- 본 대회는 LG AI Research가 주최한 대회입니다.
- 공정 데이터를 활용하여 Rader 센서의 안테나 성능 예측을 위한 AI를 개발하는 것이 본 대회의 목표였습니다.
- 팀명은 1교시 통학러였으며, 저의 활동명은 통계가조아였습니다.
- 본 대회는 리더보드를 통하여 정량평가로 진행되었습니다.
- Rader는 자율주행 차에 있어 차량과의 거리, 상대속도, 방향 등을 측정해주는 필수적인 센서 부품입니다.
- 전기자동차, 자율주행차, 로보택시, 자율주행 택배로봇 등 Radar가 활용되는 시장은 점차 커지고 있습니다.
- 제품 종류도 기존 단거리, 중거리 및 장거리 Radar 뿐 아니라 차량 실내용 및 4D 이미징 Radar등 다변화 되는 추세입니다.
- LG에서는 제품의 성능 평가 공정에서 양품과 불량을 선별하고 있으며, AI 기술을 활용하여 공정 데이터와 제품 성능간 상관 분석을 통해 제품의 불량을 예측/분석하고, 수율을 극대화하여 불량으로 인한 제품 폐기 비용을 감축하려고 노력하고 있습니다.
- 해당 대회에서는 평가산식이 존재하였습니다.
- 평가 산식은 Normalized RMSE(NRMSE)를 사용하였습니다.
def lg_nrmse(gt, preds):
# 각 Y Feature별 NRMSE 총합
# Y_01 ~ Y_08 까지 20% 가중치 부여
all_nrmse = []
for idx in range(1,15): # ignore 'ID'
rmse = metrics.mean_squared_error(gt[:,idx], preds[:,idx], squared=False)
nrmse = rmse/np.mean(np.abs(gt[:,idx]))
all_nrmse.append(nrmse)
score = 1.2 * np.sum(all_nrmse[:8]) + 1.0 * np.sum(all_nrmse[8:14])
return score
-
