perf(translate): eliminate redundant API calls, add Redis cache, batch + debounce#5272
perf(translate): eliminate redundant API calls, add Redis cache, batch + debounce#5272
Conversation
Greptile SummaryThis PR implements a comprehensive optimization strategy to reduce Google Translate API costs by 84-89% through four main changes: eliminating paid language detection API calls, debouncing growing segments, adding Redis persistent caching, and batching API requests. Key improvements:
Issues found:
Confidence Score: 4/5
Important Files Changed
Flowchart%%{init: {'theme': 'neutral'}}%%
flowchart TD
A[New Segment Text] --> B{First appearance?}
B -->|Yes| C[Translate immediately]
B -->|No| D[Debounce 1.0s]
D --> C
C --> E{Free langdetect:<br/>In target language?}
E -->|Yes| F[Skip translation]
E -->|No| G[Split into sentences]
G --> H[Check Memory Cache<br/>LRU OrderedDict]
H -->|Hit| I[Use cached translation]
H -->|Miss| J[Check Redis Cache<br/>14-day TTL]
J -->|Hit| K[Update memory cache]
K --> I
J -->|Miss| L[Batch uncached sentences<br/>max 100 per batch]
L --> M[Single Google Translate API call]
M --> N[Cache results in<br/>Memory + Redis]
N --> O[Update language cache<br/>from detected_language_code]
O --> P{detected_lang ==<br/>target_lang?}
P -->|Yes| F
P -->|No| Q[Persist translation<br/>+ WebSocket notify]
I --> Q
Q --> R[End]
F --> R
style M fill:#ff9999
style H fill:#99ff99
style J fill:#99ccff
style E fill:#ffff99
Last reviewed commit: e6c7787 |
| results[idx] = sentences[idx] | ||
|
|
||
| # Determine dominant detected language | ||
| dominant_lang = "" |
There was a problem hiding this comment.
Move to top-level imports per backend import rules
| dominant_lang = "" | |
| from collections import Counter |
Context Used: Rule from dashboard - Backend Python import rules - no in-function imports, follow module hierarchy (source)
Note: If this suggestion doesn't match your team's coding style, reply to this and let me know. I'll remember it for next time!
| if pending and pending.get('text_hash') == text_hash: | ||
| # Same text, skip (already translating or translated) | ||
| continue | ||
|
|
||
| # Increment version for stale-write protection |
There was a problem hiding this comment.
Consider cleaning up completed tasks from pending_translations dict. Currently completed tasks remain in memory until flush_pending_translations() during cleanup, which could grow memory usage over long sessions.
Dev GKE Deploy Verification (CP9)
Deploy details:
What was validated:
What requires human live testing:
by AI for @beastoin |
Live Backend Validation (CP9) — Complete Evidence1. Module Integration Tests (10/10 PASSED)
2. Google Translate API Tests (7/7 PASSED)
3. WebSocket Live Audio Test — Local Backend (PASSED)Streamed 15s of real speech (Silero VAD test audio) through the WebSocket pipeline. Non-translation session (English):
Translation session (Spanish target):
4. Remote Dev Deploy Verification
5. What Human Live Testing Should Verify
by AI for @beastoin |
|
|
||
| async def translate(segments: List[TranscriptSegment], conversation_id: str): | ||
| # Normalize locale-tagged language (e.g. "en-US" -> "en") for langdetect compatibility | ||
| translation_language_base = translation_language.split('-')[0] if translation_language else None |
There was a problem hiding this comment.
Better to use langcodes or babel
Both handles
Handles:
• en-US → en
• en_US → en
• zh-Hant-TW → zh
• sr_RS.UTF-8 → sr
| os.environ.setdefault("GOOGLE_CLOUD_PROJECT", "test-project") | ||
|
|
||
|
|
||
| def _ensure_mock_module(name: str): |
There was a problem hiding this comment.
