feature: hBayesDM version 2.0#182
Conversation
Remove three working planning documents from the tracked tree. Files remain on disk locally but are no longer part of the repository going forward. Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
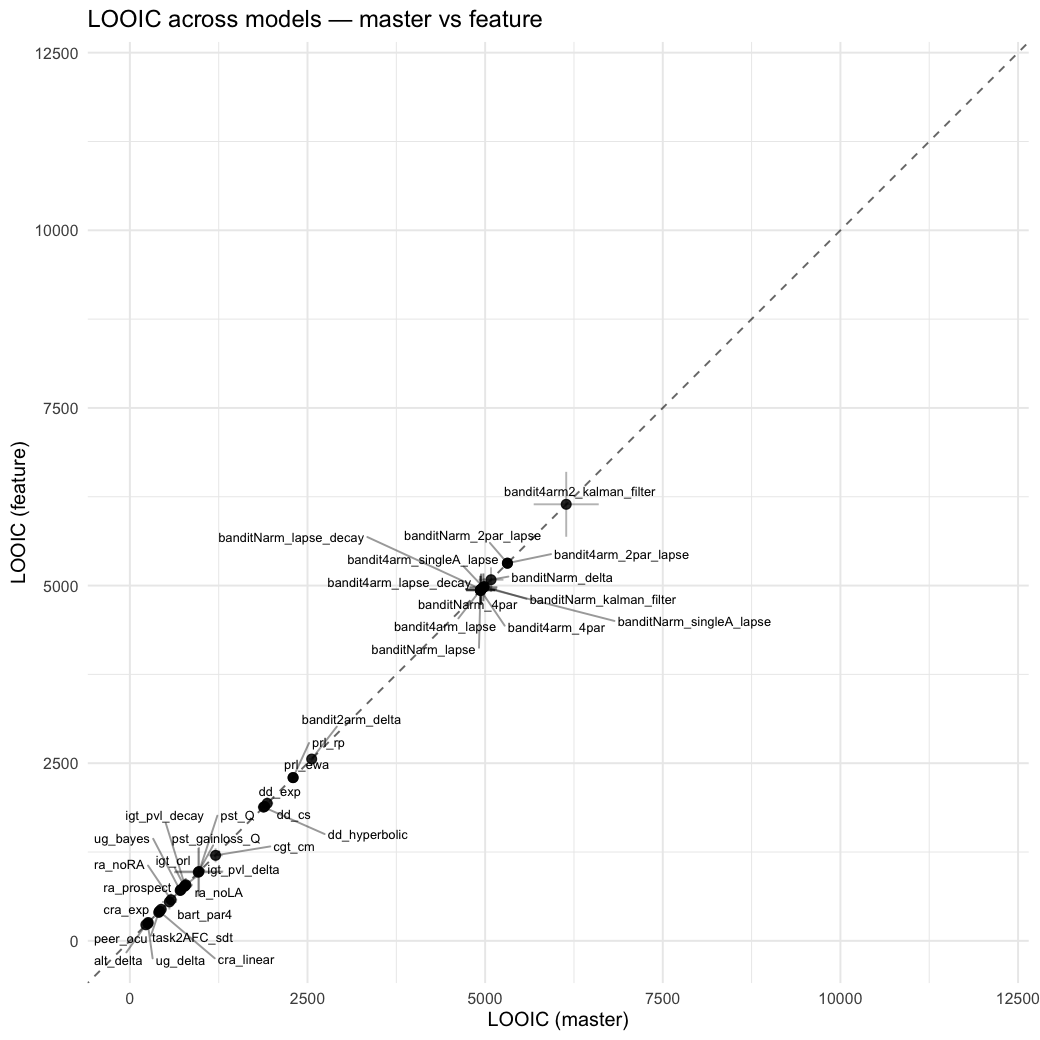
Behavioral equivalence: master (rstan/hBayesDM 1.3.1) vs this branch (cmdstanr/2.0)To verify the cmdstan-2.0 port produces equivalent posteriors, I fit each shared model on both backends to the package example data with matched sampler settings ( Master was installed from the 1.3.1 release into a parallel R library path; per-subject summaries were extracted via 36 models paired successfully. Remaining models on master deterministically segfaulted inside rstan 2.32.x's QuickJS-based Across-model summaryLOOIC, master vs feature — error bars are LOO SE.
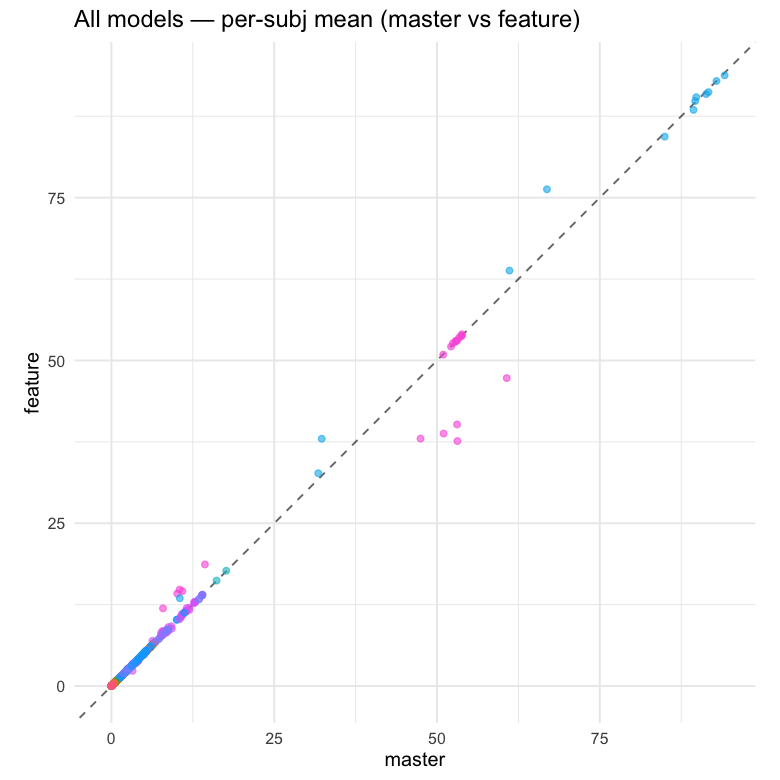
All per-subject posterior means, pooled across models and parameters.
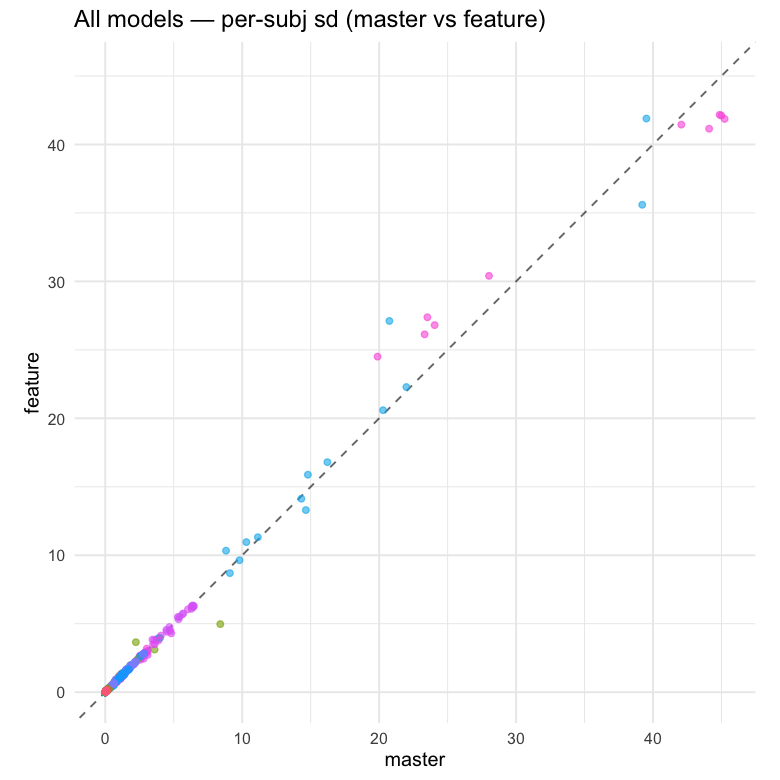
All per-subject posterior SDs, pooled across models and parameters.
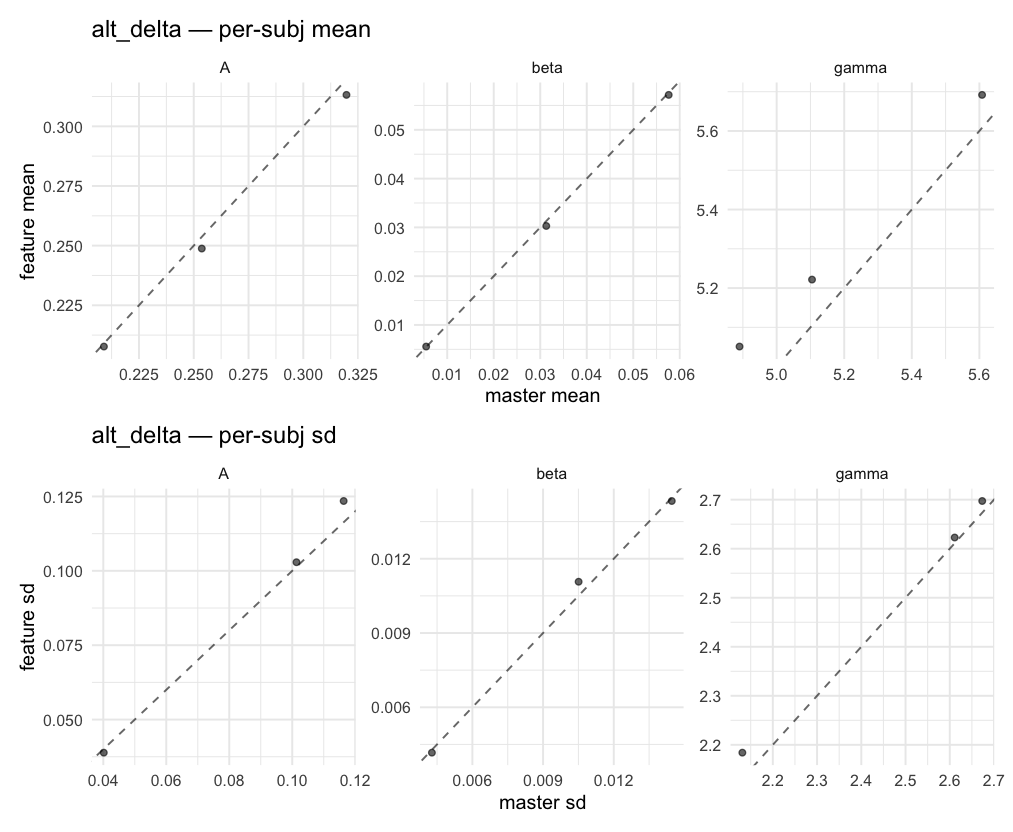
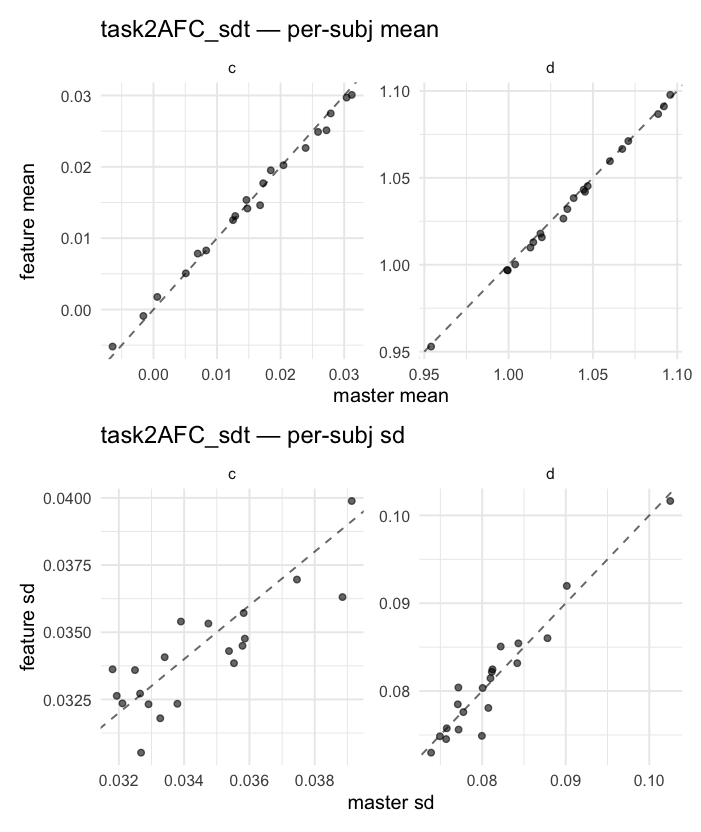
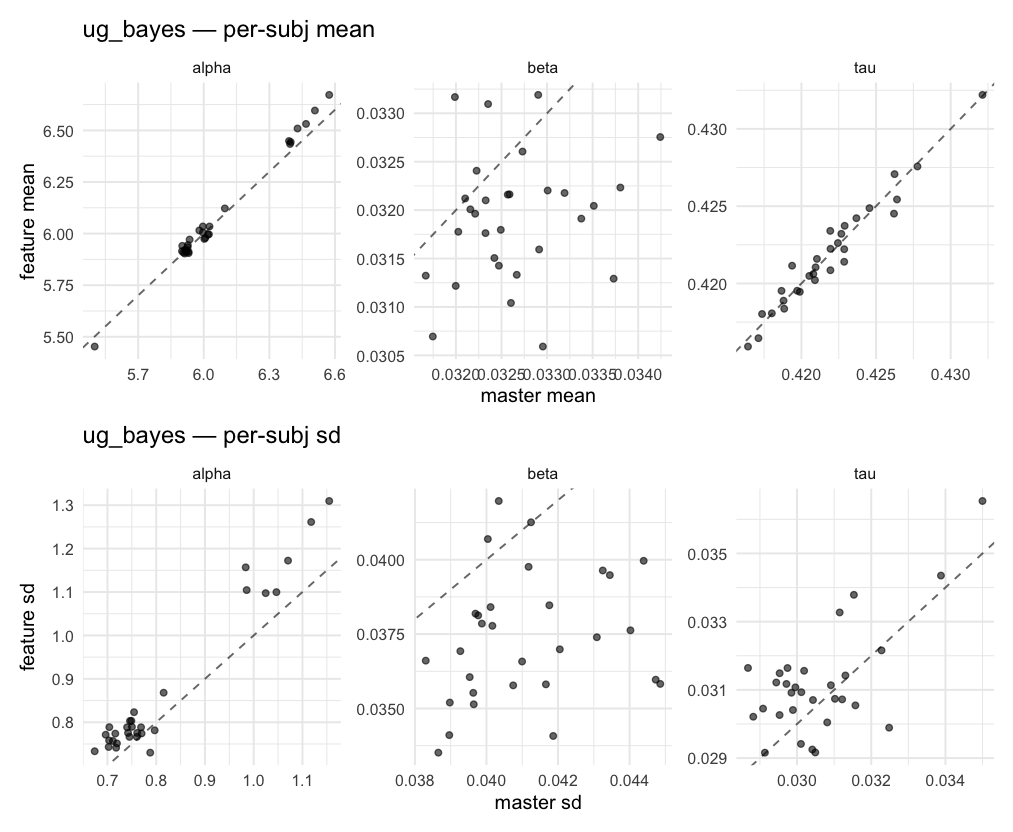
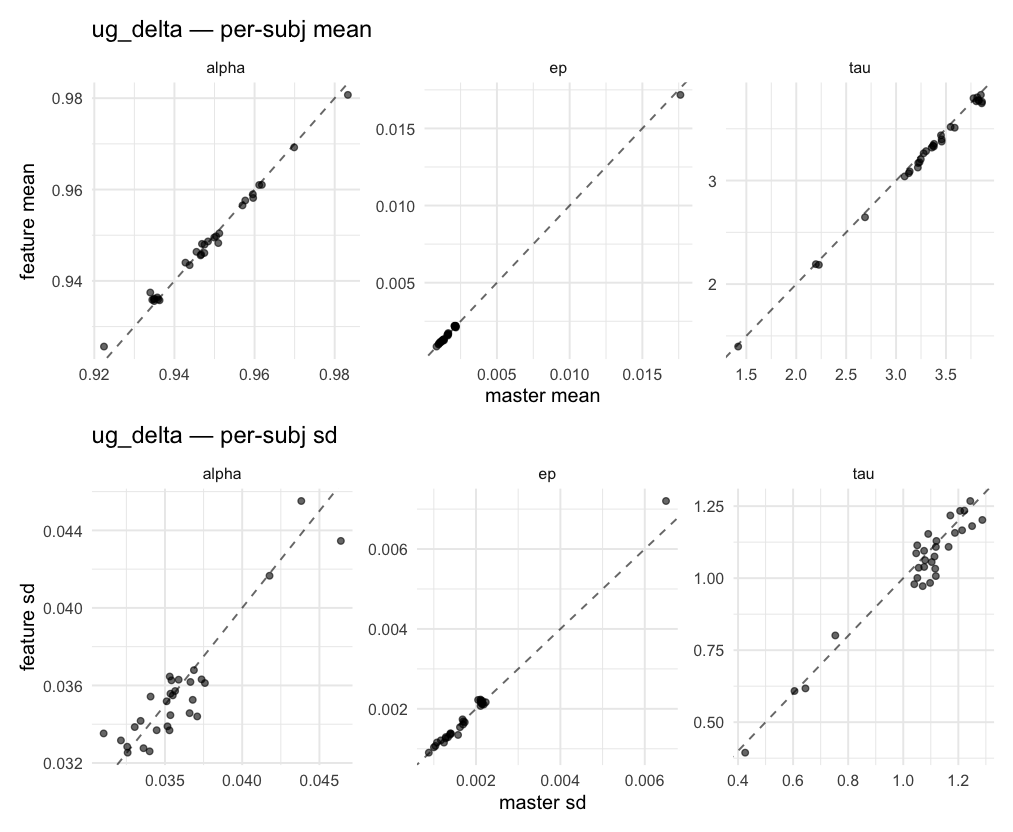
Per-model parameter scattersEach model gets a 2-row figure: top row = per-subject posterior mean (master x, feature y), faceted by parameter; bottom row = per-subject posterior SD, same layout. Identity line drawn for reference.
