 제거시킨 새 문자열을 리턴
- 앞 뒤 공백만 제거, 중간 공백은 그대로 유지
- 문자열.charAt(int index) : char
- 두 개의 클래스 모두 생성자나 메소드가 동일함
- 유일한 차이점 동기화 되냐 안되냐의 차이 => 속도 차이
- 객체 생성시 처음에 16개의 문자들을 저장할 수 있는 버퍼가 내부적으로 생성
- 리터럴값 대입 불가
- 동기화 : 한 자원에 대해 여러 스레드가 접근하려 할 때 한 시점에서 하나의 스레드만 사용될 수 있게 하는 것
- StringBuilder : 동기화 제공 x => 속도가 빠름
- StringBuffer : 동기화 제공 o => 속도가 느림
- StringBuilder 생성자
- 기본 생성자로 생성
=> .capacity() : 수용량 => 기본적으로 16
StringBuilder sb1 = new Stringbuilder(); System.out.println(sb1.capacity()); // 16
- 정수값 하나 전달 가능한 매개변수 생성자로 생성
=> 전달된 정수값 크기만큼의 수용량 지정
StringBuilder sb2 = new Stringbuilder(30); System.out.println(sb2.capacity()); // 30
- 문자열 하나 전달가능한 매개변수 생성자로 생성
=> 수용량 = 기본 수용량 + 전달한 문자열의 길이
StringBuilder sb3 = new StringBuilder("반가워!!"); System.out.println(sb3.capacity()); // 21 System.out.println(sb3.length()); // 5
=> .length() : 문자열의 길이
- 기본 생성자로 생성
- StringBuilder 메소드
- append(String str) : StringBuilder
- 기존의 문자열에 새로운 문자열 추가
- 기존의 수용량을 초과할 경우 => 수용량 = 기존의 수용량 * 2 + 2
- delete(int start; int end) : StringBuilder
- start<= <end 범위의 문자열 삭제
- 늘어난 수용량 다시 줄어들지 않음
- insert(int offset, String str) : StringBuilder => offset 위치에 str을 추가
- reverse() : StringBuilder => 기존의 문자열을 역으로 바꿈
- 메소드체이닝 : 메소드 연이어서 호출 (가독성을 위해 내려서 표시 가능)
- append(String str) : StringBuilder
- String클래스에서 제공하는 split()메소드와 같은 기능을 하는 클래스
- 생성 시 전달받은 문자열을 구분자로 나누어 각 토큰에 저장
- 구분자를 기준으로 해서 문자열을 분리 시키는 방법
- 분리된 문자열들을 String[] 배열에 차곡차곡 담고자 할 때 String 클래스에서 제공하는 split메소드 사용
String str = "Java,Oracle,JDBC,HTML,Css,Spring"; String[] arr = str.split(",");
- 분리된 문자열들을 각각 토큰 객체로 관리하고자 할 때 java.util.StringTokenizer 클래스 이용
StringTokenizer stn = new StringTokenizer(분리시키고자하는문자열, 구분자);- countTokens() : 분리된 문자열의 갯수
