Models
| Model | PR | Average generation time | Cost | Average JSON size | Max JSON size | Notes |
|---|---|---|---|---|---|---|
| Claude Fable 5 | #50 | 18m 04s (1,084.4s) | $54.93 for 15 builds | 30.65 MiB | 97.39 MiB (worldtree) | Added as a first-class Anthropic model with max adaptive effort by default, a 128,000-token output cap, direct Anthropic/OpenRouter routing, and default sampling for restricted Fable requests |
| Claude 4.8 Opus | #41 | 24m 48s (1,487.9s) | $41.52 for 15 builds | 39.95 MiB | 244.38 MiB (worldtree) | Shown here for comparison |
(Note: Opus 4.8 was added in the previous release and is shown here only for comparison)
Notes
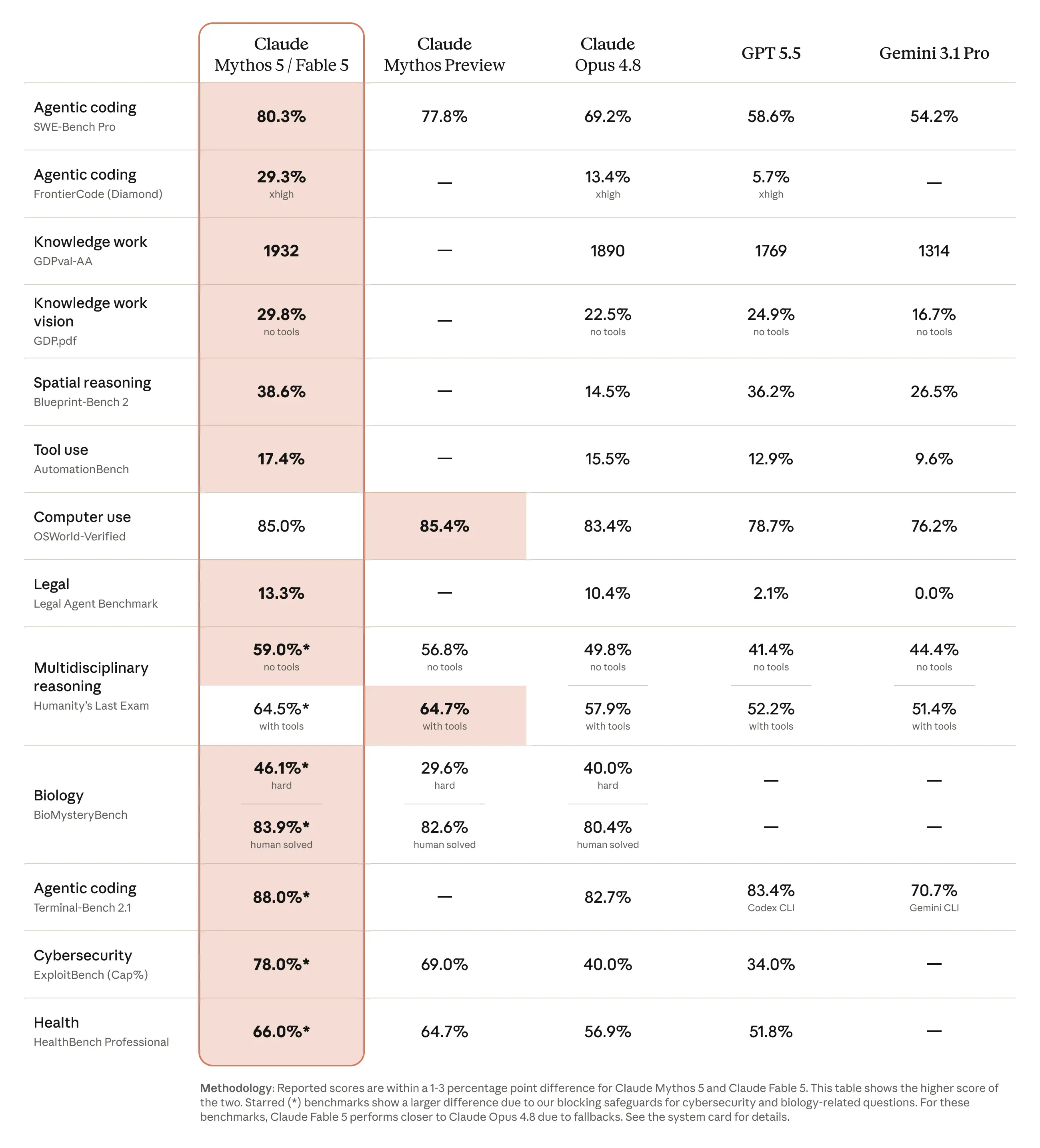
Fable was quite an interesting model in a way that's harder to describe, so I hope the posted statistics help convey my point. The model was surprisingly cheap (for its MineBench outputs anyway). In fact, I'm quite surprised, as in the web harness (Claude.ai), the model seems to think for much longer, but through the API calls you can see that it actually ended up thinking for less time than Opus 4.8 did.
Furthermore, I think the quality of the model's builds was very surprising: they don't seem as big of a leap over GPT 5.5 Pro as the the official benchmark scores might suggest, but the model clearly has very high attention to detail. For example, this is the first model that in the Arcade Machine build, actually created a correctly detailed screen (of PacMan), including the full layout, a score, and even a "1UP" label. Though it seems the model was quite conservative with its interpretation of the system-prompt, and (subjectively) not all of its builds were clearly more impressive than 4.8
{kind=link}
It's interesting how the model was able to make these detailed builds while keeping the overall JSON size lower in comparison to Opus 4.8, and while thinking for less time. Pure speculation: I think this might indicate why Claude Fable is supposedly much better at coding-related tasks; it actually completes the task with an intuitive approach and without adding excess.
Still, the results were quite surprising, so I reached out to the VoxelBench team, who also confirmed in their tests the builds were of generally much smaller size. They mentioned adding these two lines to the template produced much better builds in their case:
LEVEL OF DETAIL: MAXIMUM
BOUNDING BOX: UNLIMITED
Though we're not changing the MineBench system-prompt to cater to any specific models, I do think it's worth noting that one might be able to achieve much better results with improved prompting.
Lastly, despite the API costs being double that of Opus 4.8, Fable ended up actually only being ~30% more than 4.8, which is definitely a result of Fable producing much less tokens overall (though there's no comparison of CoT versus output tokens specifically).
What's Changed
Models
- Added Claude Fable 5 as a first-class Anthropic model with native Anthropic routing, OpenRouter fallback, max adaptive effort by default, and a 128,000-token output cap. #50
- Omitted non-default sampling parameters for Claude Fable 5 and Claude 4.8 Opus routes where the provider rejects them. #50, 27aa09b
- Added focused regression coverage for Fable catalog wiring, upload slug, direct Anthropic request shape, OpenRouter request shape, output cap, and max-effort traces. #50
Arena and Leaderboard
- Accounted for queued arena votes in coverage and matchup state so pending work is reflected before drain completion. #45
- Kept the queued-vote coverage cache warm, stabilized coverage refreshes, indexed vote job refreshes, replayed drained ratings, and guarded arena coverage eligibility. #45
- Added raw rating to leaderboard details. e51a120
Viewer, Exports, and Artifacts
- Tuned GIF export speed and quality and added a dedicated verification check for export configuration. #46
Maintenance
- Organized regression tests into clearer config, integration, repo, UI, and unit groups. #47
- Replaced script-level
npxcalls with package-manager-aware commands. #47 - Added named CI quality gates and hardened repository checks. #47
- Made export performance budgets opt-in and hardened regression test execution. #47
- Refreshed current-line dependencies and kept local testing docs aligned with the new command structure. #47
Changelog
- cfdff93 — (fix) account for queued arena votes
- ee8a2f4 — (fix) tune gif export speed and quality
- f9d07fa — Merge pull request #46 from Ammaar-Alam/codex/tune-gif-export-speed-quality
- 623a4f0 — (fix) keep queued vote coverage cache warm
- 271894d — (fix) stabilize arena coverage refresh
- 22f9335 — (fix) index arena vote job refreshes
- 8496fd0 — (fix) replay drained arena ratings
- ea2e36d — (fix) guard arena coverage eligibility
- fb929a6 — Merge pull request #45 from Ammaar-Alam/codex/fix-arena-vote-queue-matchmaking
- 27aa09b — (fix) omit OpenRouter Opus temperature
- e51a120 — (fix) adding raw-rating to leaderboard details
- 065bc63 — (refactor) organize regression tests
- 0c59cdb — (chore) remove npx from pnpm scripts
- 422a54a — (docs) keep test commands in local guide
- 2e86f17 — (test) make export perf budget opt-in
- 2daa1b6 — (ci) add named quality gates
- 52be097 — (chore) harden repository checks
- ac7e748 — (chore) refresh current-line dependencies
- f0fb685 — (fix) harden regression test execution
- 7f80887 — Merge pull request #47 from Ammaar-Alam/chore/repo-maintenance-cleanup
- 44a43e8 — (feat) add claude fable 5 support
- 5afcde0 — (fix) omit claude fable sampling parameters
Full Changelog: 3.6.0...3.7.0