
Note: Cloned from stefan-jansen/machine-learning-for-trading
Notebook to formulate an RL problem, applying model-based and model-free methods.
Application of value and policy iteration to a toy environment that consists of a 3 x 4 grid that's depicted in the following diagram with the following features:
States: 11 states represented as two-dimensional coordinates. One field is not accessible and the top two states in the rightmost column are terminal, that is, they end the episode.
Actions: Movements on each step, that is, up, down, left, and right. The environment is randomized so that actions can have unintended outcomes. For each action, there is an 80% probability to move to the expected state, and 10% probability to move in an adjacent direction (for example, right or left instead of up or up or down instead of right).
Rewards: As depicted in the right-hand side panel, each state results in -.02, except for the +1/-1 rewards in the terminal states:
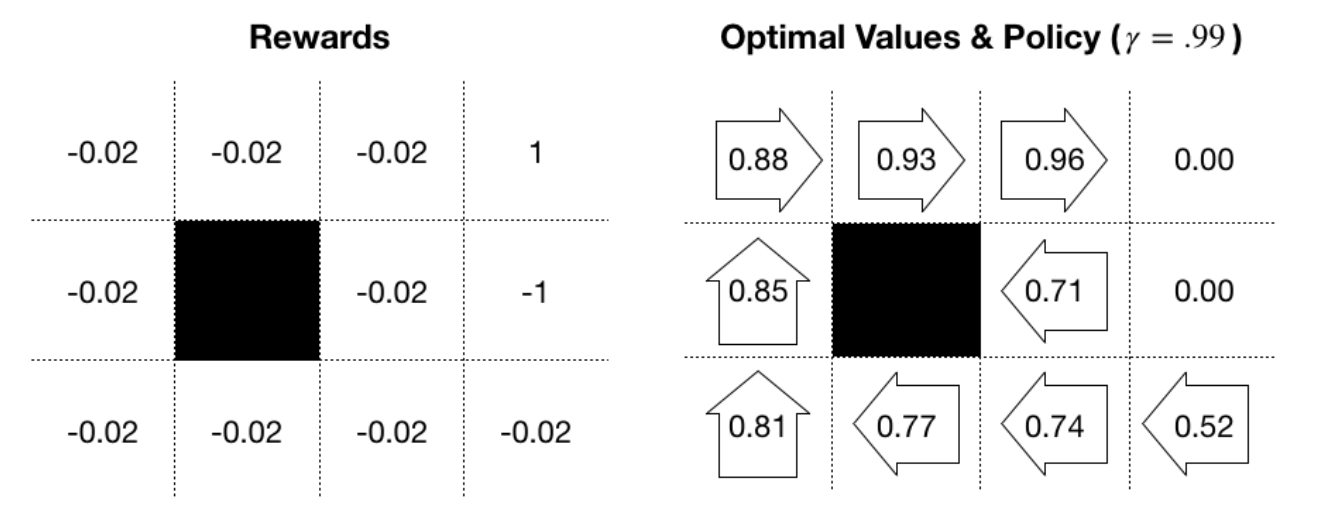
The right panel of the preceding GridWorld diagram shows the optimal value estimate that's produced by Value Iteration and the corresponding greedy policy. The negative rewards, combined with the uncertainty in the environment, produce an optimal policy that involves moving away from the negative terminal state.
The results are sensitive to both the rewards and the discount factor. The cost of the negative state affects the policy in the surrounding fields, and you should modify the example in the corresponding notebook to identify threshold levels that alter the optimal action selection.