Bluetooth: controller: Fix Tx Buffer Overflow #31813
Conversation
57bc864 to
ce3c307
Compare
|
Using a memory barrier is overkill on a single-core CPU; generous use of |
There was a problem hiding this comment.
This is OK for now, but I feel this belongs somewhere in arch/ ?
There was a problem hiding this comment.
Will use it, when an interface is available in ARCH, but dont want to go into introducing one now which is going to to be ARM unique.
There was a problem hiding this comment.
Why not use CONFIG_CPU_CORTEX_M?
@ioannisg is this applicable to Cortex-A or -R as well?
There was a problem hiding this comment.
Why not use CONFIG_CPU_CORTEX_M?
It is just a choice to have explicit CPU check, to the architecture variants supported by controller, so that new ports are aware of this interface use.
There was a problem hiding this comment.
If the problem is the instruction re-ordering, i think we should try to solve it without asking the CPU to execute any instruction (DMB would eat 2 cycles, i think)
There was a problem hiding this comment.
It is just a choice to have explicit CPU check, to the architecture variants supported by controller, so that new ports are aware of this interface use.
I guess it's better to hide it under SOC_NORDIC_NRF5_COMPATIBLE or similar.
Otherwise, CPU_CORTEX_M is cleaner, I think.
First commit is for use of DMB instructions instead of DSB, data with instruction sync not needed in the controller, DMB sufficient.
It will work for Cortex-M0 but for Cortex-M4 with its Write Buffer, it is recommended to use DMB.
Use of volatile does not ensure that compiler will not reorder instructions, see this: |

There was a problem hiding this comment.
IF the problem is only the re-ordering, why use a data memory barrier? _DMB() is really not needed in Cortex-M. Instruction re-ordering could be avoided with a compiler barrier, or am I missing something?
There was a problem hiding this comment.
Based on ARM recommendation:
On microcontroller devices using the Cortex-M3 and Cortex-M4 processors, omission of the DMB instruction in semaphore and Mutex operations does not cause an error. However, this is not guaranteed if:
•the processor has a cache
•the software is used in a multi-core system.
ARM recommends that the DMB instruction should be used in semaphores and Mutex operations in OS designs.
will keep the DMB instruction to be safe with respect to if cache is implemented in processor.
There was a problem hiding this comment.
but that certainly does not apply to Cortex-M0, for example, and even M4, I am not sure.
My suggestion is to limit the solution to the minimal: Instruction re-orderning -> compliler barrier, so we are not hiding with DSB/DMB any other corner cases that we can not later detect and educate ourselves.
There was a problem hiding this comment.
As long as the Zephyr kernel code is using the recommendations, I will be against taking short cuts. Let zephyr kernel code, remove the use of DSB/DMB first. This is something yourself added in some places in the ARM architecture code.
There was a problem hiding this comment.
DMB should not really be added anywhere, if i remember correctly. If it is, it should be removed, agreed. As for DSB (and ISB), this is added, for reasons other than fighting instruction re-ordering. See relevant comments below :) .
There was a problem hiding this comment.
Could this be applied in the case above, as well?
There was a problem hiding this comment.
This solves the issue, but following the ARM recommendation, will keep the DMB instruction.
There was a problem hiding this comment.
A reason not to do this is, if you ever want this code to switch to using arch_ APIs; eventually we're going to get an ARM or even a cross-ARCH API to insert compiler barriers and avoid instruction re-ordering. Then if you already do what's needed here, migrating to generic API calls will be easier and backwards-compatible.
There was a problem hiding this comment.
Kernel code uses DSB/ISB instructions for both M0 and M4 architectures, maybe i understand the control path incorrectly, but they are there definitely in the cpu_idle.S, swap_helper.S to name a few.
When there is a cross-ARCH API available, the change can be done to reuse.
There was a problem hiding this comment.
Yeap, DSB, ISBs are used, for reasons explained inline (not related to compiler barrier placements)
There was a problem hiding this comment.