|
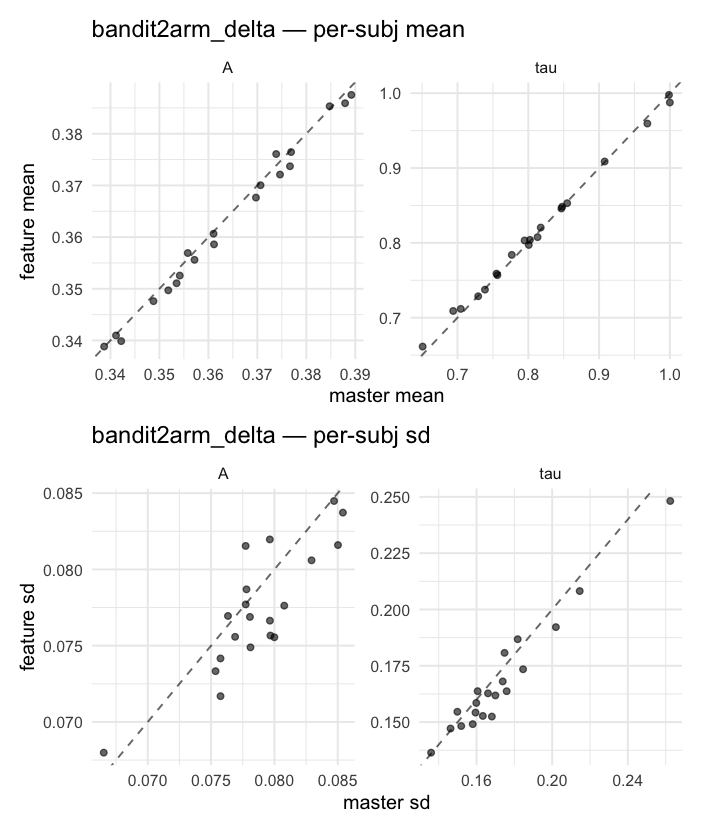
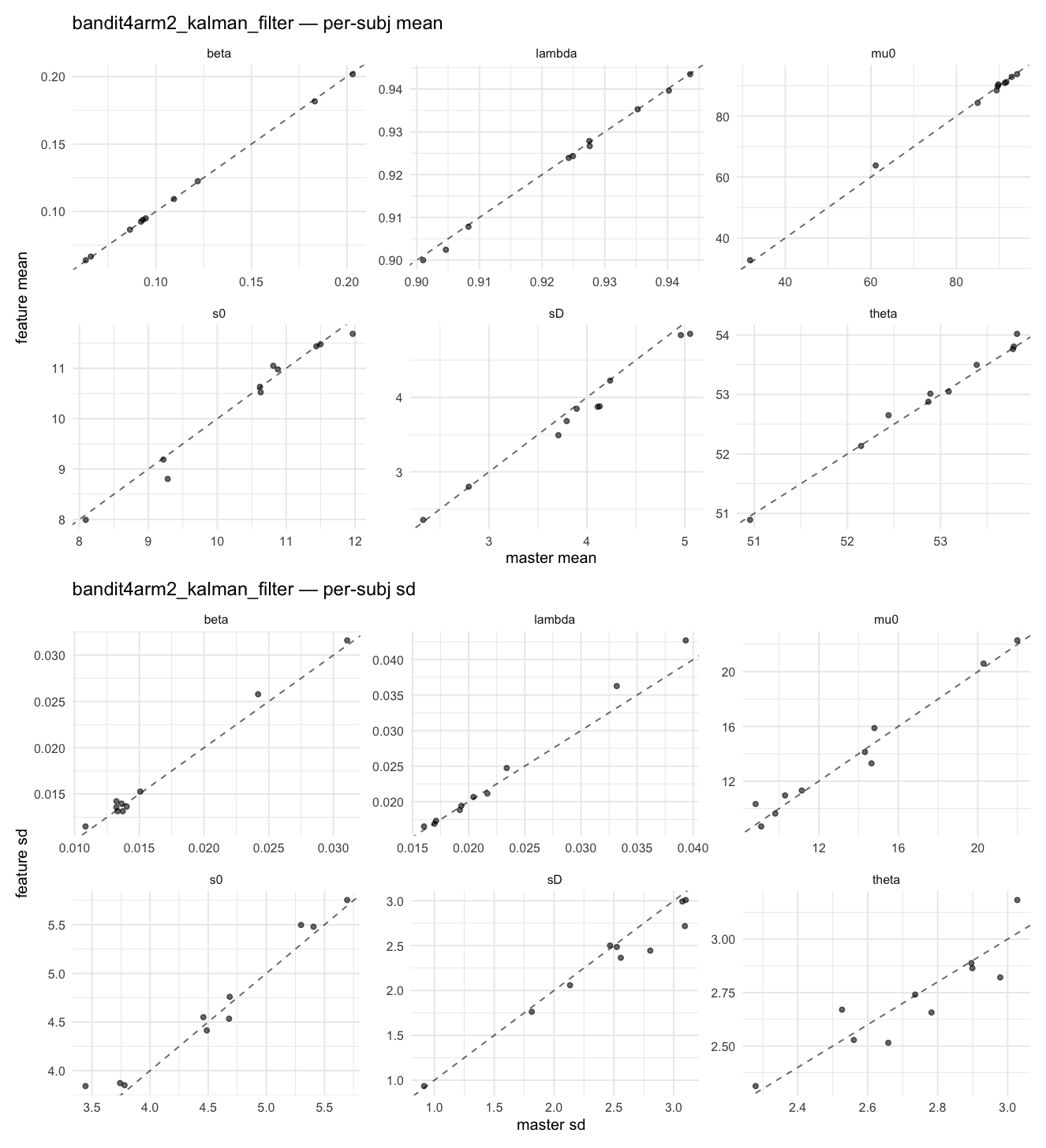
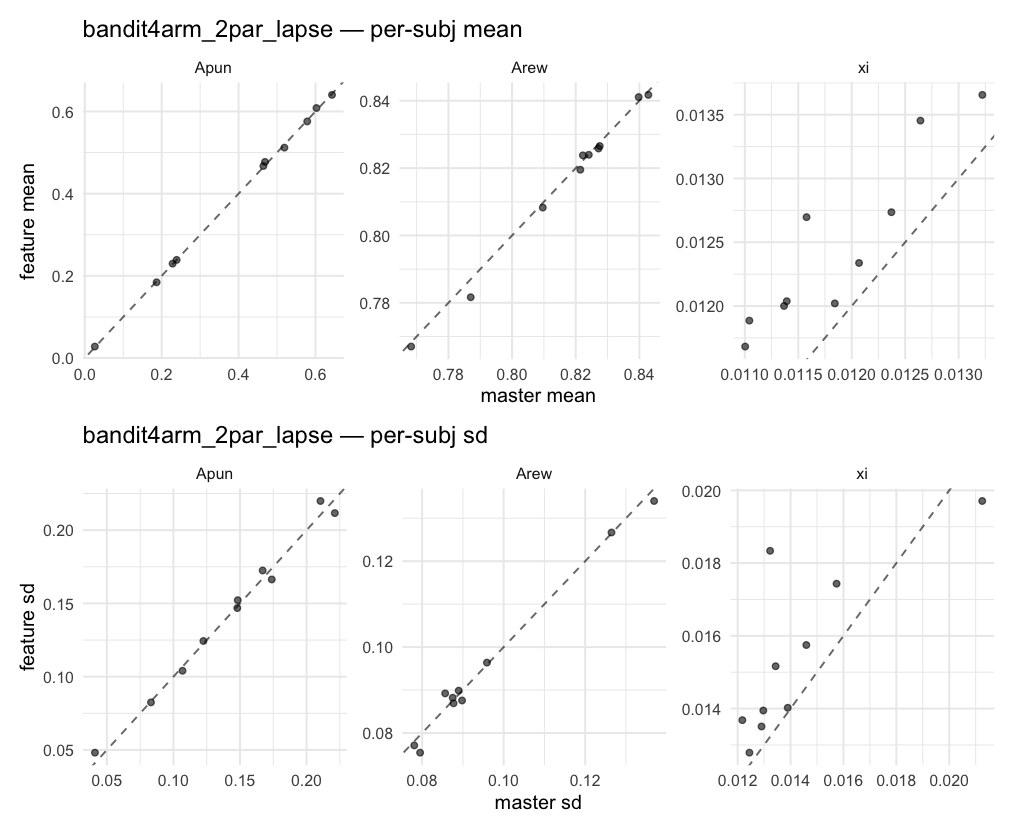
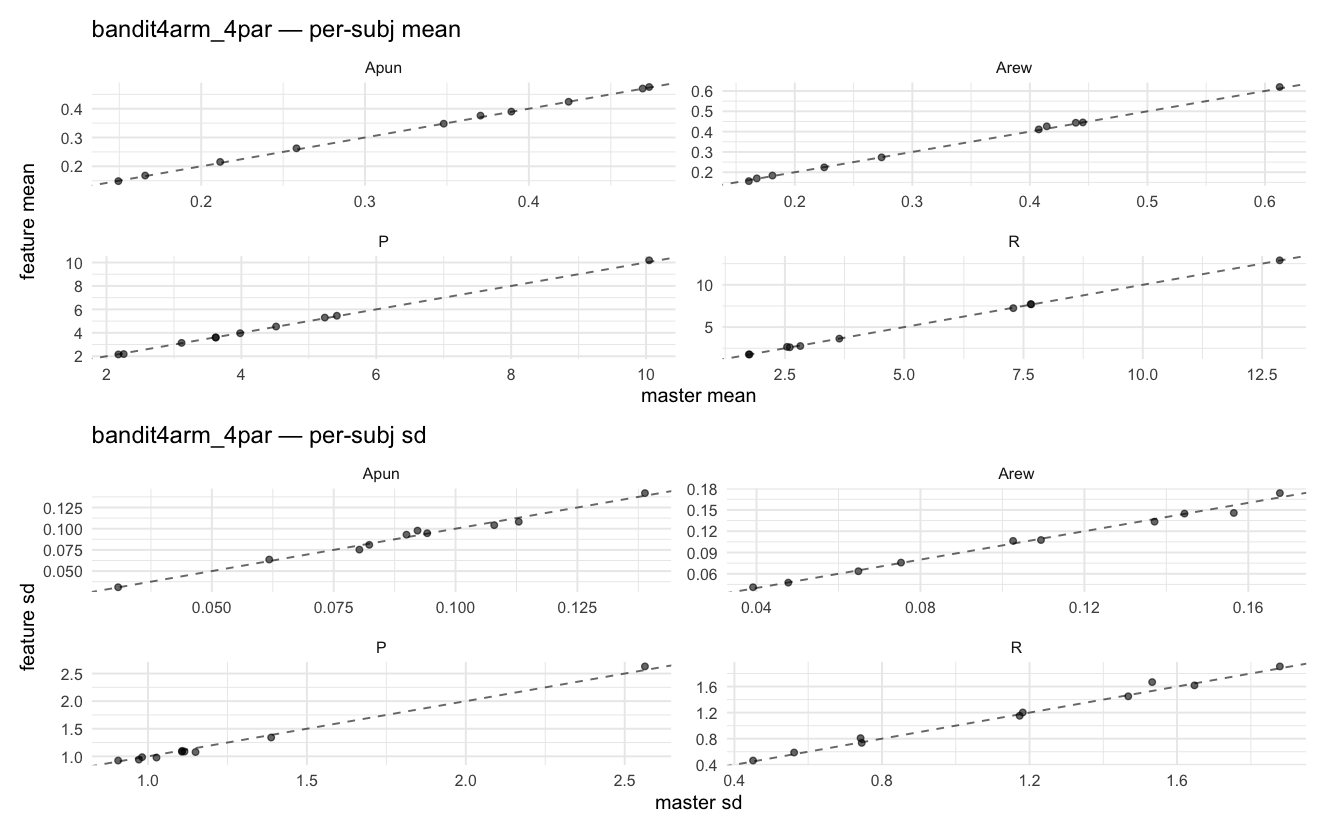
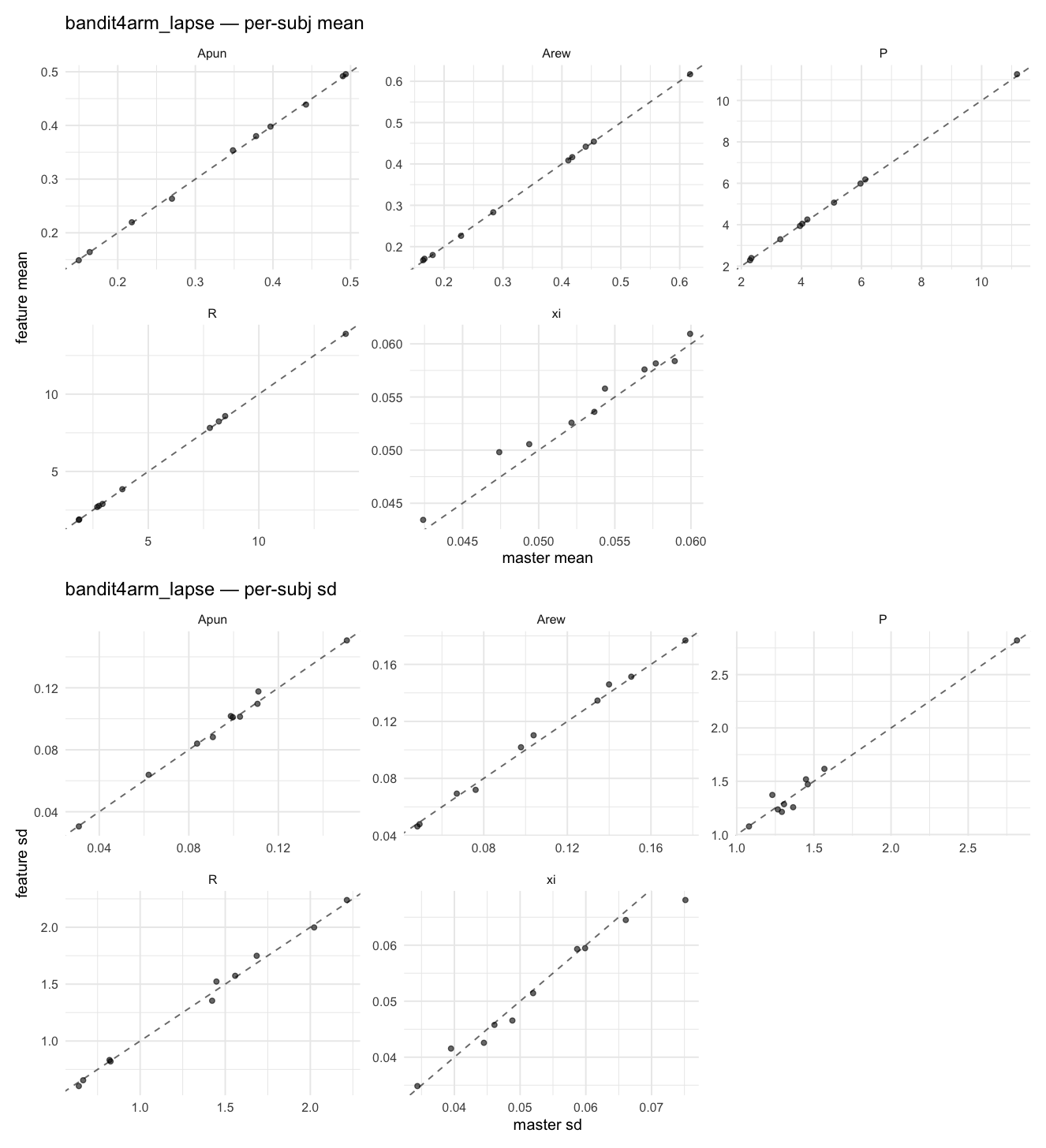
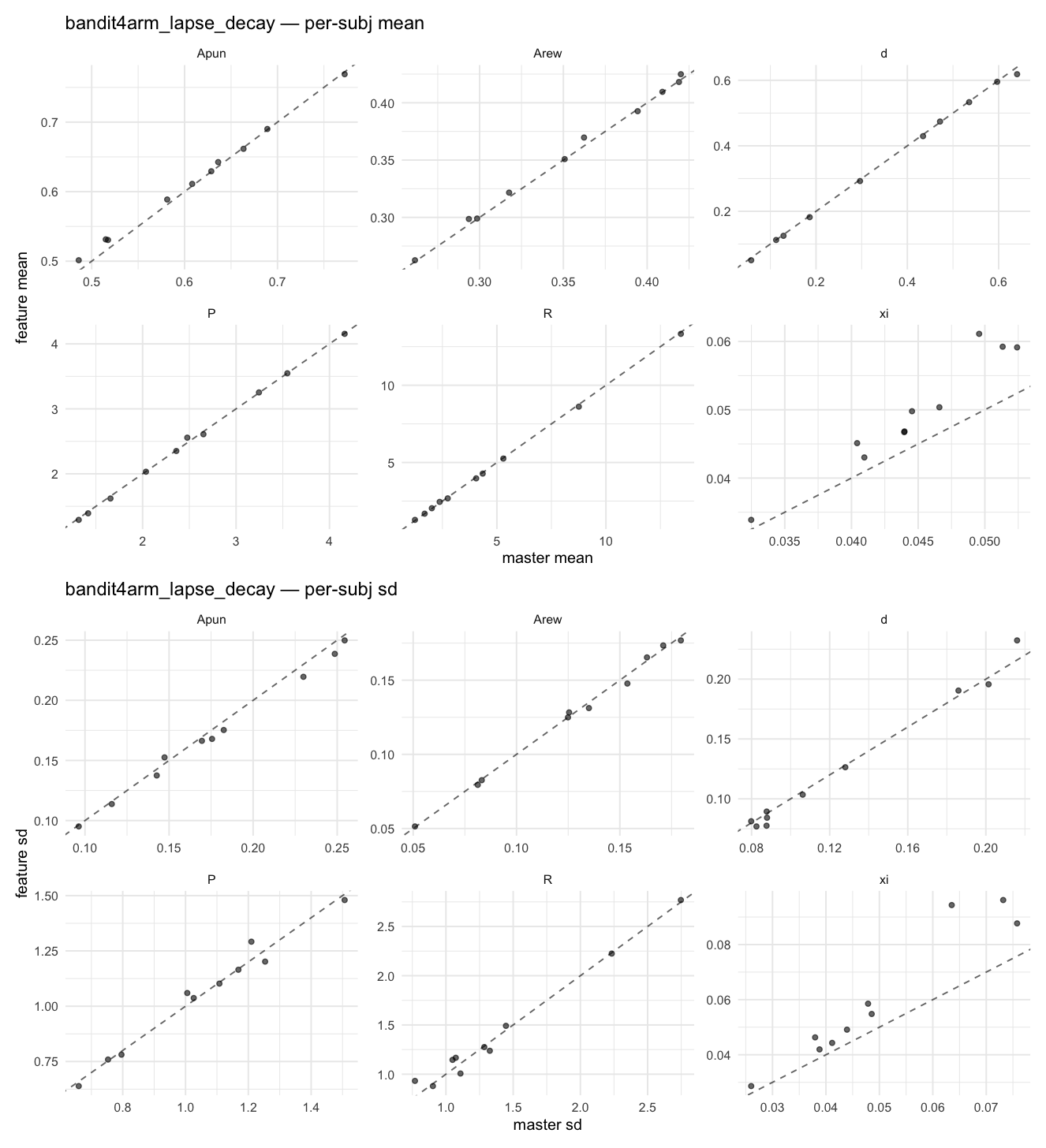
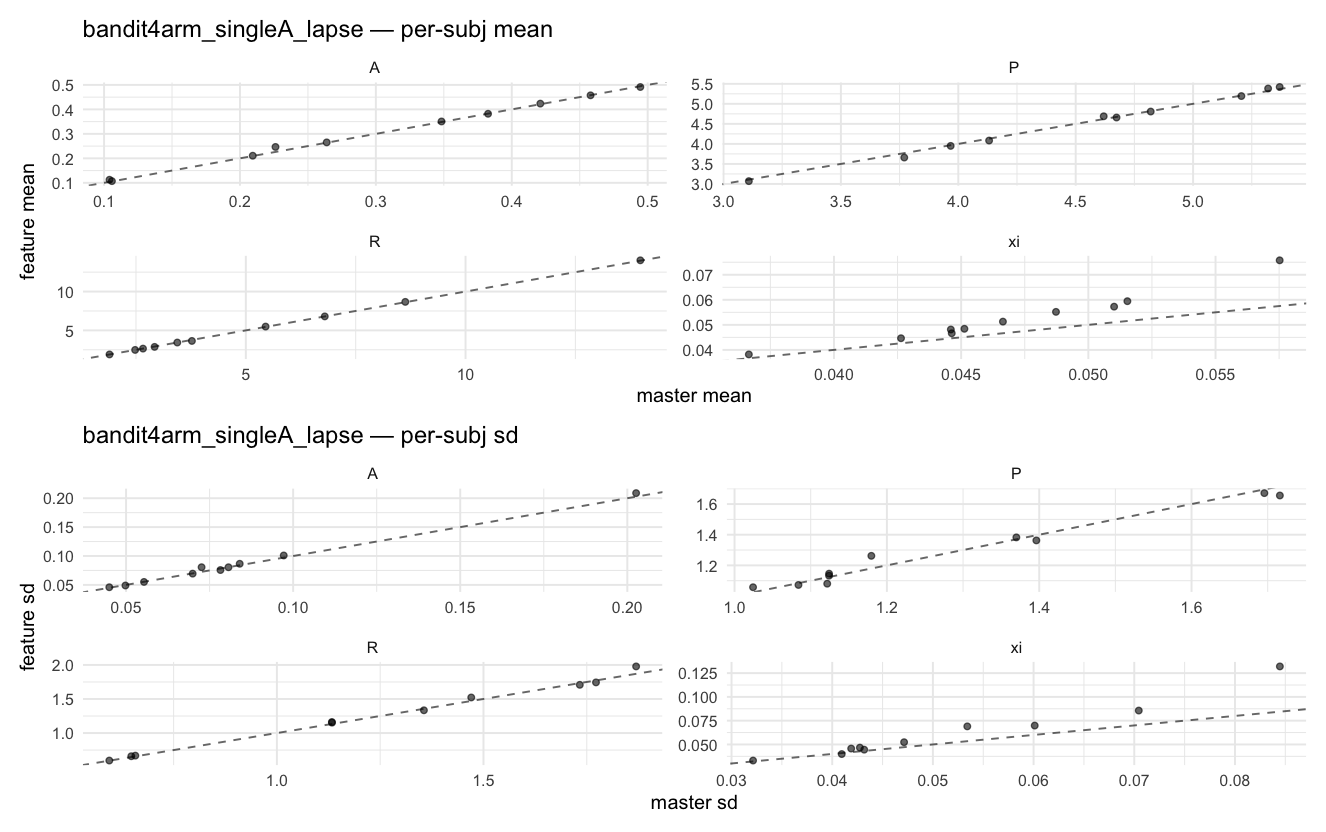
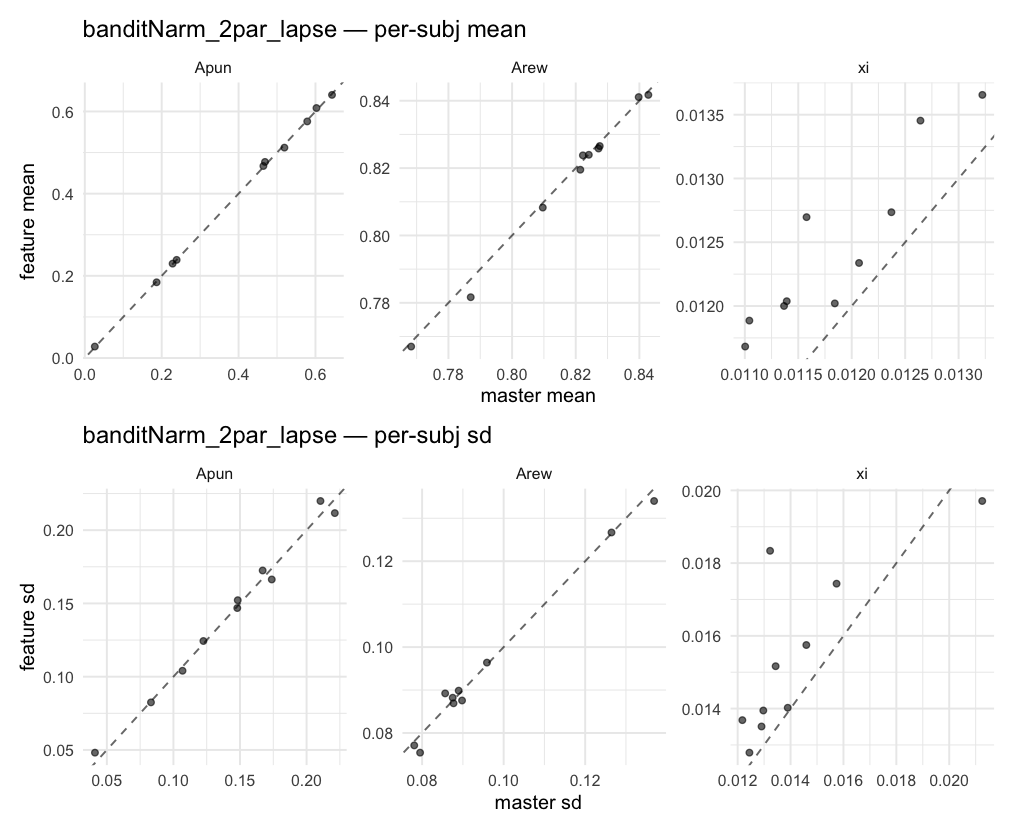
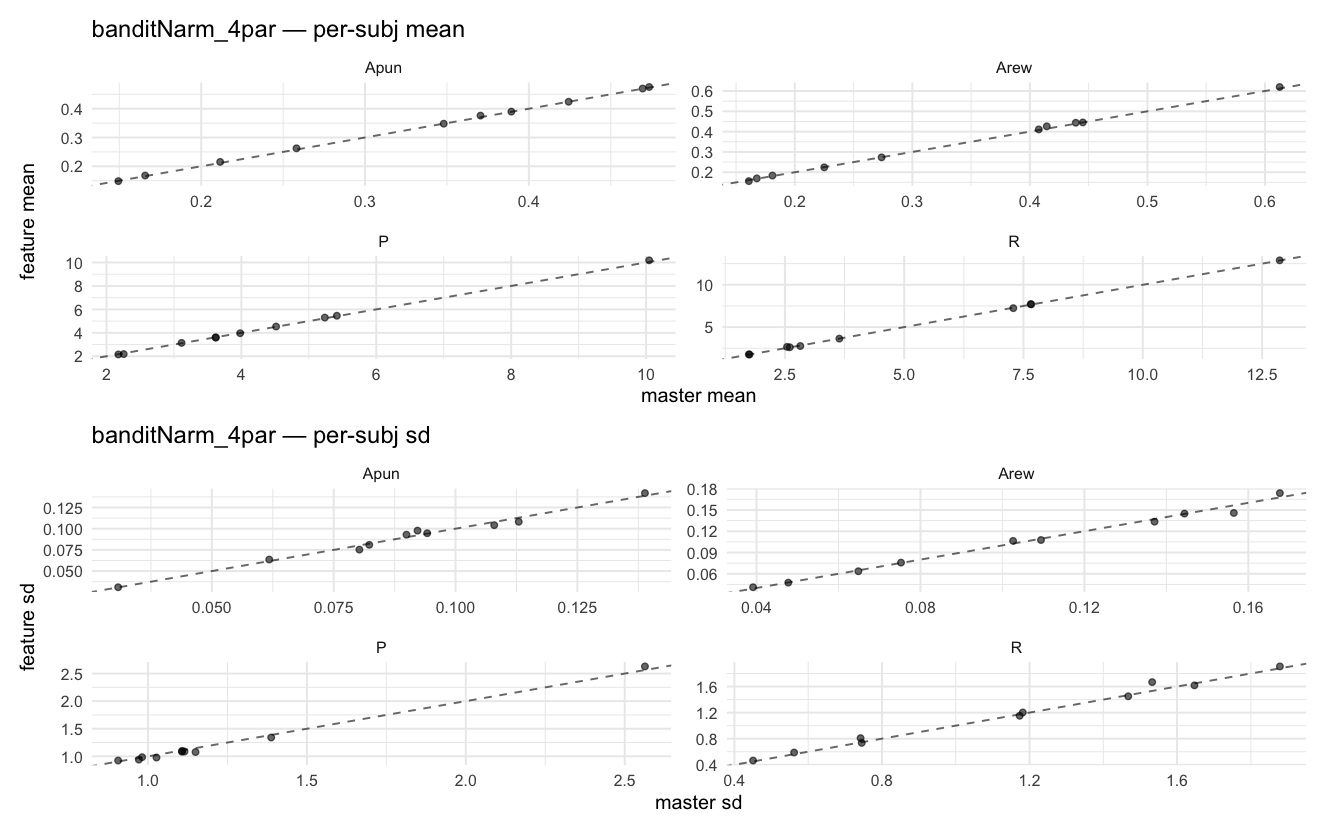
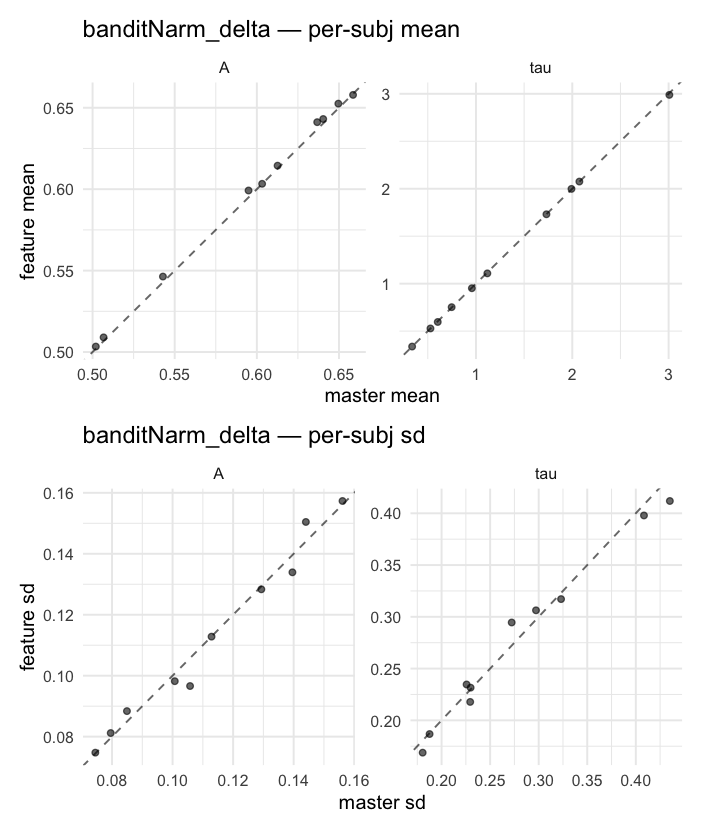
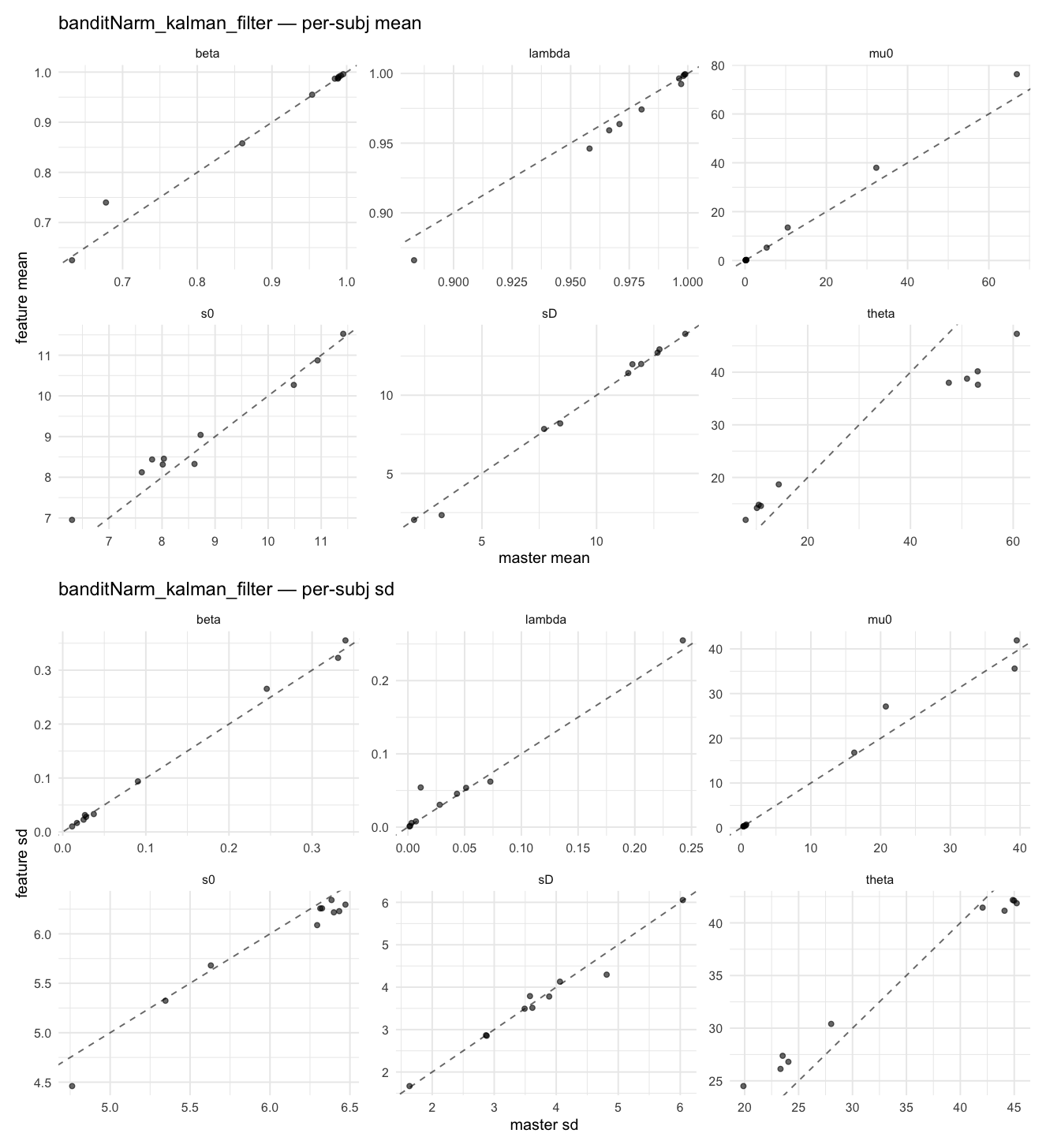