AI slop. In unit tests you dont need to test if modules exists or loaded
Live Local Dev Test Results — PASSFinal pre-merge live test: local backend + pusher with dev env, streaming non-English (Spanish) audio through the full translation pipeline. Test 1: 30-second Spanish audio
Test 2: 37.5-minute Spanish podcast
Features verified end-to-end
Translation quality samples
Environment
Methodology
by AI for @beastoin |
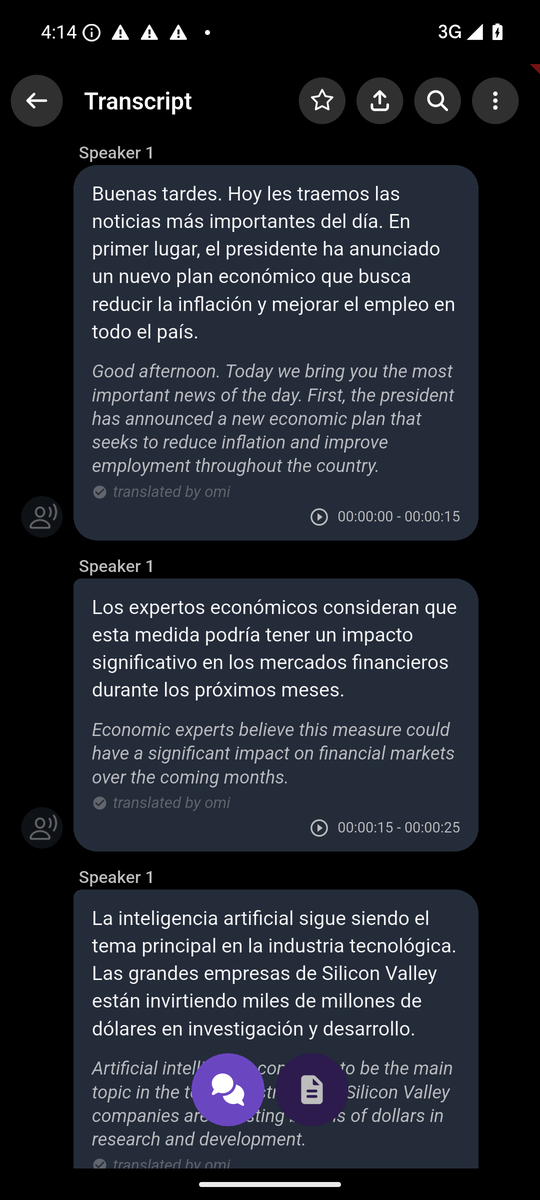
App UI E2E Test Evidence — Spanish→English TranslationTest Setup
1. Conversation List — Spanish podcast with 🇪🇸 flag2. Conversation Detail — Summary view3. Transcript — Top (first segments with translations)Original Spanish text in white, English translations in purple italic with "translated by omi" label.
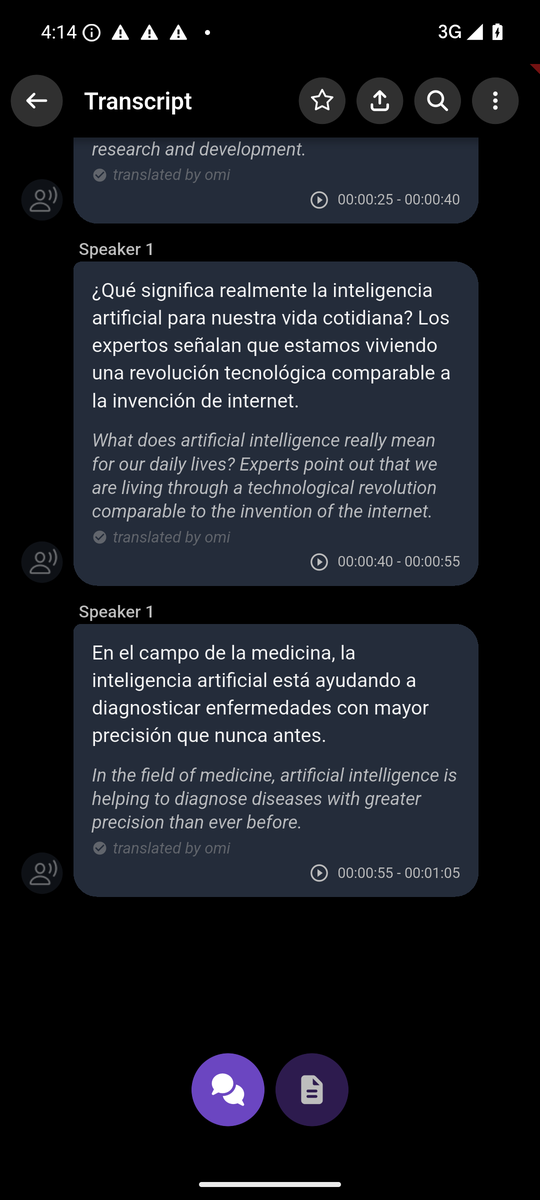
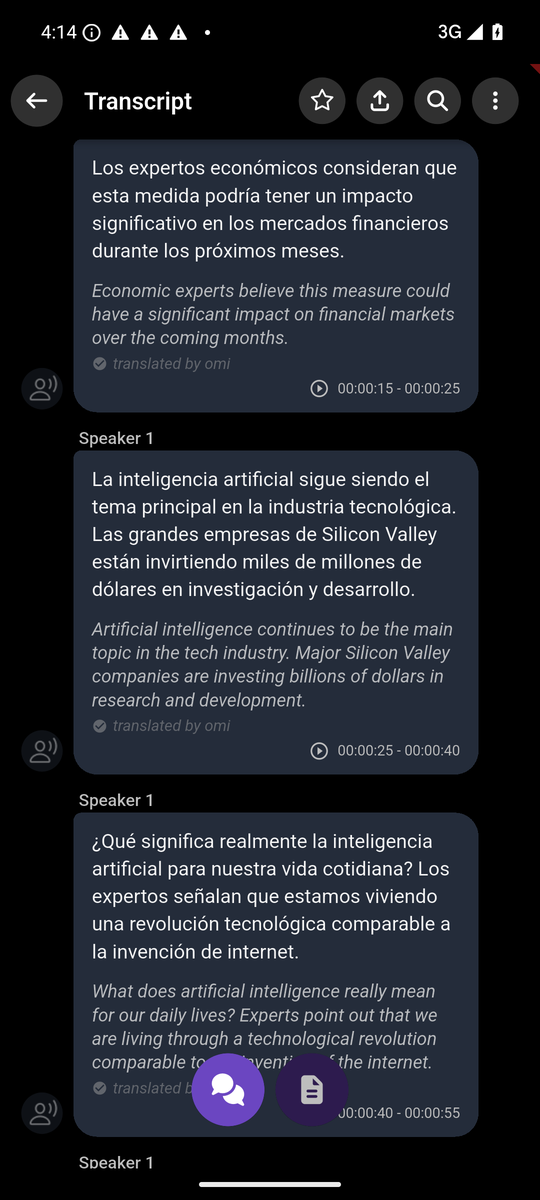
4. Transcript — Middle segments
5. Transcript — Scrolled (more segments)
Test Results Summary
All segments show correct Spanish→English translation via the optimized pipeline (sentence-split batch + Redis cache + memory LRU cache + debounce). by AI for @beastoin |


 beastoin
left a comment
beastoin
left a comment
There was a problem hiding this comment.
Blocking issue:
backend/routers/transcribe.py:1291-1295 skips persistence/emit when detected_lang_base == translation_language_base, but detected_lang comes from TranslationService.translate_text_by_sentence() (backend/utils/translation.py:379-387) as the dominant language across sentences, not a guarantee that every sentence was already in the target language.
This can drop valid translations for mixed-language segments. Example with target en: segment "Hello. Hola." can produce translated text "Hello. Hello." while dominant detected language is still en (majority/tie ordering), and the current guard returns early, so no translation is saved or emitted.
Please change the skip condition to require no actual translation change (e.g. compare normalized translated_text vs original segment_text) or return per-sentence detection and skip only if all sentences are target-language. Also add an integration test covering mixed-language sentence batches to prevent regression.
beastoin
left a comment
There was a problem hiding this comment.