It doesn't matter so much, really, but I'd like the fix to contain only what was necessary, i.e. the compiler barrier, not the additional instruction, coming at a 2-cycle cost, for the reasons mentioned in the comments.
But it's not core ARCH code so I won't insist if you want to use _DMB.
core ARCH code does use DSB/ISB though, and was the inspiration (and ARM recommendation) to use _DMB. The 2-cycle cost is too much actually in the kernel, if I think of it for an architecture like M0/M3/M4, kernel does lot more swap compared to what BLE controller uses it for. |
Core ARCH uses these, not to battle instruction re-ordering but in real use-cases where it is important to do DSB (e.g. after WFI, or SCB register writes) or ISB (after CONTROL, BASEPRI register sets, etc.). But as I said, I won't insist agains __DMB(), after all, it is still CMSIS-compatible. |
C compiler is not used, the instruction order and ARM recommendations are implemented in assembly code. Example, DSB used here: zephyr/arch/arm/core/aarch32/swap_helper.S Line 554 in 8410a8c
For WFI example, I am refering to ARM Cortex™-M Programming Guide to Memory Barrier Instruction, Section 4.14 Entering sleep mode
Yet this is implemented as a recommendation, in the zephyr kernel. I dont see why controller code should not follow the ARM architectural recommendations to ensure that the write buffer on the processor has completed its operation before subsequent operations can be started. |
ce3c307 to
fba2bbf
Compare
|
I have now removed use of DMB for Cortex-M0, but retain it for Cortex-M4/M33, so as to be consistent with GCC builtins which use DMB as memory barrier when CONFIG_ATOMIC_OPERATIONS_BUILTIN=y Also, see that cpu_idle.S for Cortex-M0 has introduced ISR latency by using zephyr/arch/arm/core/aarch32/cpu_idle.S Line 98 in fec399e @ioannisg do you think I should remove use of DMB for Cortex-M33, seems GCC does not use DMB for ARMv8 architecture: |
|
@cvinayak DMB is really not needed in Cortex-M implementations, at least, I have not found yet a practical use case. I would consider removing it, yes. DSB, ISBs are a different story.