- nextToken() : 토큰에 담겨있는 순서대로 차곡차곡 뽑힘. stn에서 사라짐(1회용). 여러번 사용하려면 변수에 담아서 사용
- hasMoreTokens() : 토큰에 담겨 있는 게 있으면 true
- 더 이상 요소가 없을 때 NoSuchElementException 오류 발생
- 분리된 문자열들을 String[] 배열에 차곡차곡 담고자 할 때 String 클래스에서 제공하는 split메소드 사용
- 기본자료형을 객체화시킬 수 있는 클래스들
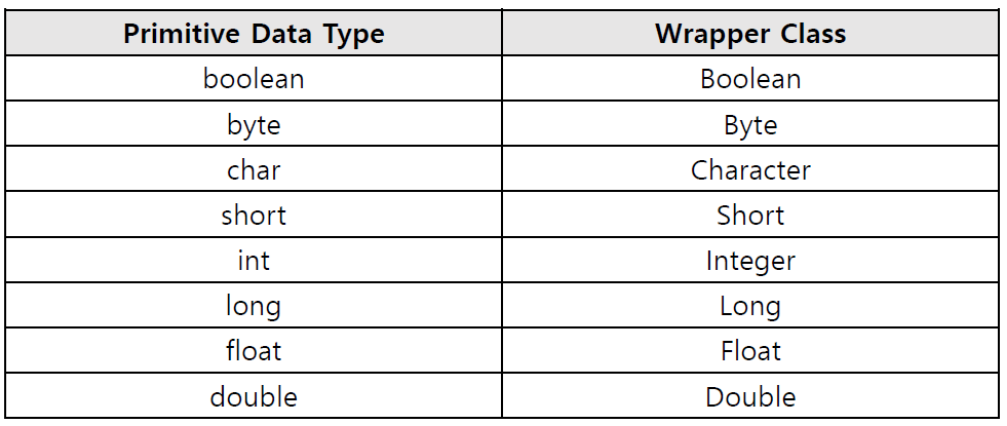
- 기본자료형을 객체로 취급해야하는 경우
- 메소드 호출해야될때
- 매개변수가 기본자료형이 아닌 객체타입만을 요구할 때
- 다형성을 적용시키고 싶을 때
- Boxing : 기본자료형 => Wrapper클래스 자료형
- 객체 생성 구문을 통한 방법
int num1 = 10; int num2 = 15; Integer i1 = new Integer(num1); // num1 => i1 Integer i2 = new Integer(num2); // num1 => i2 System.out.println(i1); // 10 System.out.println(i2); // 15 System.out.println(i1.equals(i2)); // false System.out.println(i1.compareTo(i2)); // -1
- 객체화 시키면 메소드 호출 가능
- compareTo() : 두 값을 비교해서 앞이 크면 1, 일치하면 0, 뒤가 더 크면 -1 반환
- 객체 생성할 필요 없이 곧바로 대입 (AutoBoxing)
Integer i3 = num1; System.out.println(i3); // 10
- 양쪽 타입이 달라도 대입 허용
- 객체 생성 구문을 통한 방법
- UnBoxing : Wrapper클래스 자료형 => 기본자료형
- 해당 Wrapper클래스에서 제공하는 xxxValue() 메소드를 이용
int num3 = i1.intValue(); // i1 => num3 System.out.println(num3); // 10
- 메소드 사용하지 않고 바로 대입 (AutoUnBoxing)
int num4 = i2; System.out.println(num4); // 15
- 해당 Wrapper클래스에서 제공하는 xxxValue() 메소드를 이용
- 기본자료형 <--> String
- String --> 기본자료형 : 해당 Wrapper클래스.parseXXX() 사용 (parsing)
int i = Integer.parseInt(str1);
- 기본자료형 --> String : String.valueOf() 사용
String strI = String.valueOf(i);
- String --> 기본자료형 : 해당 Wrapper클래스.parseXXX() 사용 (parsing)
- 날짜 및 시간에 대한 값을 담을 수 있는 객체
- java.util 패키지
- 기본생성자를 이용해서 생성
=> 현재 날짜 및 시간(시스템 날짜 및 시간)을 담고 있음
Date date1 = new Date();
- 내가 원하는 날짜로 셋팅
- 매개변수 생성자를 이용해서 생성
=> 년도 - 1900 / 월 - 1