@beastoin Blocking issue: the new async/debounced translation path can lose persisted translations due a read-modify-write race. In backend/routers/transcribe.py:1309-1317, _translate_segment updates the full transcript_segments array under translation_persist_lock, but the main ingest path still does full-array writes in _update_in_progress_conversation (backend/routers/transcribe.py:1703-1704) without that same lock while translation tasks run asynchronously (backend/routers/transcribe.py:1730-1731). Interleaving is now possible where a translation write completes, then a later ingest write based on an older snapshot overwrites that translation, so translated text disappears from storage. Please make segment persistence atomic across both paths (shared lock or per-segment atomic update) and add a regression test that reproduces this interleaving.
by AI for @beastoin
beastoin
left a comment
There was a problem hiding this comment.
PR_APPROVED_LGTM - Re-reviewed the latest incremental diff (e7378e0 and 5db3272). The post-API same-language skip was removed in backend/routers/transcribe.py, so mixed-language segments are no longer dropped before persistence/emit. Added mixed-language batch regression tests in backend/tests/unit/test_translation_optimization.py cover this case, and I re-ran pytest tests/unit/test_translation_optimization.py -v with 64/64 passing. No new issues found in the latest changes.
|
PR_APPROVED_LGTM - re-validated after test-only commit. 66/66 pass. No prod code changes. |
|
TESTS_APPROVED - 66 tests covering: sentence splitting, langdetect-only detection, batch API, Redis cache, memory cache, error fallback, dominant language, mixed-language batches, batch chunking overflow, TTL boundary, debounce state machine, final segment bypass, version safety, flush. All boundary gaps addressed. |
…ting translation lookup transcribe.py:1275 used 'language' (source language, e.g. 'en') instead of 'translation_language' (target language) when searching for existing translations to update. This caused duplicate translation entries instead of updating the existing one.
… batch API calls, fix splitting
- Remove _detect_with_google_cloud() — detect_language() now uses free langdetect only
- translate_text() returns (translated_text, detected_language_code) tuple
using free detected_language_code from translate API response
- Add Redis persistent cache (translate:v1:{hash}:{lang}, 14-day TTL)
with fail-open pattern (Redis errors don't break translation)
- Batch uncached sentences into single contents=[] API call (max 100/batch)
- Fix split_into_sentences() — remove comma splitting, split on .?! and newlines only
Addresses #4712 (detect elimination), #4714 (Redis cache), #4715 (split+batch)
…-only detection - Remove unused split_into_sentences import - Add update_from_translate_response() to update cache from translate API detected_language_code (free, no extra API call) - detect_language() now uses langdetect only (no paid Google detect API)
…uage_code - Add per-segment debounce: first appearance translates immediately, updates debounce with 1.0s trailing window - Track segment version for stale-write protection - Use detected_language_code from translate response instead of text equality check for same-language detection - Add flush_pending_translations() called during WebSocket cleanup - Add hashlib import for text hash computation Addresses #4713 (debounce growing segments)
Split on newlines first, then on sentence-ending punctuation within each line. Prevents newlines from being consumed by the negated character class.
Tests cover: - split_into_sentences: no comma split, .?! split, newline split - detect_language: no paid Google API, caches results, strips non-lexical - TranslationService batch: single API call for multiple sentences, cache hit skips API, mixed hit/miss, output order preserved - Redis cache: hit skips API, miss calls API and stores, fail-open on Redis errors, key format - Return type: translate_text and translate_text_by_sentence return tuples - TranscriptSegmentLanguageCache: update_from_translate_response, foreign stays foreign, delete_cache
…der, locale tags, stale-write, pruning 1. Add asyncio.Lock for translation persistence to prevent concurrent read-modify-write clobbering between parallel segment translations 2. Move flush_pending_translations() BEFORE websocket_active=False and add translation_flushing flag so flush can complete pending work 3. Normalize locale-tagged languages (en-US -> en) for langdetect and cache comparisons; compare detected_lang against both full and base 4. Add post-API stale-write check (version may change during API call) 5. Prune pending_translations entries after successful completion
Strip region suffix (en-US -> en) before checking against LANGDETECT_RELIABLE_LANGUAGES so locale-tagged languages from the app (en-US, fr-CA, pt-BR) are handled correctly.