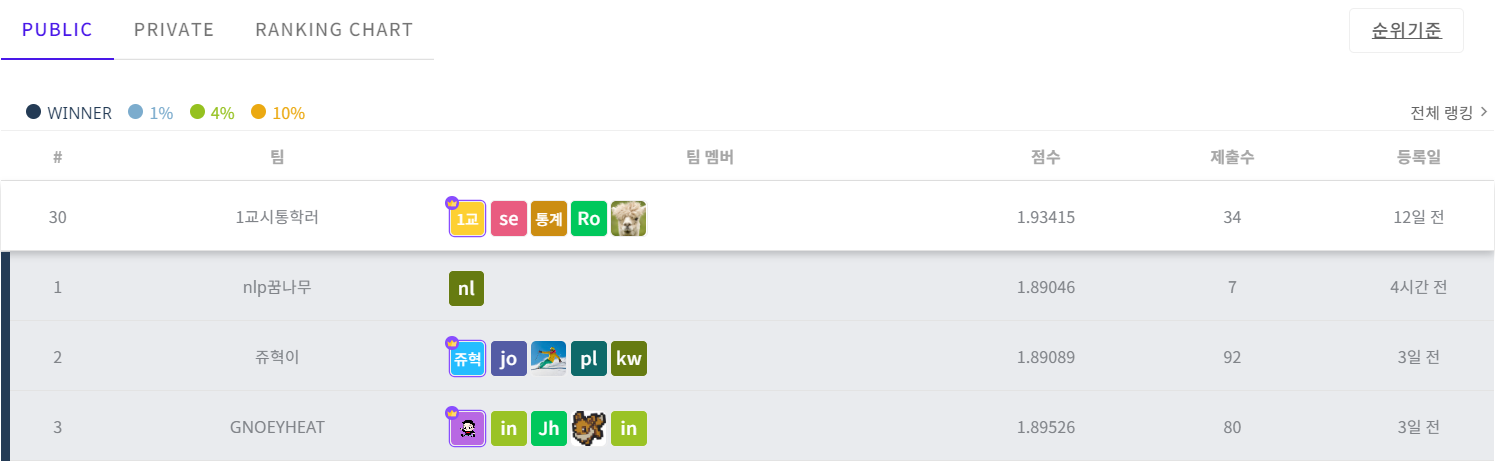
public : 30/988
-
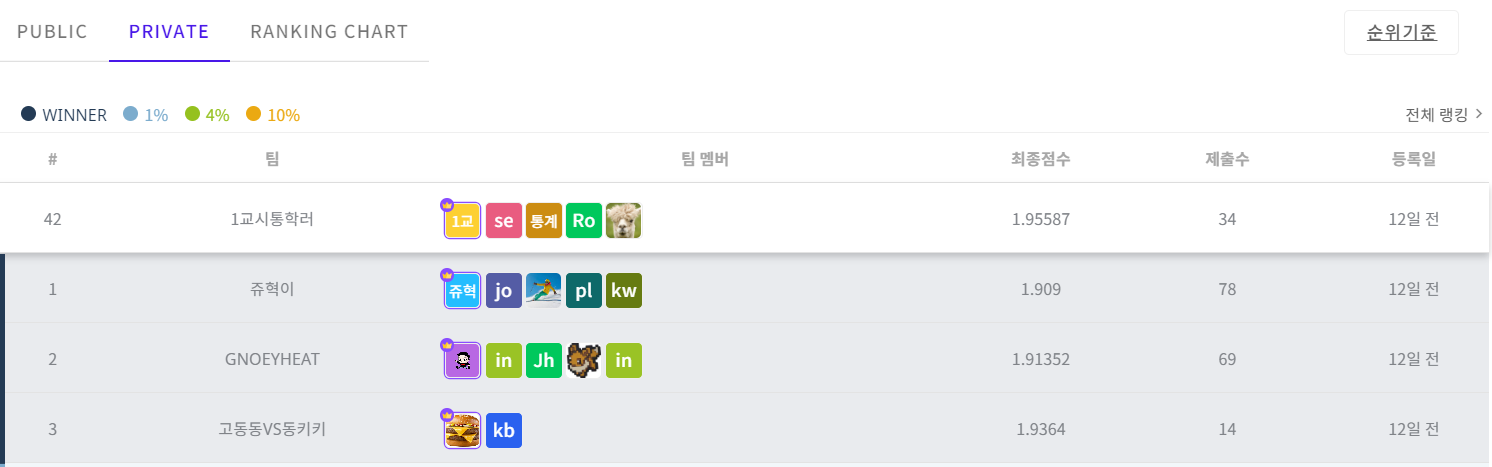
private : 42/988
-
교육 수료증

- LG AI 연구원에서 주관하는 LG Aimers / Data Intelligence 교육을 수료한 후, 해당 공모전을 진행하였습니다.
- 교육에서는 아래의 내용을 학습하였습니다.
- SPC
- 지도학습
- 비지도학습
- 설명 가능한 AI
- 인과추론
- 자율주행과 레이더센서의 이해
- 해당 프로젝트는 2가지 문제에 직면하게 되었다.
- 50여 개의 feature들로부터 각각의 성능지표에 대한 모델을 따로 만들어 14개의 서로 다른 성능 지표를 뽑아내야 했다.
- 정상품과 불량품의 데이터 분포를 비교해보았을 때 공정별 특징에 차이가 존재하지 않아서 딥러닝을 이용해 모델을 구축해 Seq2Seq로 데이터를 뽑아낼 경우, 정상과 불량 간의 안테나의 성능이 동일하게 예측되었다.
- 딥러닝을 이용하여 예측을 많이 진행해보았지만, 2번 문제가 해결되지 않아 딥러닝으로 분석하기 어려웠다. 이에 대한 기록은 Trial에 남긴다.
- 결국 머신러닝으로 문제를 해결해야 했지만, 1번 문제에 직면하게 되었다.
- 1번 문제를 해결하기 위해서 MultiOutput Regressor를 사용하였다.
- 베이지안 옵티마이제이션을 다중출력모델에 적용한 사례가 거의 없었으므로, 이에 대한 함수를 구축하여 다중출력모델에서도 베이지안 옵티마이제이션을 사용가능하도록 만들었다.
- MultiOutput catboost와 MultiOutput LGBM에 다중출력 베이지안 옵티마이저를 각각 적용한 후, 각각에서 성능이 제일 좋은 2가지 모델을 선정한 후, 가장 잘 나온 모델에 2/3의 가중치를, 그 다음으로 잘 나온 모델에 1/3의 가중치를 부여하여 예측한 결과가 성능이 가장 좋았다. 이에 대한 기록은 MODEL에 남긴다.