Date date2 = new Date(2023-1900, 3-1, 27);
- 기본생성자로 생성한 후 setter메소드로 값 변경
- 매개변수 생성자를 이용해서 생성
- SimpleDateFormat 클래스
- Date의 날짜, 시간 정보를 원하는 format으로 출력하는 기능 제공
- java.text 패키지
=> 년 : y / 월 : M / 일 : d / 요일 : E / 시 : H / 분 : m / 초 : sSimpleDateFormat sdf = new SimpleDateFormat("yyyy년 MM월 dd일(E) HH시 mm분 ss초"); String formatDate = sdf.format(date1);
- 시스템 에러 : 컴퓨터의 오작동으로 발생하는 에러 => 소스코드로 해결안됨 ⇒ 심각한 에러
- 컴파일 에러 : 소스코드 문법상 오류 => 빨간줄로 오류로 알려줌 (개발자의 실수)
- 런타임 에러 : 코드 상으로 문제가 없는데 프로그램 실행 중에 발생하는 에러 (사용자의 실수일 수 있고 개발자가 예측가능한 경우를 제대로 처리 안해놨을 경우)
- 논리 에러 : 문법적으로도 문제없고 실행했을 때도 문제는 없지만 프로그램 의도상 맞지 않은 것
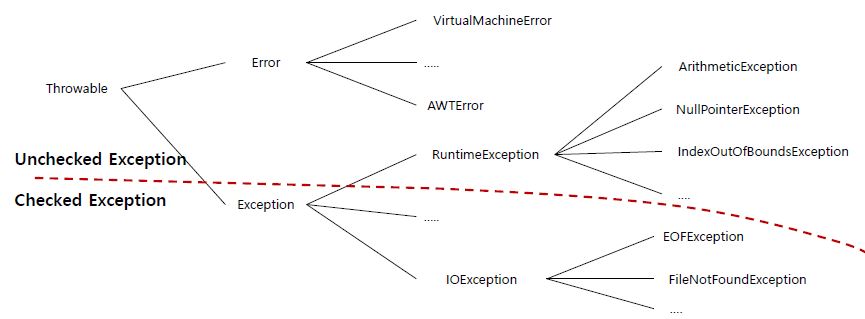
- 시스템 에러를 제외한 컴파일, 런타임, 논리 에러와 같은 덜 심가한 것들을 "예외"라고 함 => Exception
- "예외"가 "발생"했을 경우에 대해 "처리"하는 방법 => "예외처리”
- 예외처리를 하는 목적 : 예외처리를 하지 않고 그대로 예외가 발생되는 경우 프로그램이 비정상적으로 종료됨
- try~catch로 예외 잡기
try{ 예외가 발생될 수 있는 구문; } catch(예외클래스 e) { 해당 예외가 발생됐을 경우 실행할 구문 미리 작성; } finally { 예외 발생 여부와 관계없이 꼭 처리해야 하는 구문; 스트림 반납 (close()) } - try
withresource- 스트림 반납까지 자동으로 진행 (jdk7버전 이상부터 가능)
try(try블럭내에서 사용할 스트림객체 생성구문; 생성구문...){ } catch(예외클래스 e){ } - trows로 예외 던지기
- 지금 즉시 예외를 처리하지 않고 현재 이 메소드를 호출했던 곳으로 예외처리를 떠넘김 (위임)
- main까지 쭉 throws로 떠넘기면 JVM이 알아서 처리
public void method2() throw IOException{ } public void method1() throws IOException{ method2(); }
- try~catch로 예외 잡기
- 반드시 예외 처리하지 않아도 됨
- RuntimeException의 후손들
- IndexOutOfBoundsException : 부적절한 인덱스 제시시 발생되는 예외
- NullPointerException : 레퍼런스가 null로 초기화된 상태에서 어딘가에 접근할 때 발생되는 예외
- ClassCastException : 허용할 수 없는 형변환이 진행될 때 발생되는 예외
- ArithmeticException : 나누기 연산시 0으로 나눠질 때 발생되는 예외
- NegativeArraySizeException : 배열 할당시 배열의 크기를 음수로 지정하는 경우 발생되는 예외 ....