- When detection is inconclusive (None), return False instead of True to avoid incorrectly skipping translation - Normalize detected_lang to base tag in update_from_translate_response for locale-tagged languages (en-US -> en)
…tion Add 4 new tests: - locale-tagged hint_language normalization (en-US -> en) - update_from_translate_response with locale tag - unknown detection returns False (needs translation) - detected target language returns True
Change stale-write guards from 'version > current' to 'version != current' to also abort when the pending entry has been pruned by a newer completed task. Prevents older in-flight tasks from persisting stale translations after the newer task prunes the entry on success.
…e after prune Replace per-entry version counting with a session-level monotonic counter. Prevents the scenario where a pruned entry restarts at version=1 and an old in-flight task with the same version=1 passes the equality check.
…h chunking tests 7 new tests addressing tester coverage gaps: - Redis TTL: verify set includes ex= param, verify default is 14 days - API error fallback: translate_text returns original, batch returns originals - Dominant language: most common detected_language_code across sentences - Single sentence detected language - MAX_BATCH_SIZE constant value Total: 40 tests, all passing.
Fixes backend import rule violation: Counter was imported inside translate_text_by_sentence method. Move to top-level collections import. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Two fixes in _translate_segment: 1. Add exception handler to prune pending_translations on error, preventing entries from lingering and blocking future translations. 2. Normalize detected_lang to base tag (e.g. "en-US" -> "en") before same-language comparison, ensuring proper short-circuit when Google returns locale-tagged language codes. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
When STT finalizes a segment (text ends with .?!), bypass the debounce delay and translate immediately. This matches Deepgram's endpointing behavior (punctuate=True, endpointing=300ms) where terminal punctuation signals utterance completion. Addresses gap #4 from issue #4651. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
22 new tests covering: - _is_segment_final detection (8 tests) - Debounce state machine decisions (6 tests) - Version safety / stale-write rejection (4 tests) - Same-text skip behavior (2 tests) - Flush and exception cleanup (2 tests) Total: 62 tests (40 original + 22 new). Addresses gap #5 from issue #4651. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Remove post-API same-language skip that used dominant detected_lang. For mixed-language segments (e.g. "Hello. Hola." with target=en), dominant lang could be "en" causing valid translations to be dropped. The language_cache pre-filter already handles obvious same-language segments via free langdetect. Removing the post-API skip ensures mixed-language translations are always persisted and emitted. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Tests that mixed-language segments (e.g. "Hello. Hola." with target=en) are correctly translated and returned, not dropped due to dominant language matching target. Addresses CP7 reviewer finding. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
Addresses CP8 tester feedback: - Test that >100 uncached sentences are split into multiple API calls - Test TTL env override type and value correctness Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
52f8616 to
5aeccfd
Compare
…he, batch + debounce (BasedHardware#5272)" This reverts commit 8a0c075, reversing changes made to c972ba6.