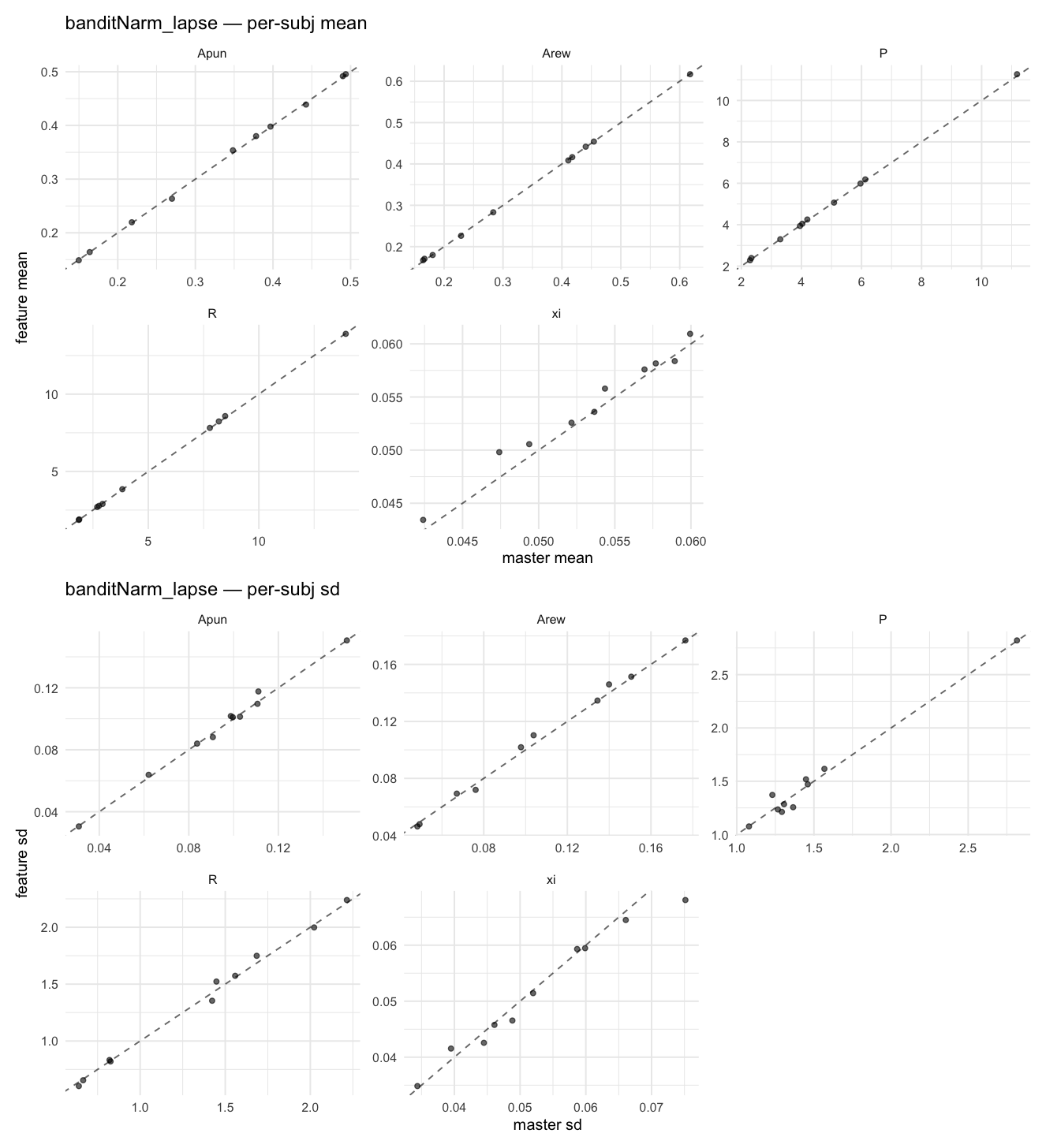
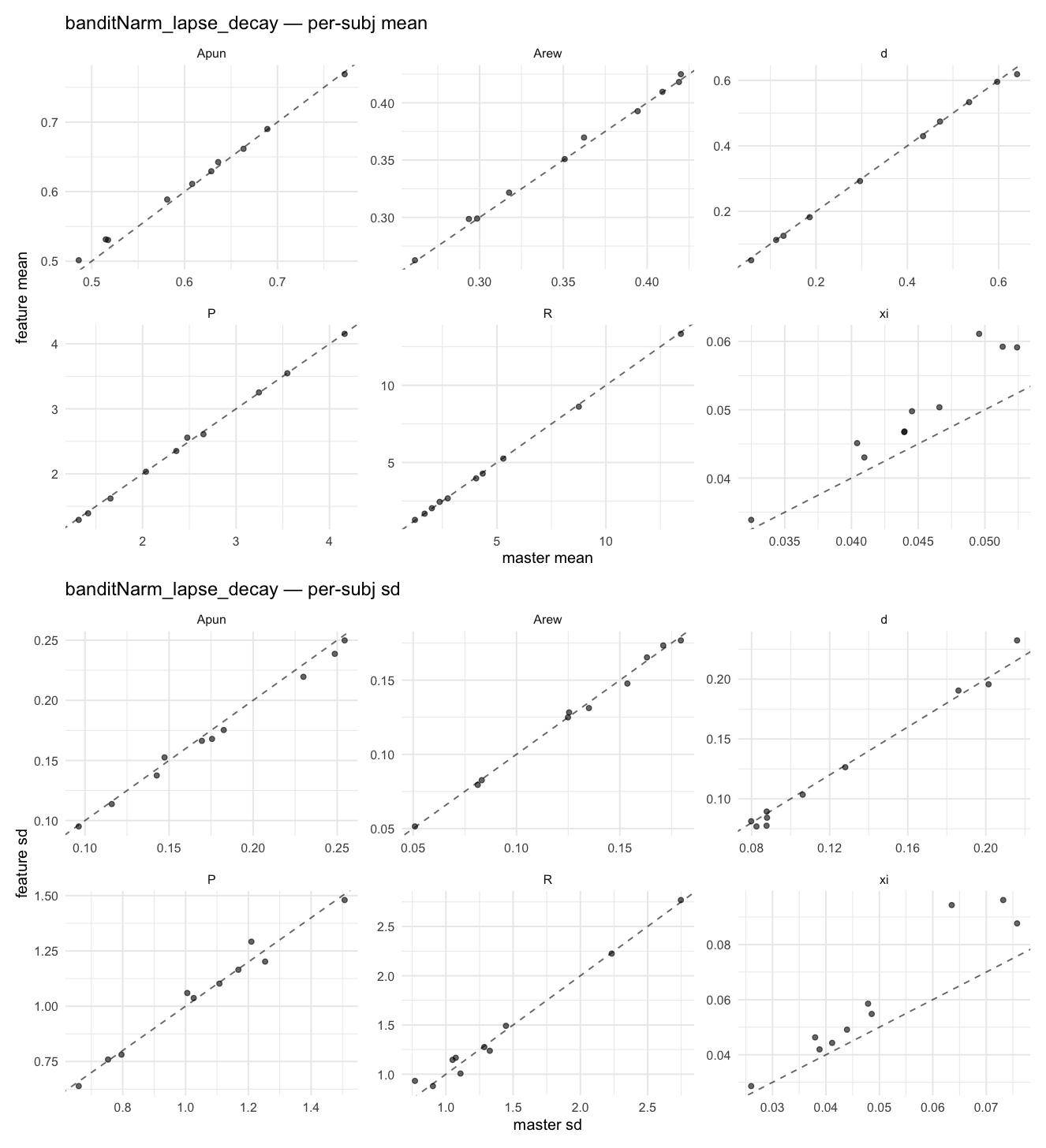
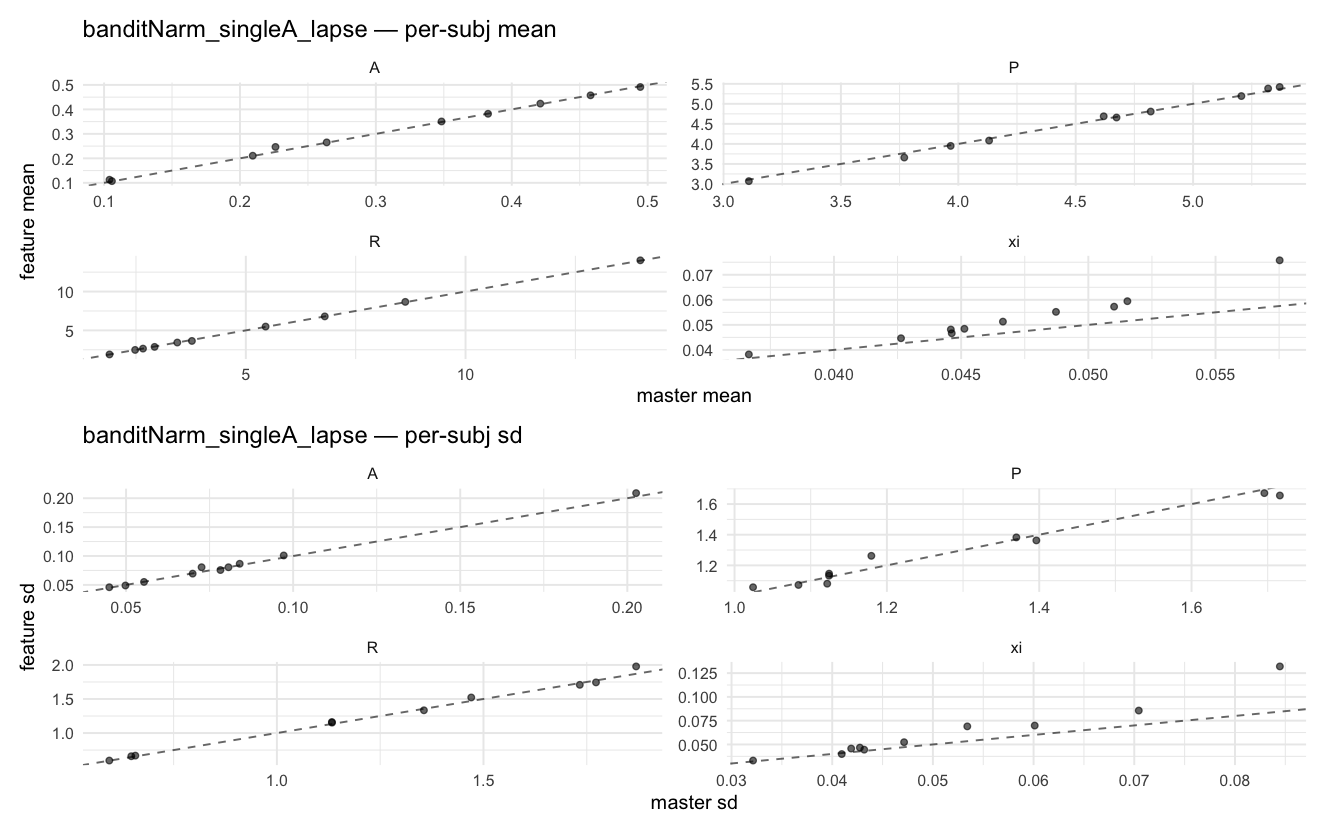
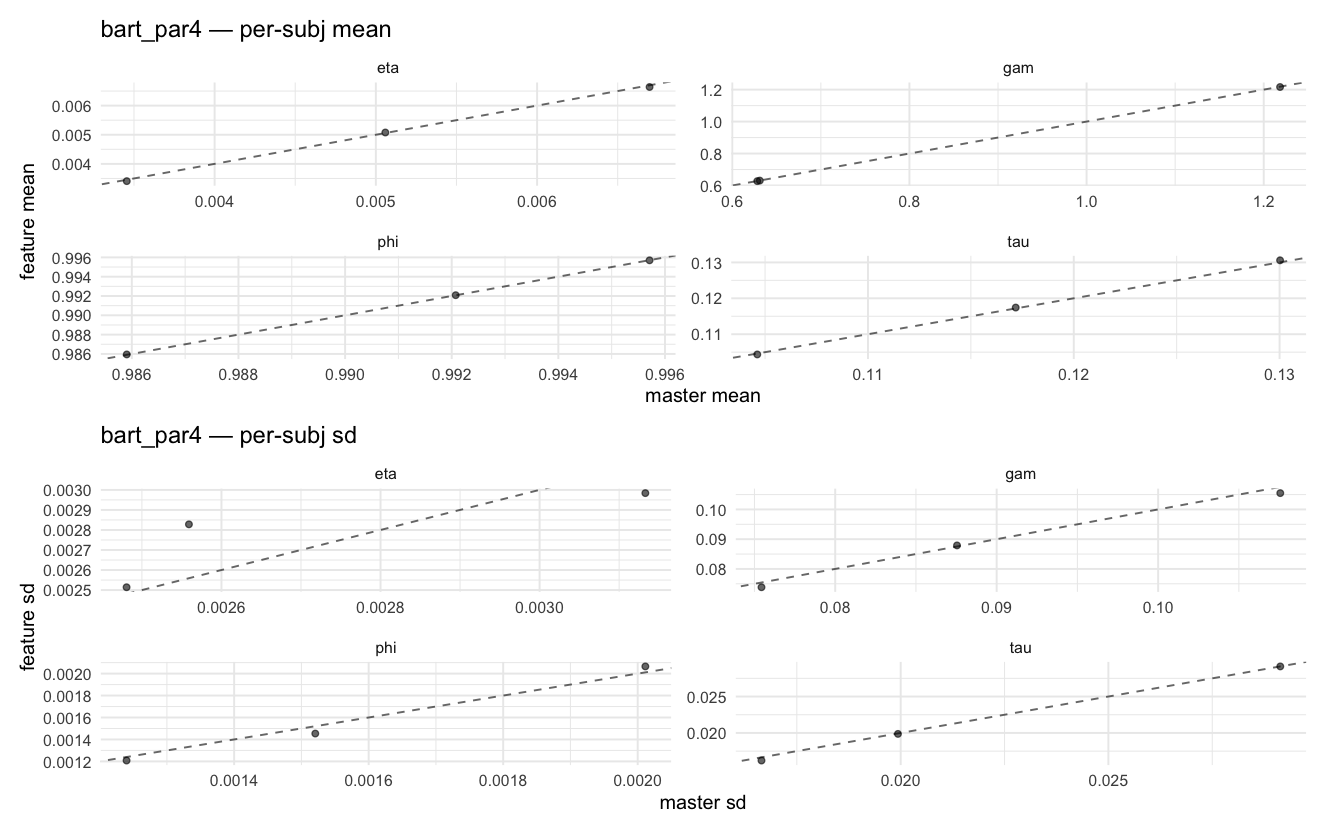
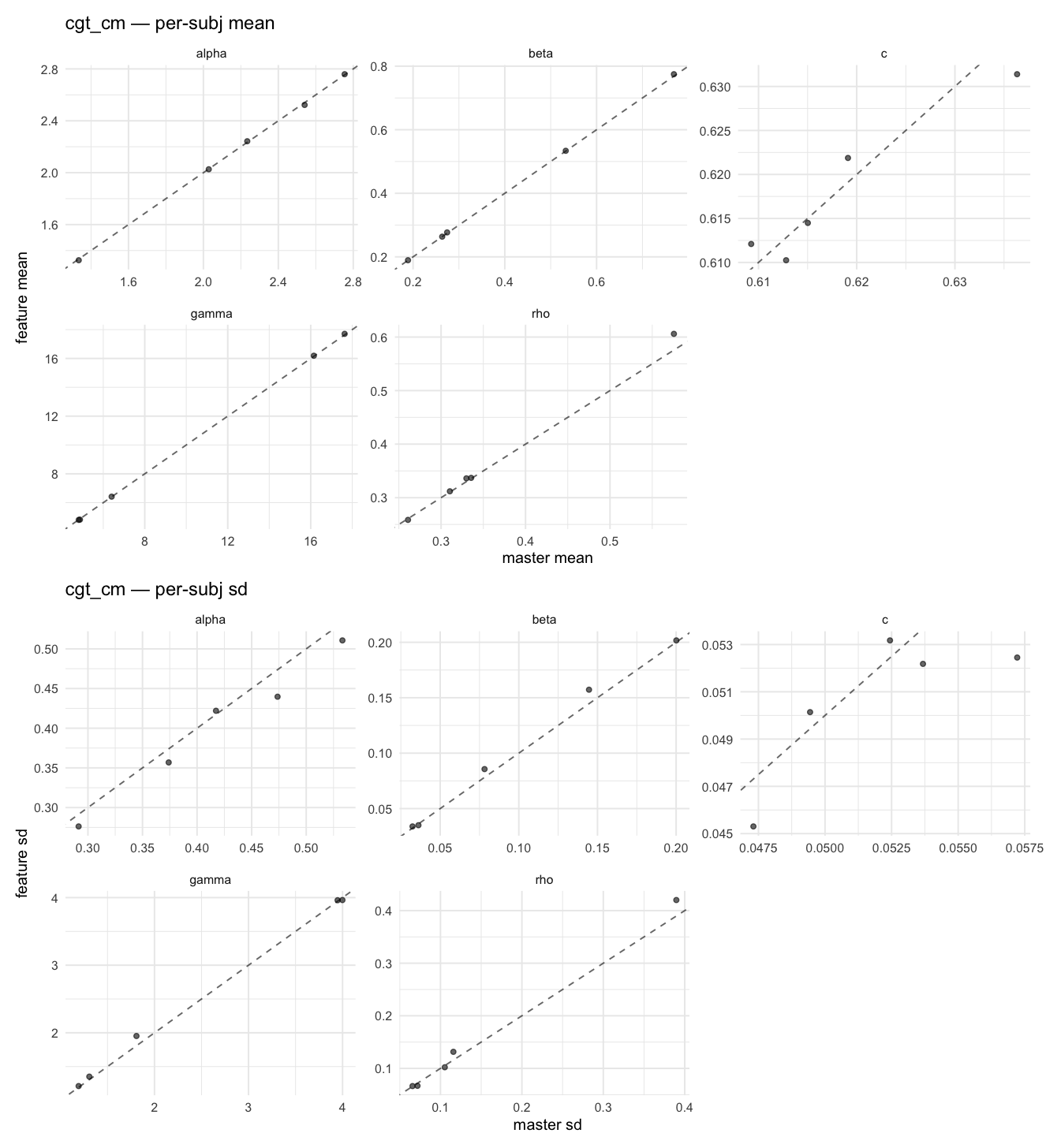
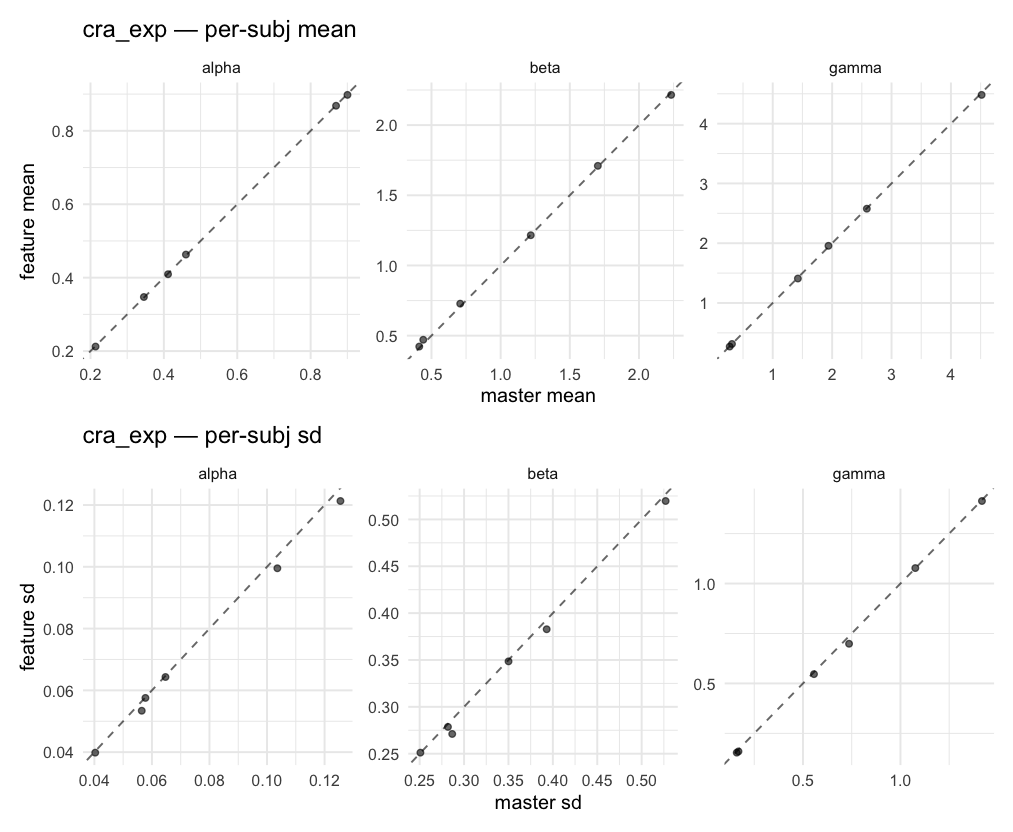
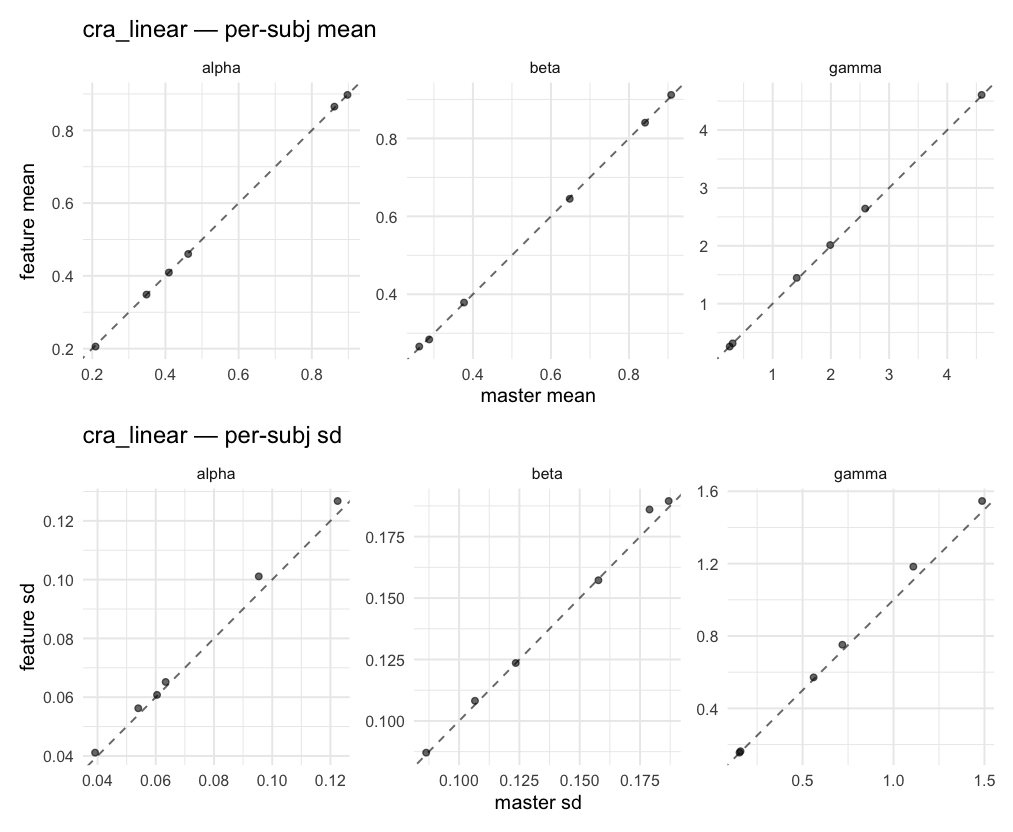
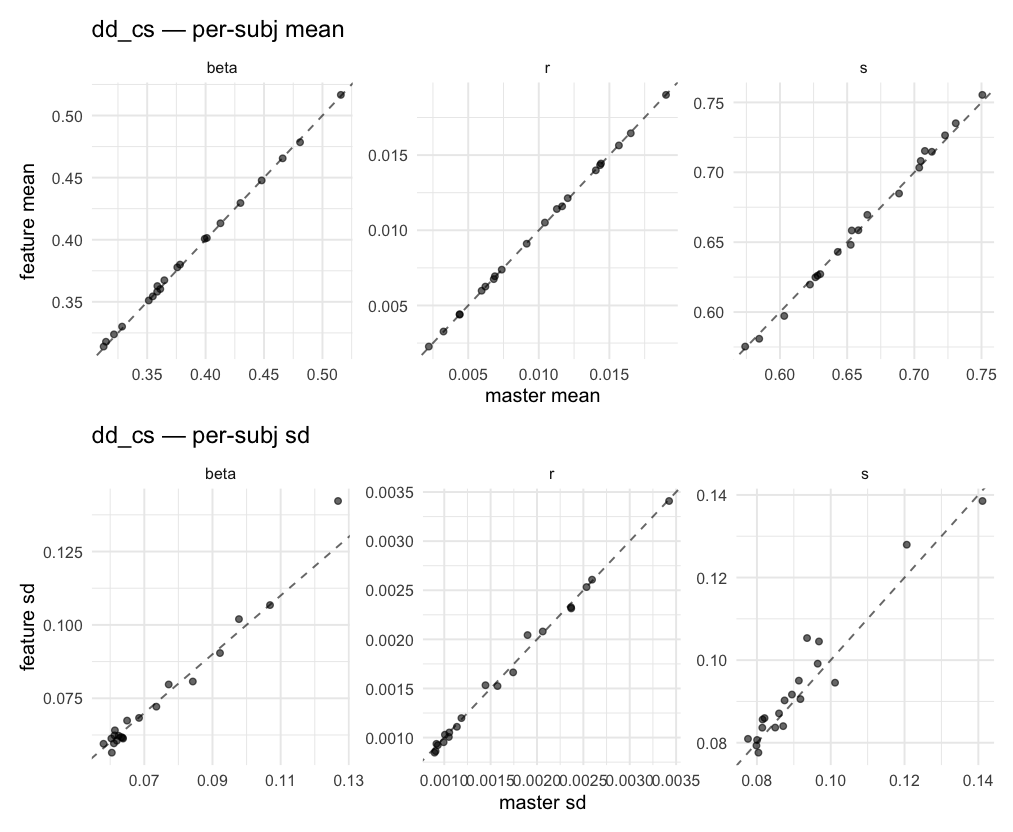
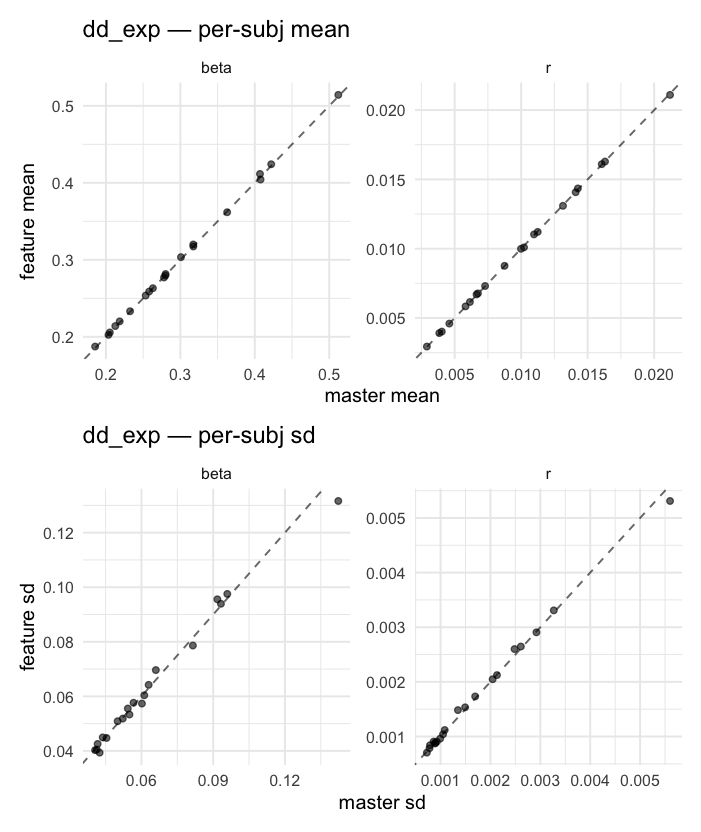
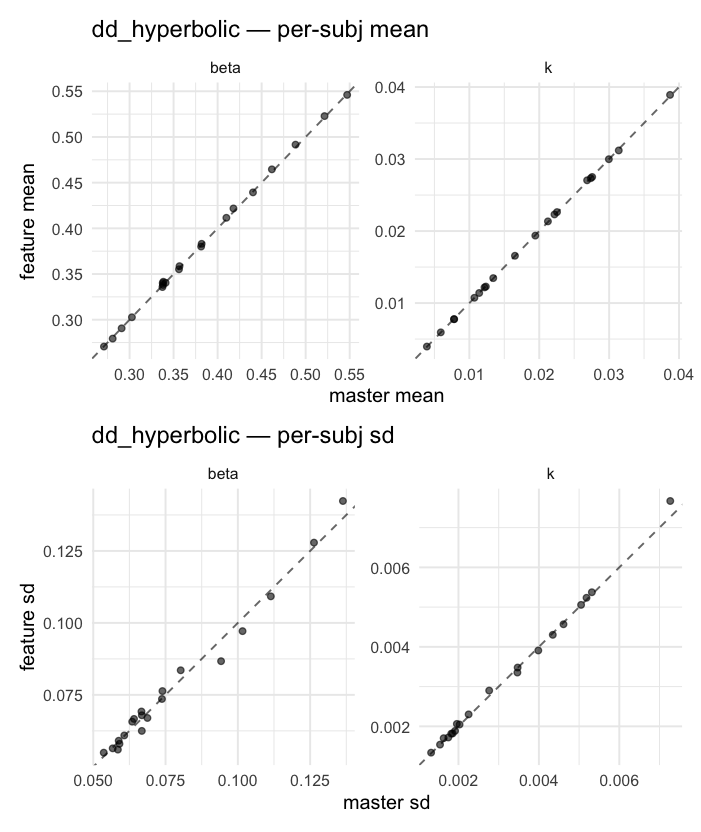
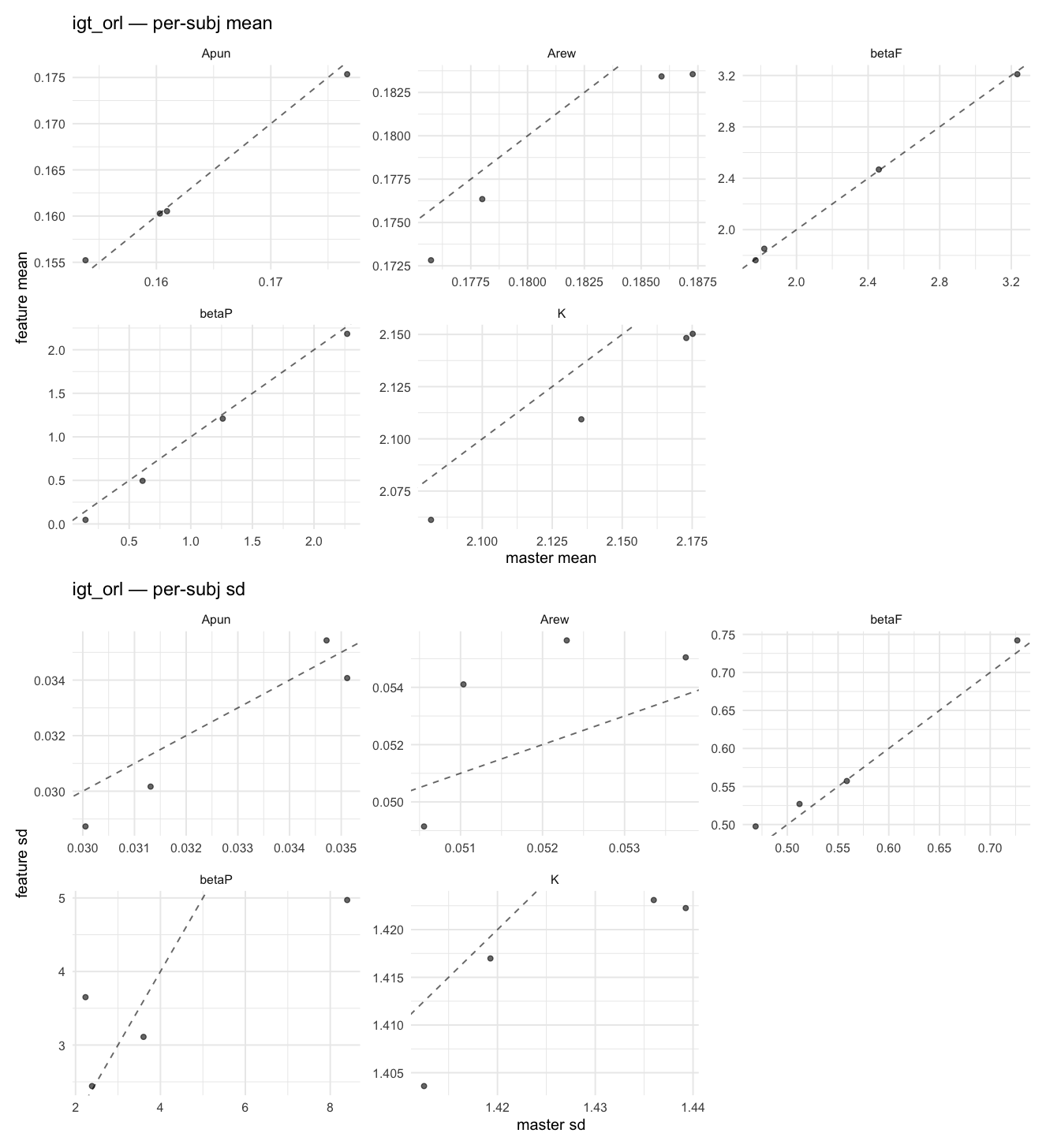