- 반드시 예외처리를 해야만 하는 예외들
- 조건문 제시 불가 (예측 불가한 곳에서 문제가 발생)
- 외부 매개체와 입출력이 일어날 때 발생

- java.io 클래스
- 경로지정을 하지 않은 상태로 파일 생성
=> 프로젝트 폴더에 생성
File f1 = new File("test.txt"); f1.createNewFile();
- 경로지정한 상태로 파일 생성
=> \ 하나만 쓰면 이스케이프문자로 인식 => 2개 써줘야함
File f2 = new File("C:\\folder\\text.txt"); f2.createNewFile();
- 폴더 먼저 만들고 파일 생성
File folder1 = new File("C:\\folder2"); folder1.mkdir(); File f3 = new File("C:\\folder2\\test.txt"); f3.createNewFile();
- 파일/디렉토리 관련 메소드
- createNewFile() : 새로운 파일 생성
- mkdir() : 새로운 디렉토리(폴더) 생성
- isFile() : 파일인지 여부
- getName() : 파일 이름 리턴
- getAbsolutePath() : 절대경로 (물리적인 경로) 리턴
- length() : 파일 크기 리턴
- getParent() : 상위 폴더 리턴
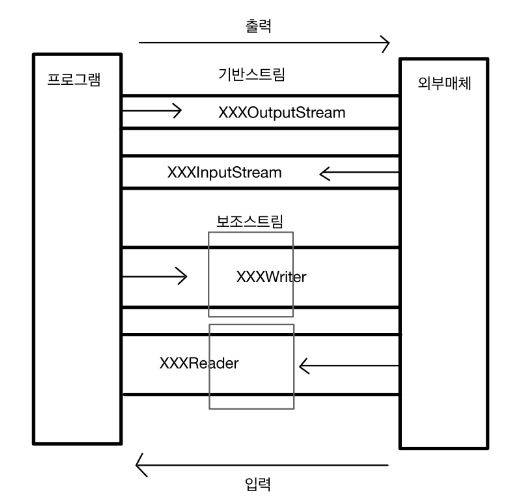
- 프로그램 상의 데이터를 외부매체로 출력하거나 입력 받아올 때 생성하는 통로
- 특징
- 단방향 : 출력이면 출력용스트림 / 입력이면 입력용스트림
- 선입선출(FIFO) : 먼저 들어간 데이터가 먼저 나감 => 시간지연(delay)이 발생될 수 있음
- 구분
- 통로의 사이즈 (1byte / 2byte)
- 바이트 스트림 : 1byte짜리 데이터만 왔다 갔다 할 수 있는 좁은 통로 (한글 불가) => 입력(InputStream) / 출력(OutputStream)
- 문자 스트림 : 2byte짜리 데이터도 왔다 갔다 할 수 있는 넓은 통로 => 입력(Reader) / 출력(Writer)
- 외부매체와 직접 연결 유무
- 기반(기본) 스트림 : 외부 매체와 직접적으로 연결되는 통로 (필수)
- 보조 스트림 : 보조 역할만 하는 통로 (속도 향상 도움, 그외 유용한 기능 제공...)
단독 사용 불가! 기반스트림 반드시 있어야함
- 통로의 사이즈 (1byte / 2byte)
- XXXInputStream : XXX매체로부터 데이터를 입력받을 수 있는 통로
- XXXOutputStream : XXX매체로 데이터를 출력시킬 수 있는 통로
- 프로그램 —> 파일 (출력)
-
FileOutputStream : 파일과 직접적으로 연결해서 1바이트 단위로 출력시킬 수 있는 스트림
FileOutputStream fout = null; try { fout = new FileOutputStream("a_byte.txt"/*, true*/); fout.write(97); // 'a' 문자 저장 fout.write('b'); // 'b' 문자 저장 //fout.write('하'); byte[] arr = {99, 100, 101}; fout.write(arr); // 'c', 'd', 'e' 문자가 저장 fout.write(arr, 1, 2); // 'd', 'e' 문자가 저장 } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { fout.close(); } catch (IOException e) { e.printStackTrace(); } }
① FileOutputStream 객체 생성 (해당 파일과의 연결통로가 만들어짐)
- 해당 파일과의 연결통로가 만들어짐
- 해당 파일이 없으면 새로 만들어 준 후 통로연결 / 있으면 그냥 통로연결
- true 미작성시 : 해당 파일이 존재할 경우 기존의 데이터 덮어씌워짐 (기본값 false)
true 작성시 : 해당 파일이 존재할 경우 기존의 데이터에 이어서 작성 - finally에서 fout 사용하기 위해 try문 바깥에 초기화해둠
② 스트림으로 데이터를 출력 (write 메소드 사용)
- 숫자(0~127), 문자
- 한글은 2byte짜리기 때문에 깨져서 저장
- 배열 출력시 통째로 지나가지 못하고 하나씩 지나가서 기록
③ 다 사용한 후 스트림 반납 (반드시)
- try안에 작성시 중간에 예외가 발생되는 경우 해당 이 구문 실행 안될 수 있음
- finally안에 예외처리하여 작성
-
- 프로그램 <— 파일 (입력)
-
