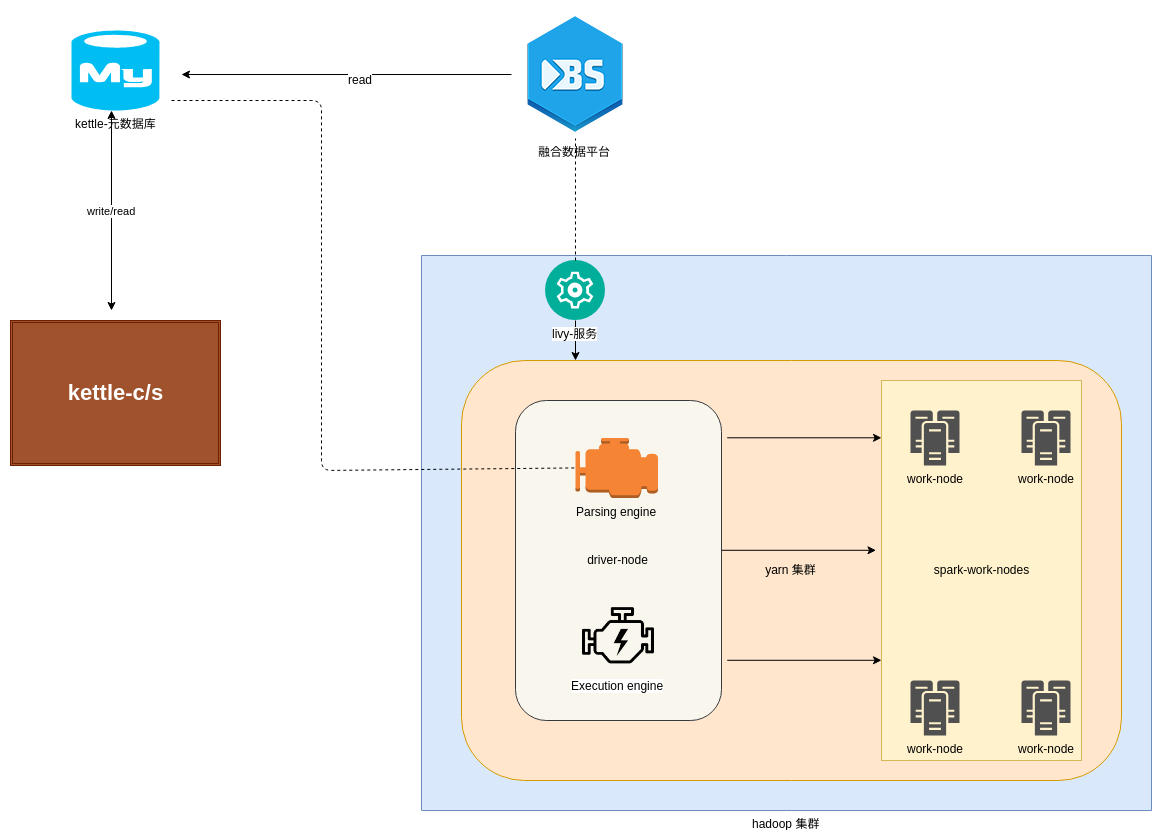
BlueSky is based on a pentaho-kettle metadata, Spark as a low-level ETL platform, pentaho-kettle created tasks can be run on Spark, a pentaho-kettle big data version of the plug-in. At the same time, it also supports the spark streaming data fusion scenario. Currently, it supports kafka as a data pipeline for spark streaming. The core idea of this platform is to use the pentaho-kettle metadata as the Spark running parameter. The core architecture is inspired by the pentaho-kettle architecture. DATAFRAM is used as the data reference for the flow between components. The JOB submission based on the stream processing architecture is serial. The JOB run is distributed. This platform needs to translate the components of pentaho-kettle. The currently translated components are switchcase, tableoutput, filterrows, update, delete, kafkaconsumer, deleterow, input, output, multiwaymergejoin, selectvalues, convergence, kafkaproducer, TableInput, groupbydata, mergejoin.
The flow chart is as follows: