PyTorch implementation of "Self-Supervised Acoustic Anomaly Detection via Contrastive Learning" (ICASSP 2022).
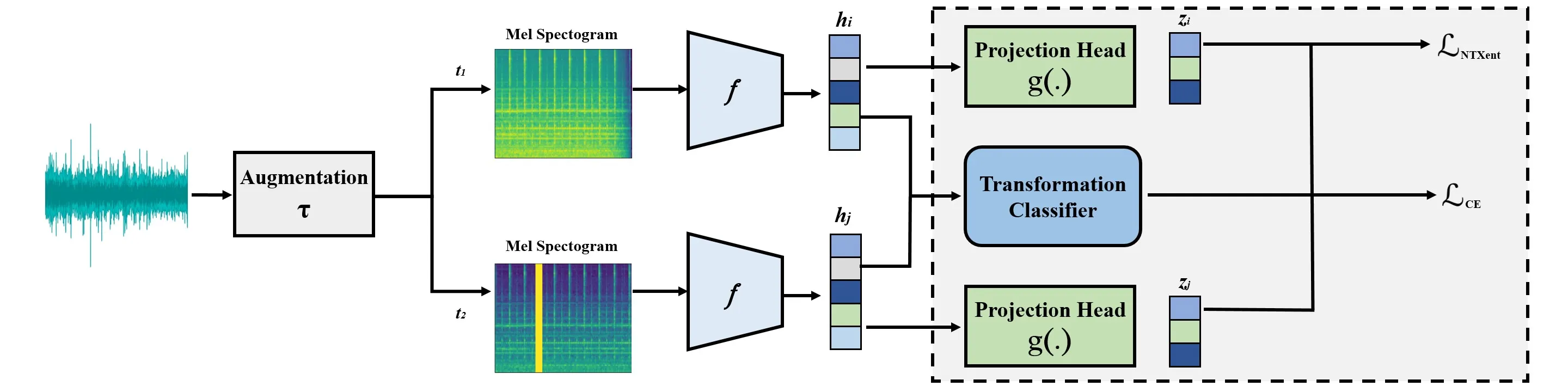
We propose an acoustic anomaly detection algorithm based on the framework of contrastive learning. Contrastive learning is a recently proposed self-supervised approach that has shown promising results in image classification and speech recognition. However, its application in anomaly detection is underexplored. Earlier studies have demonstrated that it can achieve state-of-the-art performance in image anomaly detection, but its capability in anomalous sound detection is yet to be investigated. For the first time, we propose a contrastive learning-based framework that is suitable for acoustic anomaly detection. Since most existing contrastive learning approaches are targeted toward images, the effect of other data transformations on the performance of the algorithm is unknown. Our framework learns a representation from unlabeled data by applying audio-specific data augmentations. We show that in the resulting latent space, normal and abnormal points are distinguishable. Experiments conducted on the MIMII dataset confirm that our approach can outperform competing methods in detecting anomalies.
git clone https://github.com/hhojjati/AADSCL.git
cd AADSCL
pip install -e .This installs all dependencies (PyTorch, torchaudio, librosa, etc.) and registers the aadscl command.
This project uses the MIMII dataset.
- Download the dataset from the link above.
- Place
.wavfiles underdata/following this structure:
data/
└── Pump/ # or Fan, Valve, Slider
├── normal/
│ ├── 00000000.wav
│ └── ...
└── abnormal/
├── 00000000.wav
└── ...
For the full dataset with multiple machine IDs, use: data/<machine>/id_<XX>/normal/. Both layouts are auto-detected. See data/README.md for details.
aadscl --machine Pump --epochs 400Or equivalently:
python -m aadscl --machine Pump --epochs 400aadscl --machine Pump --pretrain --save_path state_dict_model.pt| Argument | Default | Description |
|---|---|---|
--machine |
Pump |
Machine type: Pump, Fan, Valve, Slider |
--id |
0 |
Machine ID (0, 2, 4, 6) |
--epochs |
400 |
Number of training epochs |
--pretrain |
False |
Load pretrained model instead of training |
--save_path |
state_dict_model.pt |
Path to save/load model weights |
--verbosity |
1 |
0 = silent, 1 = print epoch loss |
--num_runs |
5 |
Number of evaluation runs to average |
├── aadscl/ # Main package
│ ├── main.py # Entry point: train + evaluate pipeline
│ ├── train_test.py # Data splitting into train/test loaders
│ ├── trainer.py # Training loop (contrastive + classification loss)
│ ├── test.py # Evaluation with Mahalanobis distance & AUC
│ ├── utils.py # Transforms, augmentation pipeline, anomaly scoring
│ ├── data_loader.py # MIMII dataset loader
│ ├── networks/
│ │ ├── resnet18.py # ResNet-18 encoder (1-channel input for spectrograms)
│ │ ├── projection_head.py # MLP projection head (512 → 256 → 128)
│ │ └── linear_classifier.py # Linear classifier for transform prediction (8 classes)
│ └── transforms/
│ ├── mel_spec.py # Mel spectrogram extraction (128 mel bins, 2048 FFT)
│ ├── awgn.py # Additive White Gaussian Noise
│ ├── fade.py # Fade in/out
│ ├── freq_mask.py # Frequency masking
│ ├── time_mask.py # Time masking
│ ├── time_shift.py # Time shifting
│ ├── time_stretch.py # Time stretching
│ └── pitch_shift.py # Pitch shifting
├── data/ # Dataset directory (see Dataset Setup)
├── pyproject.toml # Package configuration & dependencies
├── requirements.txt # Dependency list (also in pyproject.toml)
├── Makefile # Convenience commands
└── LICENSE
- Augmentation: Each audio sample is augmented twice using random audio transforms (noise injection, pitch shift, time stretch, fade, masking, time shift, identity)
- Encoding: Augmented Mel spectrograms are fed through a ResNet-18 encoder
- Contrastive Loss: NT-Xent loss (τ=0.07) pulls together representations of two augmented views from the same sample
- Auxiliary Task: A linear classifier predicts the applied transform type (cross-entropy, weighted by λ=0.1)
- Anomaly Scoring: At inference, Mahalanobis distance from the normal training distribution serves as the anomaly score
Paper on IEEE Xplore.
@inproceedings{hojjati2022selfsupervised,
author={Hojjati, Hadi and Armanfard, Narges},
booktitle={ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
title={Self-Supervised Acoustic Anomaly Detection Via Contrastive Learning},
year={2022},
pages={3253-3257},
doi={10.1109/ICASSP43922.2022.9746207}
}See LICENSE for details.