FileInputStream : 파일로부터 데이터를 1바이트 단위로 입력받는 스트림
FileInputStream fin = null; try { fin = new FileInputStream("a_byte.txt"); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); System.out.println(fin.read()); // -1 System.out.println(fin.read()); // -1 while(true) { int value = fin.read(); if(value == -1) { break; } } System.out.println(value); int value = 0; while((value = fin.read()) != -1) { System.out.print((char)value); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { fin.close(); } catch (IOException e) { e.printStackTrace(); } }
① FileInputStream 객체 생성 (해당 파일과의 연결통로가 만들어짐)
- 해당 파일이 존재하지 않으면 예외 발생 (자동으로 만들어주지 않음)
② 스트림으로 데이터 입력받기 (read 메소드 사용)
- 실제로 파일에 얼마만큼의 데이터가 있는지 모름
- 파일의 끝을 만나는 순간 -1 반환
- 무한반복 활용하여 출력
- while문에 조건문 제시하여 출력
③ 스트림 자원 반납
-
- XXXReader : 입력용 스트림
- XXXWriter : 출력용 스트림
- 프로그램 —> 파일 (출력)
-
FileWriter : 파일로 데이터를 2바이트 단위로 출력할 수 있는 스트림
FileWriter fw = null; try { fw = new FileWriter("b_char.txt"); fw.write("와! IO 재밌다..ㅎㅎ"); fw.write(' '); fw.write('A'); fw.write("\n"); char[] arr = {'a', 'p', 'p', 'l', 'e'}; fw.write(arr); } catch (IOException e) { e.printStackTrace(); } finally { try { fw.close(); } catch (IOException e) { e.printStackTrace(); } }
① FileWriter 생성
② 데이터 출력 (write 메소드)
- 2바이트 단위로 데이터 전송
- \n 개행문자로 한 줄 띄어쓰기
③ 스트림 반납
-
- 프로그램 <— 파일 (입력)
-
FileReader : 파일로부터 데이터를 2바이트 단위로 입력받을 수 있는 스트림
FileReader fr = null; try { fr = new FileReader("b_char.txt"); int value = 0; while((value = fr.read()) != -1) { System.out.print((char)value); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { fr.close(); } catch (IOException e) { e.printStackTrace(); } }
① FileReader 객체 생성
② 데이터 입력 (read 메소드)
③ 스트림 반납
-
- 속도를 향상 시키거나 기반스트림에서 제공하지 않는 메소드들을 제공
- 입출력 성능 보조스트림 (BufferedXXXXX)
-
버퍼라는 공간에 계속 쌓아놨다가 한번에 출력해줌 => 속도향상에 도움
-
프로그램 —> 파일 (출력)
- FileWriter : 파일과 직접적으로 연결해서 2바이트 단위로 출력할 수 있는 기반스트림
- BufferedWriter : 버퍼라는 공간을 제공해주는 보조스트림 (속도 향상)
① 기반스트림 생성
FileWriter fw = new FileWriter("c_buffer.txt");
② 보조스트림 생성
BufferedWriter bw = new BufferedWriter(fw);
- 기반스트림, 보조스트림 함께 생성
보조스트림 = new 보조스트림(new 보조스트림(기반스트림객체));
-
프로그램 <— 파일 (입력)
- FileReader
- BufferedReader
- readLine() : 한줄씩 읽어들이는 메소드
-
- 객체(배열) 입출력 보조스트림
public class Phone implements Serializable {
private String name;
private int price;
...