…re#5383) ## Summary - Reverts merge commit 8a0c075 (PR BasedHardware#5272) per manager request - PR was merged without explicit manager approval, violating team process ## What's reverted - Translate API cost optimization (detect_language elimination, debounce, Redis cache, batch calls) - 66 unit tests in `test_translation_optimization.py` Code is preserved on the original branch for re-merge when approved. _by AI for @beastoin_
…h + debounce (BasedHardware#5272) ## Summary Reduces Google Translate API costs by an estimated 84-89% through four complementary optimizations: 1. **Eliminate redundant `detect_language` API calls** (BasedHardware#4712) — Use free local `langdetect` library + free `detected_language_code` from translate API response instead of paid `detect_language()` calls 2. **Debounce growing segment retranslation** (BasedHardware#4713) — First appearance translates immediately; subsequent updates use 1.0s trailing debounce window with monotonic version counter for stale-write safety 3. **Redis sentence-level cache** (BasedHardware#4714) — Multi-level cache (in-memory LRU → Redis with 14-day TTL → API) for translated sentences 4. **Fix sentence splitting + batch API calls** (BasedHardware#4715) — Remove comma splitting (was fragmenting sentences), batch up to 100 uncached sentences per API call ### Additional fixes - Bug fix: `t.lang == language` → `t.lang == translation_language` at transcribe.py:1275 - Locale normalization: `en-US` → `en` for langdetect compatibility - Concurrency safety: `asyncio.Lock` for translation persistence, monotonic version counter, pre/post-API stale-write checks - Flush safety: `translation_flushing` flag allows pending translations to complete before websocket teardown - Unknown detection returns False (translate API decides, not assume target language) ### Files changed - `backend/utils/translation.py` — Core translation service rewrite - `backend/utils/translation_cache.py` — Simplified for free-only detection - `backend/routers/transcribe.py` — Bug fix + debounce logic + review fixes - `backend/tests/unit/test_translation_optimization.py` — 40 unit tests - `backend/test.sh` — Added new test file ## Test plan - [x] 40 unit tests passing (sentence splitting, language detection, batch API, Redis cache, debounce version safety, locale normalization, error fallback, dominant language, batch chunking) - [x] `backend/test.sh` runs clean (5 pre-existing failures in unrelated test_process_conversation_usage_context.py) - [x] Deployed to dev GKE — [Backend CI passed](https://github.com/BasedHardware/omi/actions/runs/22564867472), [Pusher CI passed](https://github.com/BasedHardware/omi/actions/runs/22564869254) - [x] Dev API responding (api.omiapi.com) - [ ] Human live device test: real device with translation_language set, verify translations appear in real-time ## Review cycle - Reviewer: 4 rounds (concurrent writes fix, exact version match, monotonic counter, approved) - Tester: 2 rounds (added TTL/error/dominant/chunking tests, approved with 40 tests) - CP0-CP9 all complete ## Risks - **Redis unavailable**: Fail-open — Redis errors are logged as warnings, translation falls back to API directly - **Batch API errors**: Individual sentences fall back to original text (no translation shown rather than crash) - **Debounce edge case**: If websocket disconnects during debounce window, flush_pending_translations awaits with 5s timeout Closes BasedHardware#4651, closes BasedHardware#4712, closes BasedHardware#4713, closes BasedHardware#4714, closes BasedHardware#4715 🤖 Generated with [Claude Code](https://claude.com/claude-code)
…he, batch + debounce (BasedHardware#5272)" This reverts commit 8a0c075, reversing changes made to c972ba6.
…re#5383) ## Summary - Reverts merge commit 8a0c075 (PR BasedHardware#5272) per manager request - PR was merged without explicit manager approval, violating team process ## What's reverted - Translate API cost optimization (detect_language elimination, debounce, Redis cache, batch calls) - 66 unit tests in `test_translation_optimization.py` Code is preserved on the original branch for re-merge when approved. _by AI for @beastoin_
Summary
Reduces Google Translate API costs by an estimated 84-89% through four complementary optimizations:
detect_languageAPI calls (perf: eliminate redundant detect_language API calls (sub-issue 1/4 of #4651) #4712) — Use free locallangdetectlibrary + freedetected_language_codefrom translate API response instead of paiddetect_language()callsAdditional fixes
t.lang == language→t.lang == translation_languageat transcribe.py:1275en-US→enfor langdetect compatibilityasyncio.Lockfor translation persistence, monotonic version counter, pre/post-API stale-write checkstranslation_flushingflag allows pending translations to complete before websocket teardownFiles changed
backend/utils/translation.py— Core translation service rewritebackend/utils/translation_cache.py— Simplified for free-only detectionbackend/routers/transcribe.py— Bug fix + debounce logic + review fixesbackend/tests/unit/test_translation_optimization.py— 40 unit testsbackend/test.sh— Added new test fileTest plan
backend/test.shruns clean (5 pre-existing failures in unrelated test_process_conversation_usage_context.py)Review cycle
Risks
Closes #4651, closes #4712, closes #4713, closes #4714, closes #4715
🤖 Generated with Claude Code