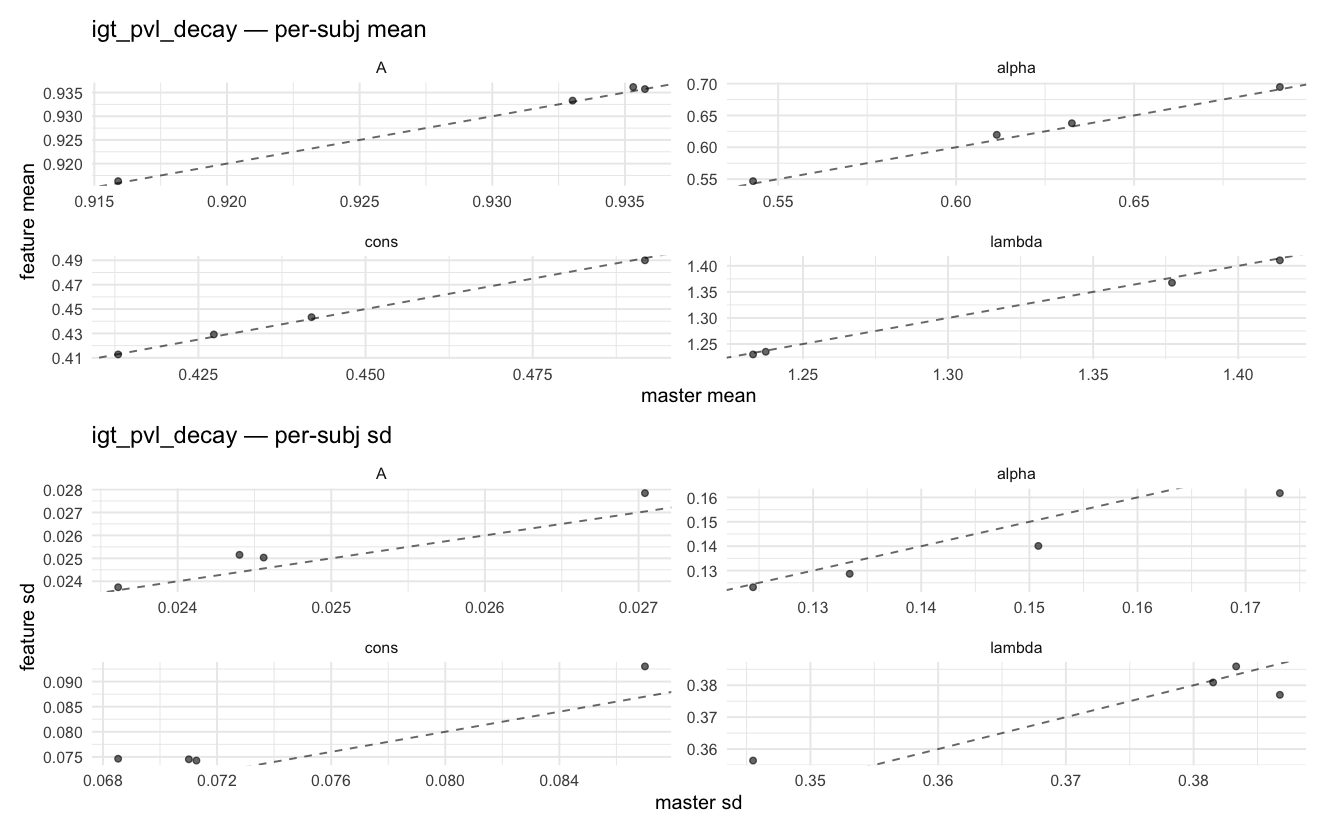
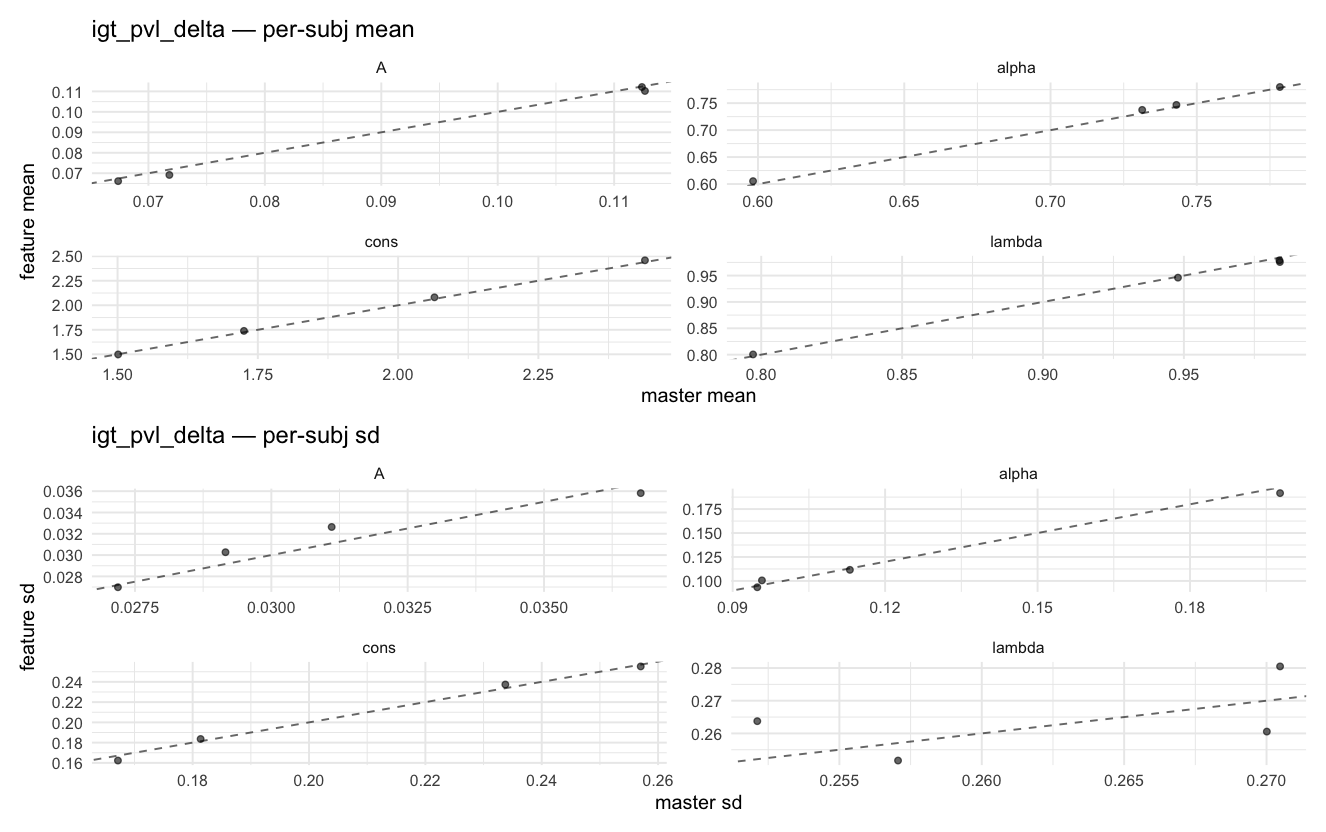
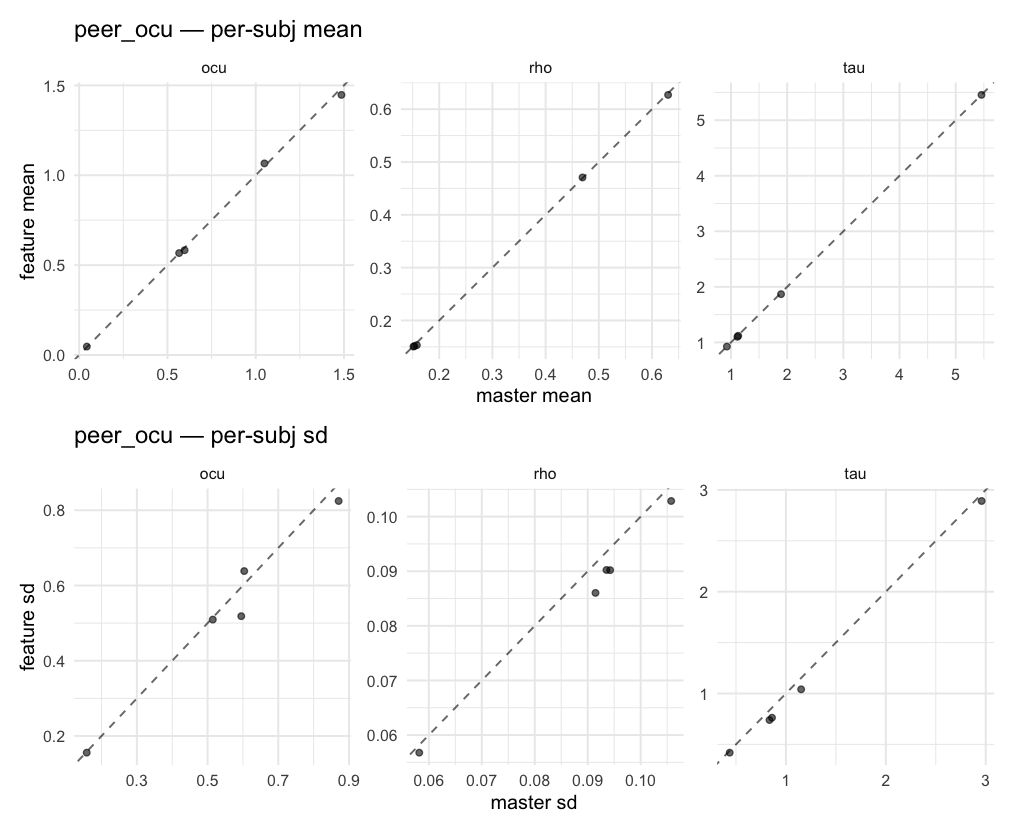
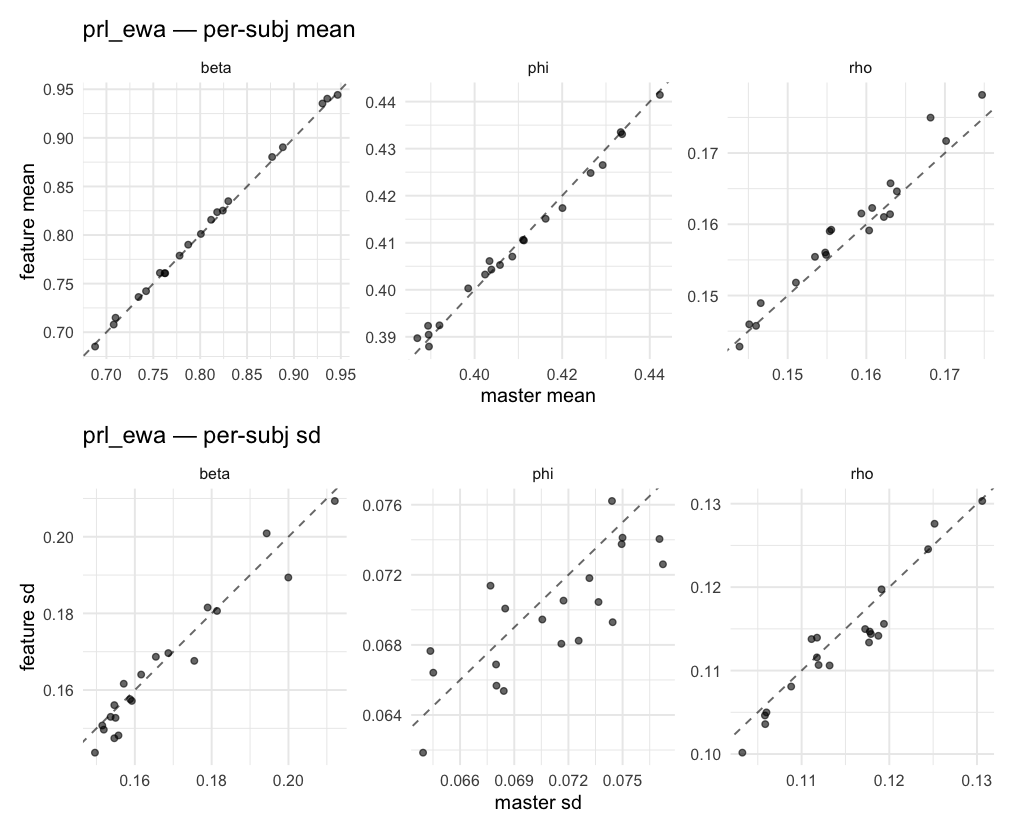
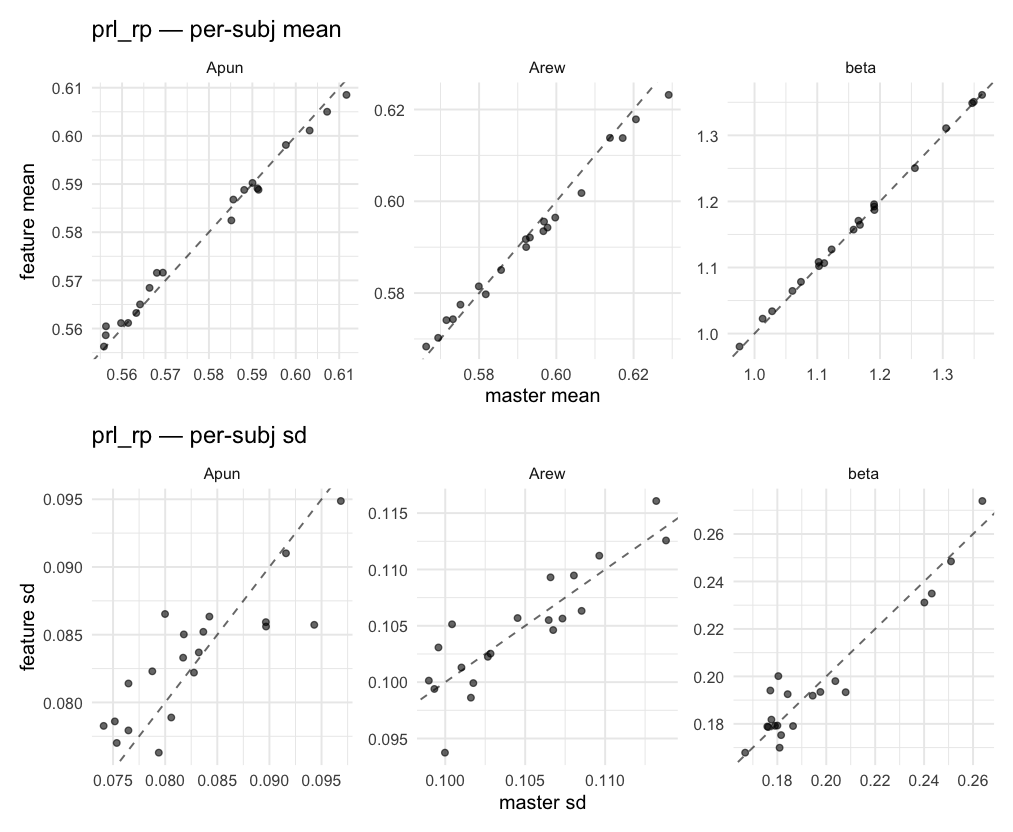
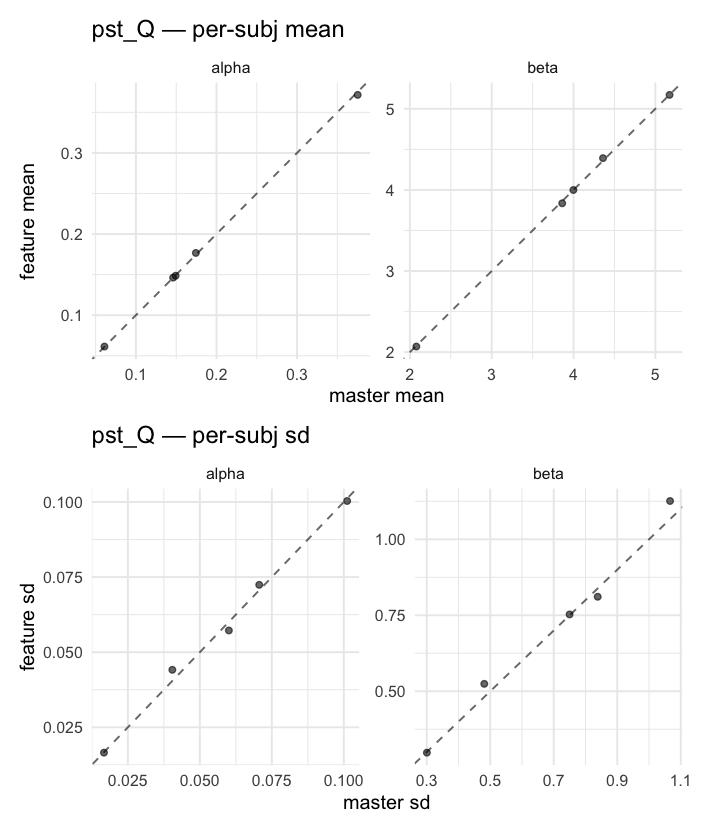
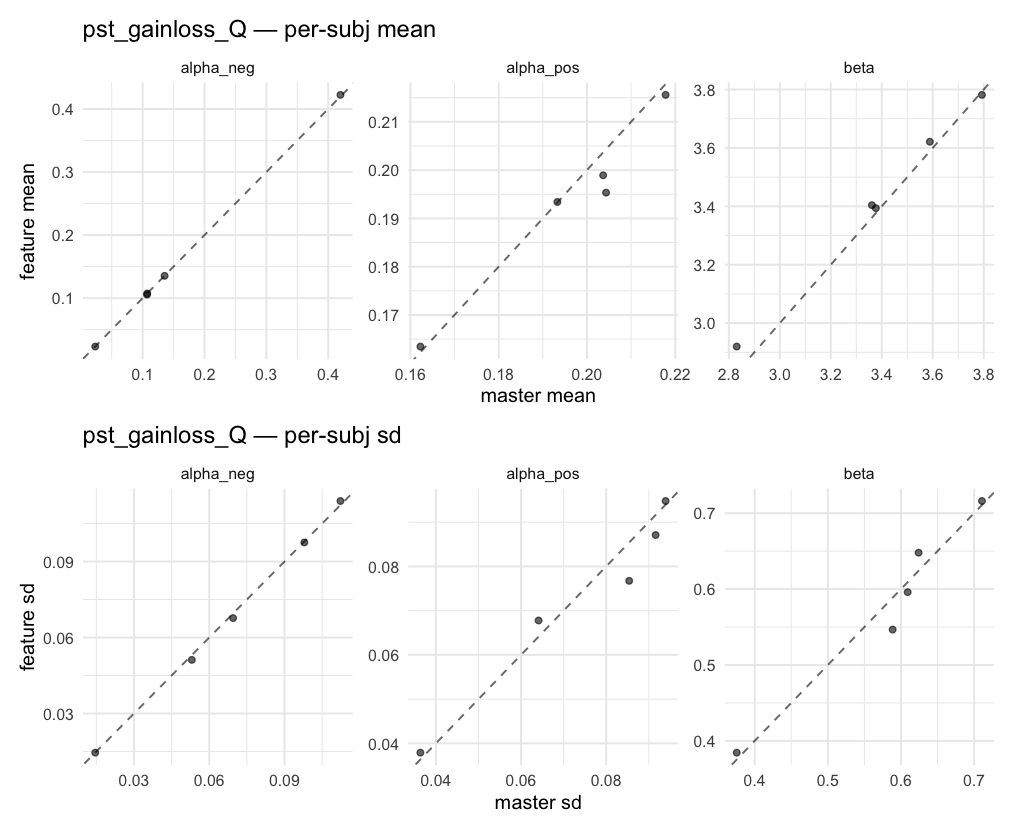
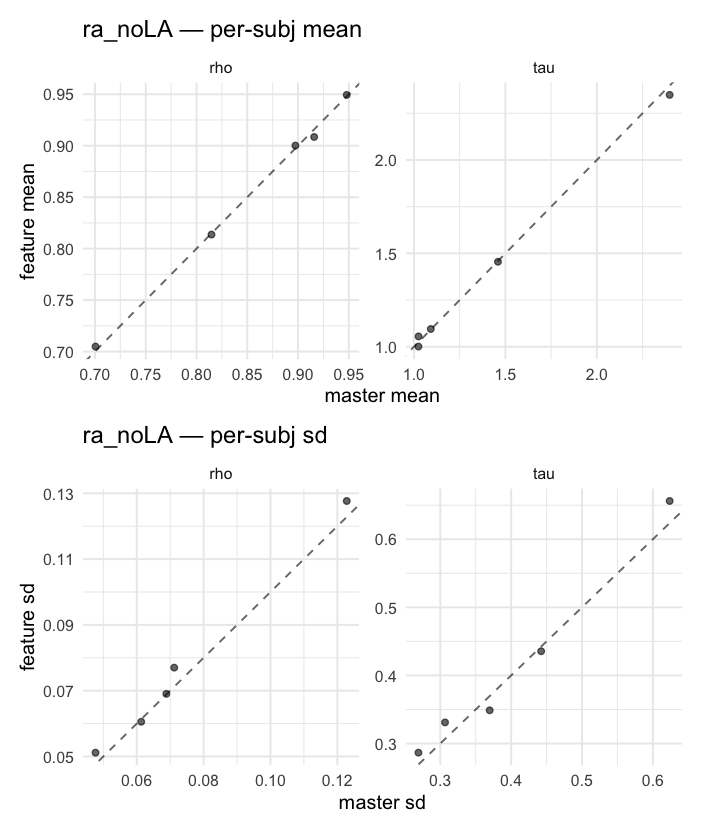
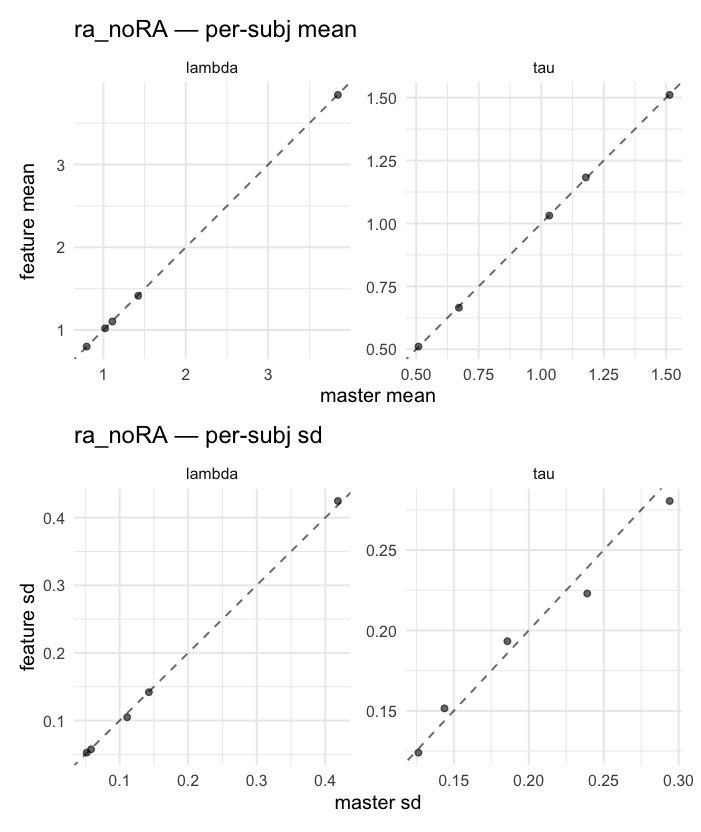
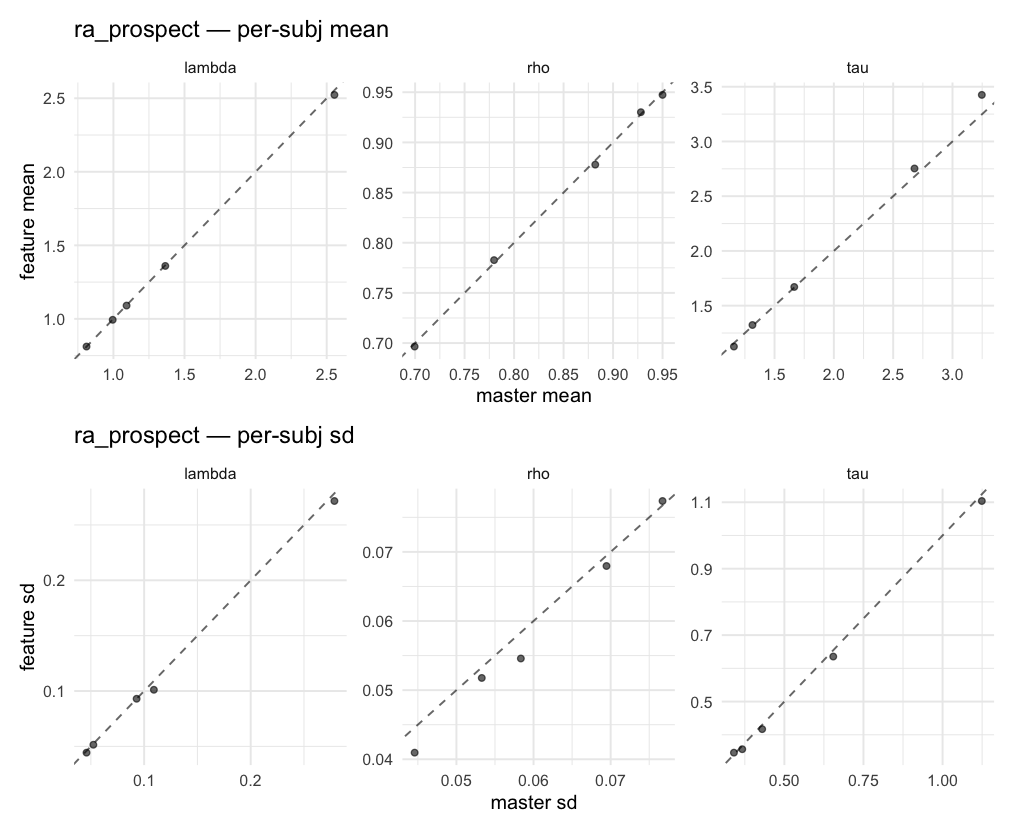