}=> 객체 자체를 입출력하고자 할 때 필수
=> Serializable 인터페이스를 구현
- 프로그램 —> 파일 (출력) - 객체
- FileOutputStream
- ObjectOutputStream : 객체 단위로 출력할 수 있도록 도움을 주는 보조스트림 (ObjectWriter 없음)
- writeObject()
- 프로그램 <— 파일 (입력) - 객체
- FileInputStream
- ObjectInputStream
- readObject()
- 프로그램 —> 파일 (출력) - 객체배열
Phone[] arr = new Phone[3]; arr[0] = new Phone("갤럭시", 1200000); arr[1] = new Phone("아이폰", 1300000); arr[2] = new Phone("플립", 1500000); try(ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("e_phones.txt"))){ for(int i=0; i<arr.length; i++) { oos.writeObject(arr[i]); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }
- 프로그램 <— 파일 (입력) - 객체배열
try(ObjectInputStream ois = new ObjectInputStream(new FileInputStream("e_phones.txt"))){ while(true) { System.out.println(ois.readObject()); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (EOFException e) { System.out.println("파일을 다 읽었습니다."); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); }
- 파일의 끝을 만나는 순간 IOException의 자식인 EOFException(end of file) 예외 발생 / while에 조건문 제시 못함
- EOFException 예외 처리 해주고 싶으면 IOException 예외 처리 구문보다 위에 작성 해주기
- 자료구조가 내장되어있는 자바 클래스로 자바에서 제공하는 "자료구조를 담당하는 프레임워크”
- 자료구조 : 방대한 데이터들을 효율적/구조적으로 관리(조회, 정렬, 추가, 수정, 삭제)하기 위한 개념
- 프레임워크 : 데이터나 기능들을 보다 쉽게 사용할 수 있도록 제공하는 틀
- 방대한 데이터들을 효율적으로 관리할 수 있는 기능들이 이미 내장되어있는 클래스
- 배열
- 크기에 대한 제약이 많음 (크기 지정 필수, 한번 지정된 크기 변경 불가)
- 중간 위치에 추가하거나 삭제하는 경우 값을 뒤로 또는 앞으로 땡겨주는 작업을 직접 코드로써 구현해야됨
- 한 타입의 데이터만 저장 가능
- 컬렉션
- 크기에 대한 제약이 없음 (크기 지정 안해도됨, 알아서 크기 변경됨)
- 중간 위치에 추가하거나 삭제하는 경우 값을 땡겨주는 알고리즘을 직접 구현할 필요없음
이미 메소드로 제공하고 있기때문에 메소드 호출만으로 간단하게 처리할 수 있음 - 여러 타입의 데이터 저장 가능

- List 계열
- 데이터(value)만 저장 가능
- 순서 유지함 (index의 개념있음)
- 중복된 데이터 허용됨
- Vector, "ArrayList", LinkedList, ..
- Set 계열
- 데이터(value)만 저장 가능
- 순서 유지되지 않음
- 중복된 데이터 허용안됨
- HashSet, TreeSet, ..
- Map 계열
- 키(key)와 데이터(value)를 함께 저장
- 순서 유지되지 않음
- value는 중복될 수 있으나 key는 중복허용안됨
- HashMap, TreeMap, Properties, ..
ArrayList/*<Object>*/ list = new ArrayList/*<Object>*/(3);
System.out.println(list); // []=> 크기 지정 할 수도 있고 안 할 수도 있음 (초기 저장 용량은 10으로 자동 설정)
=> 데이터 추가 전에는 안에 아무것도 없음 (비어있는 상태)
=> 별도로 제네릭 설정을 하지 않으면 => E == Object
- add(E e) : 리스트의 끝에 전달된 데이터를 추가시켜주는 메소드 *
- E --> Element : 리스트에 담길 데이터들(요소)
- 장점 : 크기의 제약 없음 / 여러타입 보관 가능
- 특징 : 순서유지 하면서 담김 (0번 인덱스부터 차곡차곡)
- add(int index, E e) : 해당 인덱스위치에 데이터를 추가시켜주는 메소드
- 장점 : 중간 위치에 데이터 추가시 복잡한 알고리즘 직접 구현 안함
- remove(int index) : 해당 인덱스위치의 데이터를 삭제시켜주는 메소드
- set(int index, E e) : 해당 인덱스위치에 데이터를 새로이 전달된 e로 변경시켜주는 메소드 *
- size() : 리스트의 사이즈를 반환시켜주는 메소드
- get(int index) : E ⇒ 해당 인덱스위치의 객체를 반환시켜주는 메소드 *
- 변수에 담거나 getter 메소드 등을 불러올 시 강제 형변환 필요
- subList(int index1, int index2) : List (List 인터페이스 : ArrayList의 부모) ⇒ 기존의 리스트에서 일부 추출해서 새로운 List로 반환
- index1 <= < index2
- addAll(Collection c) : 컬렉션(List, Set)을 통채로 뒤에 추가시켜주는 메소드
- isEmpty() : boolean ⇒ 컬렉션이 비어있는지 묻는 메소드 *
- clear() : 싹 비워주는 메소드
ArrayList<Music> list = new ArrayList<>();- 장점
- 명시된 타입의 객체만 저장하도록 제한을 둘 수 있음
- 컬렉션에 저장된 객체를 꺼내서 사용할 때 매번 형변환하는 절차를 없앨 수 있음
- HashSet
-
새로운 데이터를 추가할 때마다 동일객체(hashCode값 일치한지, equals비교시 true인지 : String class(실제 문자열로 비교))인지 판단함
-
동일객체 : 각 객체마다 hashCode 결과가 일치, equals 비교시 true여야됨
- Student에 equals() 오버라이딩 => "실제 각 필드에 담긴 데이터"들이 다 일치하면 true/ 아니면 false
- Student에 hashCode() 오버라이딩 => "실제 각 필드에 담긴 데이터"들이 다 일치하면 동일한 10진수 반환
-
HashSet에 담긴 모든 객체들에 순차적으로 접근
- 인덱스의 개념도 없고 get메소드 자체도 없음 (== 한 객체만 뽑을 수 없음)
① for문 사용 가능 (단, 향상된 for문으로만 가능)
for(Student s : hs2) { System.out.println(s); }
② ArrayList에 옮겨 담은 후 ArrayList 반복문 돌려서 출력
- ArrayList에 옮겨담기 1. addAll메소드 이용
ArrayList<Student> list1 = new ArrayList<>(); list1.addAll(hs2); for(int i=0; i<list2.size(); i++) { System.out.println(list2.get(i)); }
- ArrayList에 옮겨담기 2. ArrayList 생성시 통채로 추가하기
ArrayList<Student> list2 = new ArrayList<>(hs2); for(int i=0; i<list2.size(); i++) { System.out.println(list2.get(i)); }
③ Iterator 반복자를 이용해서 순차적으로 접근
Iterator<Student> it = hs2.iterator(); while(it.hasNext()){ Student s = it.next(); System.out.println(s); }
=> hs2에 담겨있는 객체들을 Iterator에 담음 (복사)
=> hasNext() : StringTokenizer의 hasMoreTokens ()와 비슷
=> 더 이상의 요소가 없을 시 NoSuchElementException 발생
-
HashMap<String, Snack> hm = new HashMap<>();=> 키값과 밸류값의 제네릭 모두 작성
-
put(K key, V value) : 키 밸류 세트로 추가시켜주는 메소드 *
- {키=밸류, 키=밸류, ...}
- 저장 순서 유지 안됨 / value값이 중복되어도 key값이 중복되지 않으면 저장 잘 됨
- 동일한 키값으로 다시 추가하는 경우 value값이 덮어씌워짐 (중복된 키값은 공존할 수 없음) => 키값은 식별자 같은 개념
-
get(Object key) : V ⇒ 컬렉션에서 해당 키값을 가지는 Value 값을 반환해주는 메소드 *
-