|
|
@ioannisg you may open up any of the Cortex-M4 Zephyr Bluetooth application's zephyr.lst file, which use GCC builtins and you will notice a lot of the builtins are enclosed with DMB instructions. These are just wasted CPU cycles. ok, I will remove the use of DMB in this PR. |
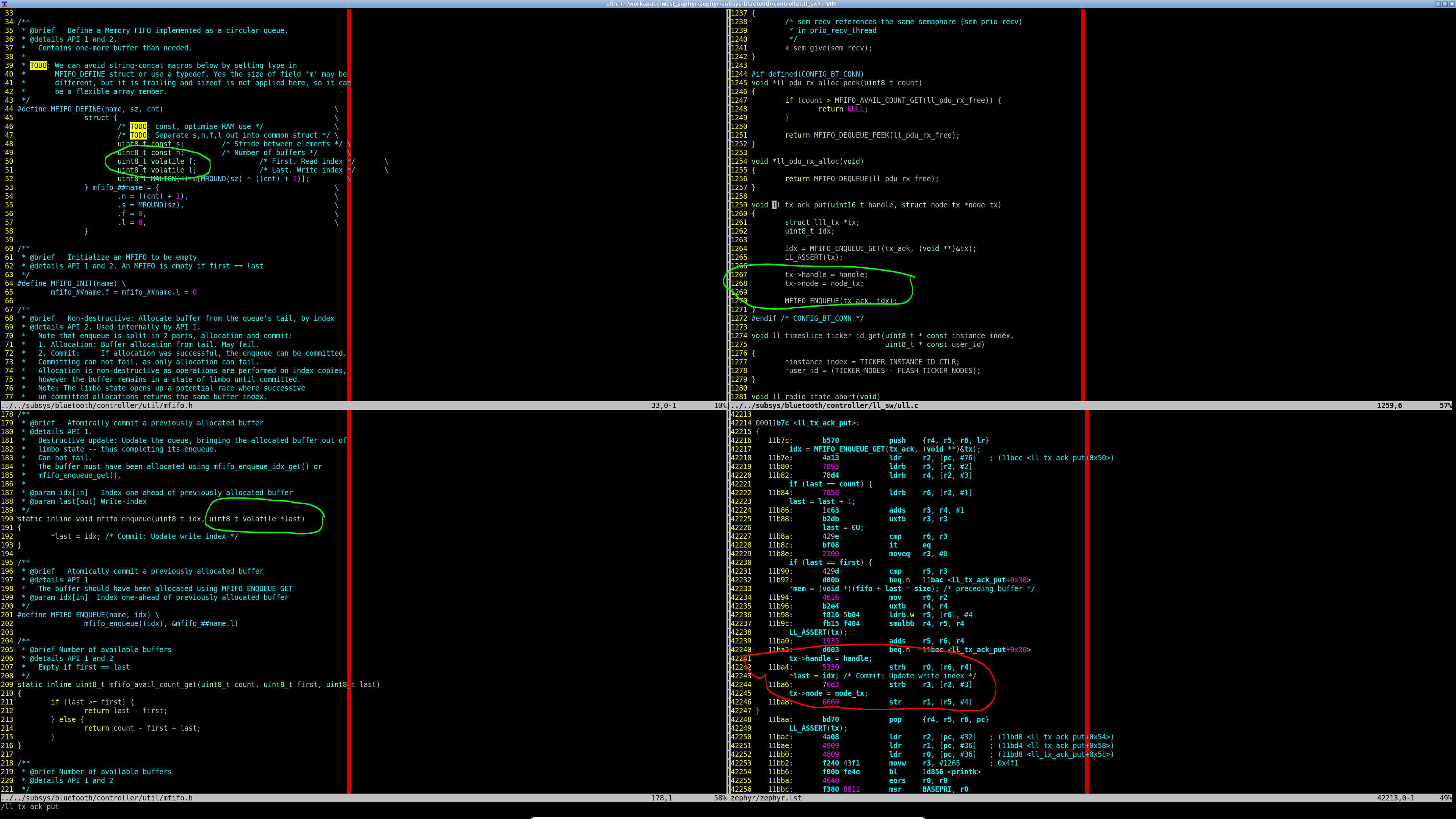
Use of Data Memory Barrier instruction with memory clobber in ARM Cortex M architectures is sufficient in the controller implementation to keep compiler data access instructions in order so that an ISR vectoring has memory accesses in the correct order as intented by design. Signed-off-by: Vinayak Kariappa Chettimada <vich@nordicsemi.no>
Fix Tx Buffer Overflow caused by uninitialized node_tx memory being used by ULL ISR context due to Compiler Instructions Reordering in the use of MFIFO_ENQUEUE. The MFIFO last index was committed before the data element was stored in the MFIFO due to Compiler Instructions Reordering. This is fixed now by adding a Data Memory Barrier instruction alongwith a compiler memory clobber. Fixes zephyrproject-rtos#30378. Signed-off-by: Vinayak Kariappa Chettimada <vich@nordicsemi.no>
fba2bbf to
ac8b90d
Compare
|
Thanks @cvinayak
As a side comment, IMHO, it is more practical to look at the implementation requirements, instead of the architecture requirements, to see what is really needed in the case of barriers (and other features). After all, we don't make any custom ARM-M design - we all implement the existing Cortex-M CPUs, so their implementation requirements is all what matters :) Anyways, as said, DMB won't harm you here, so wouldn't complain more (in case you ever want to bring this back) :) |
Fix Tx Buffer Overflow caused by uninitialized node_tx
memory being used by ULL ISR context due to Compiler
Instructions Reordering in the use of MFIFO_ENQUEUE.
The MFIFO last index was committed before the data element
was stored in the MFIFO due to Compiler Instructions
Reordering.
This is fixed now by adding a Data Memory Barrier
instruction alongwith a compiler memory clobber.
Fixes #30378.
Signed-off-by: Vinayak Kariappa Chettimada vich@nordicsemi.no