📦LG.RADER
┣ 📂EDA
┃ ┣ 📜ANOVA.ipynb
┃ ┣ 📜Correlation and Distribution.ipynb
┃ ┗ 📜NULL.ipynb
┣ 📂MODEL
┃ ┣ 📜MultiOutput_Catboost_Bayesian.ipynb
┃ ┣ 📜MultiOutput_LGBM_Bayesian.ipynb
┃ ┗ 📜Submission.ipynb
┣ 📂Trial
┣ 📂AutoEncoder
┃ ┗ 📜AutoEncoder.ipynb
┣ 📂LSTM
┃ ┣ 📜LSTM_for_Submit.ipynb
┃ ┗ 📜LSTM_for_Validation.ipynb
┣ 📂SDCFEModel
┃ ┣ 📜SDCFEModel_for_Submit.ipynb
┃ ┗ 📜SDCFEModel_for_Validation.ipynb
┗ 📂UNET-Ensemble
┗ 📜UNET-Ensemble_for_validation.ipynb
-
EDA : 통계적인 기법을 사용하여 데이터를 분석한 내용에 대해서 다룹니다.
- ANOVA.ipynb : 57개의 features가 14개의 targets에 영향을 미치는지를 분석하기 위해서 ANOVA 검정을 시행하였다. 이 때, 수치형변수들을 모두 범주화하였다.
- Correlation and Distribution.ipynb : features와 targets의 분포와 상관성을 조사하였다.
- NULL.ipynb : 결측값을 확인하고 보간하였다.
-
MODEL : 최종적으로 가장 성능이 우수한 모델에 대한 코드입니다.
- MultiOutput_Catboost_Bayesian.ipynb : MultiOutput Catboost 모델에 대해서 베이지안 옵티마이저로 하이퍼 파라미터 튜닝을 진행하였으며, 결과가 잘 나온 2개의 모델을 선정하였다.
- MultiOutput_LGBM_Bayesian.ipynb : MultiOutput LGBM 모델에 대해서 베이지안 옵티마이저로 하이퍼 파라미터 튜닝을 진행하였으며, 결과가 잘 나온 2개의 모델을 선정하였다.
- Submission.ipynb : MultiOutput_Catboost_Bayesian.ipynb과 MultiOutput_LGBM_Bayesian.ipynb에서 선정한 4개의 모델을 앙상블하여 최종 결과에 반영하였다.이 때, 각각의 모델에서 제일 잘 나온 모델에 2/3의 가중치를, 그 다음으로 잘 나온 모델에 1/3가중치를 부여하였다.
-
Trial : 문제를 해결하기 위해 여러 모델링을 시도한 코드입니다.
- AutoEncoder : AutoEncoder를 이용하여 모델을 구성해보았습니다.
- LSTM : LSTM layer를 이용하여 장기기억을 끌고가면서 모델을 학습시키면 성능이 더욱 좋을 것이라고 판단하여 이를 이용해 모델을 구성해보았습니다.
- SDCFEModel
- Seperate Dense Concat Fold Ensenble Model
- 연관이 있는 열을 하나로 묶고, 연관성이 있는 그룹들 각각을 Dense layer로 차원을 축소하여 잠재벡터를 만듦.
- 이 후, 해당 잠재벡터들을 모두 병합한 후, KFOLD 5로 5개의 모델을 각각 생성한 후, 모델들을 저장하고 Ensemble Method를 사용하여 5개의 모델을 모두 앙상블학습 시킴.
- UNET-Ensemble
- UNET의 구조를 착안하여 만든 모델로, UNET의 구조처럼 잠재벡터를 단계적으로 만들어나가면서, 단계별로 잠재벡터를 형성한다.
- UNET의 최하단에 진입했을 때, 다시 상단으로 올라가면서 예측값을 생성한다.
- 이 때, 상단으로 올라오는 단계별로 하단에서 만든 잠재벡터들을 아래에서 위로 끌어오면서, 모델이 하단으로 가면서 잃어버린 정보량을 최대한 보전하려고 노력한다.
- 이 후, 최상단에서는 최하단으로 진입하는 단계에서 단계적으로 생성한 잠재벡터들을 모두 고려한 결과값을 도출한다.
- 데이터의 경우 아래의 데이콘 사이트에서 참고하실 수 있습니다.
- 데이콘 사이트에 코드 공유도 진행하였으니, 같이 확인해보시면 좋습니다.
- email : ajc227ung@gmail.com