…version-2.0 # Conflicts: # Python/pyproject.toml # Python/setup.py # R/DESCRIPTION
R workflow also calls cmdstanr::check_cmdstan_toolchain(fix=TRUE) so the RTools toolchain is set up before install_cmdstan(). Python install step pinned to bash shell since the existing $CMDSTAN_VERSION expansion is bash syntax. Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
The combined "tests + codecov" step was gated to ubuntu-only because covr::codecov() needs the token. Split so non-ubuntu platforms still run the tests under testthat::test_file(); ubuntu still wraps in covr for coverage upload. Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
R workflow now has three named steps after R CMD check: 1. Install hBayesDM — R CMD INSTALL on every platform 2. Run user-facing tests — testthat::test_file on every platform 3. Upload coverage — ubuntu only, runs covr-instrumented tests Fixes Windows test failure where library(hBayesDM) couldn't find the package (it lived only inside the temp library used by R CMD check). Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
| lambda_pr ~ normal(0, 1); | ||
| ; | ||
| theta_pr ~ normal(0, 1); | ||
| ; | ||
| beta_pr ~ normal(0, 1); | ||
| ; | ||
| mu0_pr ~ normal(0, 1); | ||
| ; | ||
| s0_pr ~ normal(0, 1); | ||
| ; | ||
| sD_pr ~ normal(0, 1); | ||
| ; |
There was a problem hiding this comment.