size() : 컬렉션에 담겨있는 객체들의 객수 반환
-
replace(K key, V value) => 컬렉션에서 해당 키값 찾아서 다시 전달한 Value값으로 수정
-
remove(Object key) : 컬렉션에서 해당 키값을 찾아서 그 키밸류 세트를 삭제시켜주는 메소드
-
map 공간에 담긴 모든 키 밸류 세트 다 접근 가능
-
반복문 안됨
-
ArrayList에 옮겨 담기 안됨
-
Iterator 반복자 이용
- 곧바로 iterator 메소드 호출 못함
- Map ⇒ Set ⇒ Iterator
① keySet() 이용
- hm.keySet() : Set
Set<String> keySet = hm.keySet();
- keySet.iterator() : Iterator
Iterator<String> itKey = keySet.iterator();
- 반복문 이용
while(itKey.hasNext()) { String key = /*(String)*/itKey.next(); Snack value = /*(Snack)*/hm.get(key); System.out.println(key + "=" + value); }
② entrySet() 이용
- hm.entrySet() : Set
Set<Entry<String, Snack>> entrySet = hm.entrySet();
- entrySet.iterator() : Iterator
entrySet.iterator() : Iterator
- 반복문 이용
while(itEntry.hasNext()) { Entry<String, Snack> entry = itEntry.next(); String key = entry.getKey(); Snack value = entry.getValue(); System.out.println(key + "=" + value); }
Properties prop = new Properties();=> 제네릭 설정 x
- Properties에 담겨있는 것들을 파일로 출력 또는 입력받아 올 때 주로 사용함
- store() : 파일로 저장 (출력)
내부적으로 Properties에 담겨있는 키, 밸류들을 String 형변환해서 출력함 => 키 밸류 세트 모두 문자열로 담을 때 주로 사용 - load() : 파일로부터 불러오기 (입력)
- store() : 파일로 저장 (출력)
- setProperty(String key, String value)
- 동일 키값 => 덮어씌워짐
- getProperty(String key) : String
- 존재하지 않는 키값 제시하면 null 반환 ** : 오타주의!
- store(OutputStream os, String comments)
- Properties 안에 담겨있는 Key-Value 세트들을 파일로 출력 (.properties)
try { prop.store(new FileOutputStream("test.properties"), "propertiesTest"); } catch (IOException e) { e.printStackTrace(); }
- Properties 안에 담겨있는 Key-Value 세트들을 파일로 출력 (.xml)
=> storeToXML()
try { prop.storeToXML(new FileOutputStream("test.xml"), "propertiesTest"); } catch (IOException e) { e.printStackTrace(); }
- Properties 안에 담겨있는 Key-Value 세트들을 파일로 출력 (.properties)
- load(InputStream is)
- .properties 파일 안에 담겨있는 Key-Value 세트들을 Properties 객체로 입력
try { prop.load(new FileInputStream("test.properties")); } catch (IOException e) { e.printStackTrace(); }
- .xml 파일 안에 담겨있는 Key-Value 세트들을 Properties 객체로 입력
=> loadFromXML()
try { prop.loadFromXML(new FileInputStream("test.xml")); } catch (IOException e) { e.printStackTrace(); }
- .properties 파일 안에 담겨있는 Key-Value 세트들을 Properties 객체로 입력
- .properties VS .xml
- .properties 파일
- 프로그램 상에 필요한 기본 환경설정 관련한 구문들 기술 (서버의 ip주소, dbms경로, 계정아이디, 계정비밀번호..)
- 해당 파일에 기술된 내용을 읽어들여서 자바에서 사용하게 됨
=> 모두 문자열이기 때문에 개발자가 아닌 일반인 관리자가 해당 문서를 쉽게 파악해서 수정하기 쉽다. - key-value 한 줄로 기술해야함
- .xml 파일 특징
- 프로그래밍 언어들간에 있어서 호환이 쉽다.
- value값이 시작태그와 종료태그 사이에만 존재하면 됨 (여러 줄 가능)
- .properties 파일