Since we are changing the code anyway, how about fixing this part?
| lambda_pr ~ normal(0, 1); | |
| ; | |
| theta_pr ~ normal(0, 1); | |
| ; | |
| beta_pr ~ normal(0, 1); | |
| ; | |
| mu0_pr ~ normal(0, 1); | |
| ; | |
| s0_pr ~ normal(0, 1); | |
| ; | |
| sD_pr ~ normal(0, 1); | |
| ; | |
| lambda_pr ~ normal(0, 1); | |
| theta_pr ~ normal(0, 1); | |
| beta_pr ~ normal(0, 1); | |
| mu0_pr ~ normal(0, 1); | |
| s0_pr ~ normal(0, 1); | |
| sD_pr ~ normal(0, 1); |
There was a problem hiding this comment.
good catch, fixed!
| numpy>=2.1 | ||
| scipy | ||
| pandas | ||
| matplotlib | ||
| pystan | ||
| arviz | ||
| pylint | ||
| flake8 | ||
| pytest | ||
| pytest-rerunfailures | ||
| cmdstanpy>=1.2.5 | ||
| arviz>=0.20 | ||
| sphinx | ||
| sphinx-autodoc-typehints | ||
| sphinx-rtd-theme |
There was a problem hiding this comment.
Considering that dependency compatibility might break in the future, how about specifying the versions instead of just using >=?
numpy==2.1.*
scipy
pandas
matplotlib
cmdstanpy==1.2.5
arviz==0.20.*
sphinx
sphinx-autodoc-typehints
sphinx-rtd-theme
There was a problem hiding this comment.
I feel there is a trade off with python in these cases:
- pinning more strictly and it means
hbayesdmwill be harder for folks to install in their local envs (which may have strict dependencies that conflict with ours) - current setup with
>=and you risk some breaking change introduced down the line
do you guys have a preference? an alternative would be something where we try to hedge against breaking changes by giving a range—e.g., cmdstanpy>=1.2.5,<2 (but this makes an assumption about when a breaking change may occur)
There was a problem hiding this comment.
I think we should choose between cmdstanpy>=1.2.5 and cmdstanpy>=1.2.5,<2.0.
I personally think giving a range is better than setting no upper bound, but I agree with your concern.
Please choose freely.
There was a problem hiding this comment.
nice, went with caps at the next major version, which in theory should be when breaking changes are expected to hit
| "Programming Language :: Python :: 3.7", | ||
| "Programming Language :: Python :: 3.8", | ||
| "Programming Language :: Python :: 3 :: Only" | ||
| "Programming Language :: Python :: 3.13", |
There was a problem hiding this comment.
Just out of curiosity, is there a special reason you chose Python 3.13 as the minimum required version?
If you simply wanted the highest version available, maybe we can try v3.14?
There was a problem hiding this comment.
ha good q I thought about this for a bit.. honestly it was mostly a heuristic. e.g., looking at the version lifecycles, 3.13 is almost out of "bug fix" territory and into "security" territory. I figure it is likely stable enough that it won't cause issues
but happy either way! I think both would be fine
There was a problem hiding this comment.
Thank you for sharing. I didn't know about this site.
I agree with you. Let's go with 3.13.

| fit_result <- .hbayesdm_fit( | ||
| model_name = stan_model_name, | ||
| data_list = data_list, | ||
| pars = pars, | ||
| gen_init = gen_init, | ||
| vb = vb, | ||
| nchain = nchain, | ||
| niter = niter, | ||
| nwarmup = nwarmup, | ||
| nthin = nthin, | ||
| adapt_delta = adapt_delta, | ||
| stepsize = stepsize, | ||
| max_treedepth = max_treedepth, | ||
| ncore = ncore, | ||
| inc_postpred = inc_postpred, | ||
| postpreds = postpreds | ||
| ) |
There was a problem hiding this comment.
There are a few features that I've implemented in another PR that has not been merged yet. To reduce unnecessary git conflict, I think this PR should be merged first.
However, if you are interested, I want to ask your opinion about applying these changes to this PR based on this commit.
- [Feature 1] setting seed for MCMC sampling for reproducibility
- [Feature 2] setting all initial values to 0 by using
inits=0argument
(I was planning to create a PR from your feature-cmdstan-version-2.0 branch and implement them myself, but apparently the branch is in your forked repository so I couldn't do that.)
There was a problem hiding this comment.
nice both make sense to me! seed is good to have and the init=0 is often helpful IME with more complex models
I just cherry-picked your commits to bring them in 👍
| @@ -0,0 +1 @@ | |||
| R 4.4.1 No newline at end of file | |||
There was a problem hiding this comment.
Not mandatory, but I think you can consider adding trailing newline at the end of the file.
| R 4.4.1 | |
| R 4.4.1 | |
There's a small warning shown in github.

There was a problem hiding this comment.
ah oops, meant to keep this local, it is just something I use for local dev, removed
| # compiled stan objects | ||
| commons/stan_files/* | ||
| !commons/stan_files/*.stan |
There was a problem hiding this comment.
This was so needed. Thank you.
| @@ -0,0 +1,280 @@ | |||
| # Contributing to hBayesDM | |||
There was a problem hiding this comment.
I think you applied some kind of lint (code formatter) for all the previous Stan code. How about mentioning it in this page?
There was a problem hiding this comment.
ah actually I updated it using cmdstan:
for f in commons/stan_files/*.stan; do
~/.cmdstan/cmdstan-*/bin/stanc --print-canonical
--canonicalize=deprecations "$f" > "$f.new" && mv "$f.new" "$f"
done
just added a bit in DEVELOPERS.md to make this strategy clear
There was a problem hiding this comment.
TBC—above is not linting per se, but updating old to new model syntax
|
@bugoverdose @youngahn any thoughts on next steps/a plan for merging this in? Or any further tests you'd like to see? Happy to sync up over a video chat if it would be helpful first, just let me know! |
|
Let's keep the comments unresolved so that other people can easily read it and catch up easily. |
There was a problem hiding this comment.
I think this is the part @Leonardo-DongCaprio mentioned regarding the syntax issue.
Full warning message: SyntaxWarning: "\%" is an invalid escape sequence. Did you mean "\\%"?
Affected files:
- hbayesdm/models/_pst_Q.py
- hbayesdm/models/_pst_gainloss_Q.py
- hbayesdm/models/_ra_noLA.py
- hbayesdm/models/_ra_noRA.py
- hbayesdm/models/_ra_prospect.py
- hbayesdm/models/_rdt_happiness.p
- ...
This doesn't have to do with the changes in the PR, but I guess you can change it now if you want?
There was a problem hiding this comment.
so the issue here is the escape character behavior in R vs Python—added a step that corrects this on Python side and tested that the warnings no longer surface
|
I tested PR #182 locally on macOS.
The documented smoke test command: uv run pytest tests/test_ra_prospect.py -xfailed on my machine with: However, running pytest through Python directly worked: uv run python -m pytest tests/test_ra_prospect.py -xResult: So the Python uv run python -m pytest tests/test_ra_prospect.py -xI also saw six |
|
I also tested the R-side smoke test locally on macOS. Command used: Rscript -e 'testthat::test_file("tests/testthat/test_ra_prospect.R")'Result: So the R-side test file did not fail locally, but the only test was skipped because it appears to be guarded by an I also saw the following non-critical warning: Overall, the R smoke test command ran successfully, and there were no test failures. However, the actual test body was skipped due to the CRAN-skip condition. |
|
I also ran the R test with NOT_CRAN=true:
Result: |
|
I also ran an additional Python model test locally on macOS. Command: uv run python -m pytest tests/test_dd_hyperbolic.py -xResult: So, in addition to the uv run python -m pytest ... |
|
I also reviewed the updated documentation around the backend migration. The R-side documentation looks clear to me:
The R README also clearly documents the new prerequisites:
The Python README also documents the major changes clearly:
Overall, the main R/Python README and NEWS documentation seem aligned with the backend migration. The only issue I noticed so far is the quickstart smoke-test command I mentioned earlier, where |
@Leonardo-DongCaprio I was only able to re-create this error locally by uninstalling In either case, I have updated the |
@Leonardo-DongCaprio so I believe this is the behavior we want, and it is consistent with the state of the repo before my changes here. To run these you need the (also see your recent comment that tests work with the flag, nice!) |
@Leonardo-DongCaprio thanks for looking over docs in depth and for testing! I responded to other comments above, but re the quickstart issue, I realized there was some drift between the quickstart guide and the DEVELOPERS.md, so I just added the quickstart to the latter doc in an effort to minimize drift. Curious your response to this comment, as I was not able to reproduce the |
|
@bugoverdose @Leonardo-DongCaprio @youngahn so I believe I have addressed all comments, although we should nail down this before merging. I believe it may just be a local dev setup issue, but ofc if it is surfacing here then that suggests some hole in the docs. Problem is I cannot reproduce locally so it is hard for me to "fix" |
|
@Nathaniel-Haines How about merging it on 5/20(Wed)? More people in our lab could leave additional comments so I think it can be better to give just a few more days. Would that be OK for you? |
|
@bugoverdose that works for me! No rush from my side so take your time |
|
|
||
| def plot_hdi(x: np.ndarray, | ||
| credible_interval: float = 0.94, | ||
| prob: float = 0.94, |
There was a problem hiding this comment.
It's a minor thing, but is there a reason plot_hdi uses the argument name prob while plot and plot_ind use ci_prob? I think this inconsistency can be slightly confusing.
There was a problem hiding this comment.
good point @comicvalentine, I agree and think we should just standardize all to ci_prob, here is a full list of changes we would need (minus tests and docs):
Python/hbayesdm/diagnostics.py—hdi()and
plot_hdi(): renamedprob → ci_prob; also should change the default0.94 → 0.95(default is currently different between R and Python?).Python/hbayesdm/base.py—TaskModel.plot()and
TaskModel.plot_ind(): defaultci_prob 0.94 → 0.95(name is
alreadyci_prob).R/R/HDIofMCMC.R— argcredMass → ciProb; default
0.95 unchanged.R/R/plotHDI.R— argcredMass → ciProb;
default 0.95 unchanged.
but this begs a bigger question IMO—should we take this opportunity to also standardize some of the other deviations across R and Python (as well as within R)? For example, all the R functions are camelCase (as are most arg names, although some functions mix cases which is confusing), whereas Python are snake_case.
Because modern tidyverse is all snake_case, I think we would benefit from taking the 2.0 update to standardize all the R functions + args to snake_case. e.g., plotHDI → plot_hdi, etc. @youngahn @bugoverdose @Leonardo-DongCaprio any strong opinions against this? I know it would be a breaking change, but I think it is a worthwhile one to make the R and Python APIs more consistent, and to modernize the R side a bit more too. We could make these change very clear in the NEWS.md and release docs, of course
There was a problem hiding this comment.
My very personal concern would be the migration cost for existing R users, especially if many existing scripts/notebooks would need to be updated at once to get the benefits of CmdStan. As I briefly checked in the current commit, the plotting argument renames in Python (credible_interval → ci_prob / prob) seemed to be the only user-facing API changes affecting existing code, so a broader R/Python naming standardization (particularly camelCase → snake_case) feels like a much larger breaking change in comparison.
But I agree that, in the long run, the modernization and standardization would be beneficial overall — so it probably comes down to the maintainers’ preference/priorities.
There was a problem hiding this comment.
yeah it is a tough call.. my thinking is generally that if we don't make the change now, the next opportunity would be a 3.0 release (whatever and whenever that may be), and we will have the same concern at that point—so if we think it is a change worth making at some point, I think now is the time (otherwise I say we just stick with the variance)
|
Yes, it's a tough call for me, too... camelCase → snake_case is a big change, but how about make the change in 2.0? |
I think it will make us happy in the future! We will just need to be very clear about the change in the release I imagine for most users, this will only impact them on a go-forward basis. For older scripts, they will still work so long as they have library versions pinned (and if they don't... well that is partly on them) |
|
@youngahn @bugoverdose @Leonardo-DongCaprio OK I implemented the Feel free to merge this whenever! Or alternatively let me know if there are any remaining concerns I can address 🤓 |
hBayesDM 2.0 — modernize stack & toolchain
Top-to-bottom refactor of both the R and Python packages onto
current Stan tooling, plus the supporting work to keep behavior, docs, and
CI in sync.
Highlights
cmdstanpy (Python). CmdStan is now a system dependency installed once via
cmdstanr::install_cmdstan()/cmdstanpy.install_cmdstan(). No install-time precompilation; models compile on first use (~30 s) and the binary is cached.Python/pyproject.toml).array[N, T] real x,absfor
fabs) across all 66 models.DataTree,plot_dist,ci_prob, LOO-onlyextract_ic).Breaking changes
result$fit(R) /model.fit(Python) is now aCmdStanMCMC/CmdStanVBobject, notrstan::stanfit. Replacerstan::extract(fit)withposterior::as_draws_*(fit$draws())or use the already-extractedparVals/par_vals.BUILD_ALL=trueinstall-time precompile flag removed.Latent bugs fixed (no test previously)
additional_args:args[[nm]] <- NULLwas deleting entries withNULLdefaults (e.g.banditNarm_2par_lapseNarm,pstRT_ddminitQ). Switched toargs[nm] <- list(NULL)so the entry is preserved.rhat(): name collision withposterior::rhatcausedcmdstanr's$summary("rhat", ...)to recurse into hBayesDM's ownrhat. Now bindsposterior::rhatto a local symbol and passes by value.vb=True: dict inits were being passed tocmdstanpy.variational(), which only acceptsOptional[float]. Inits are now dropped on the VB branch.idata: was usingstan_variables()(variational means) and producing 1-D arrays. Now uses
stan_variables(mean=False)for the variational sample matrix.Tests
tests/test_user_facing.{py,R}— fits one small model (dd_hyperbolic) and exercises plotting (dist/trace/simple),plot_ind,rhat,extract_ic,print_fit, HDI helpers, plusgng_m1formodel_regressoranddd_hyperbolic(vb=TRUE)for the VB path.tests/test_<model>.{py,R}unchanged.Docs
R/man-roxygen/model-documentation.R—fitdescription updated toCmdStanMCMC/CmdStanVB; first-fit compile note added. All 68R/man/*.Rdregenerated via roxygen2.R/README.Rmd,Python/README.rst, top-levelREADME.md— install instructions, prerequisites, Python/R version requirements.R/NEWS.md— 2.0 entry with breaking changes and migration snippets.R/vignettes/getting_started.Rmd— full pass: install steps, fitting walkthrough, console output, post-fit object description, Section 3 plotting rewritten aroundbayesplot, Section 6 VB pointing at cmdstanr.R/vignettes/hgf_tutorial.Rmd— link fix.R/cran-comments.md— refreshed for 2.0 submission story.Python/docs/{requirements.txt,conf.py}and.readthedocs.yml— bumped to Python 3.13 + arviz ≥ 0.20.CI/CD
.travis.ymlandtravis/(xenial, Python 3.6–3.8, poetry, unmaintained). Travis ranR CMD check --no-testsand only one Python test..github/workflows/R.yaml— Ubuntu + Windows runners, R 4.4, cached CmdStan,R CMD check+test_user_facing.R, codecov upload..github/workflows/Python.yaml— Ubuntu + Windows runners, Python 3.13 via uv, cached CmdStan, ruff +test_user_facing.py+ 2 representative model smoke tests.pkgdown.yaml— pinned R 4.4, installs cmdstanr so vignettes can re-render in CI.workflows.
Repo hygiene
DEVELOPERS.mdat repo root: layout, toolchain, conventions, gotchas (additional_argsplumbing, therhatname collision, VB inits / sample matrix), and the dev loop.CONTRIBUTING.mdadded to explain how to add new model, etcTest plan
cd Python && uv run pytest tests/test_user_facing.py(15/15 pass)cd Python && uv run pytest tests/test_<model>.py(all pass)NOT_CRAN=true Rscript -e 'testthat::test_file("R/tests/testthat/test_user_facing.R")'(42/42 pass)NOT_CRAN=true Rscript -e 'testthat::test_file("R/tests/testthat/test_<model>.R")'(all pass)R CMD INSTALL --no-docs --no-test-load R(clean)roxygen2::roxygenize("R")regenerates man pages without errorsrmarkdown::render("R/vignettes/getting_started.Rmd")buildsrmarkdown::render("R/vignettes/hgf_tutorial.Rmd")builds