Study state-of-the-art papers with code 💪
| 6. | 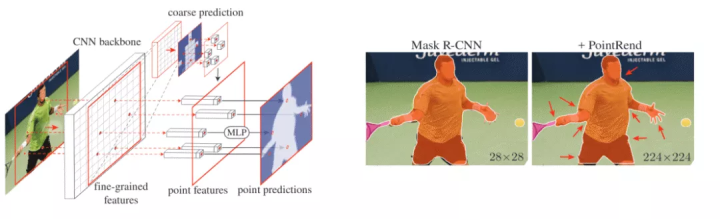
|
PointRend: Image Segmentation as Rendering
Abstract. We present a new method for efficient high-quality image segmentation of objects and scenes. By analogizing classical computer graphics methods for efficient rendering with over- and undersampling challenges faced in pixel labeling tasks, we develop a unique perspective of image segmentation as a rendering problem. From this vantage, we present the PointRend (Point-based Rendering) neural network module: a module that performs point-based segmentation predictions Click to expandat adaptively selected locations based on an iterative subdivision algorithm. PointRend can be flexibly applied to both instance and semantic segmentation tasks by building on top of existing state-of-the-art models. While many concrete implementations of the general idea are possible, we show that a simple design already achieves excellent results. Qualitatively, PointRend outputs crisp object boundaries in regions that are over-smoothed by previous methods. Quantitatively, PointRend yields significant gains on COCO and Cityscapes, for both instance and semantic segmentation. PointRend's efficiency enables output resolutions that are otherwise impractical in terms of memory or computation compared to existing approaches. |
| 5. | 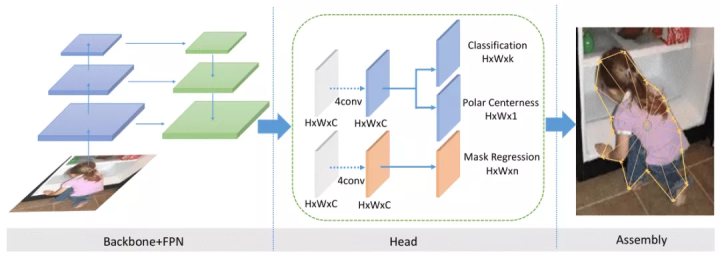
|
PolarMask: Single Shot Instance Segmentation with Polar Representation
Abstract. In this paper, we introduce an anchor-box free and single shot instance segmentation method, which is conceptually simple, fully convolutional and can be used as a mask prediction module for instance segmentation, by easily embedding it into most off-the-shelf detection methods. Our method, termed PolarMask, formulates the instance segmentation problem as instance center classification and dense distance regression in a polar coordinate. Moreover, we propose two effective approaches to deal with sampling high-quality center examples and optimization for dense distance regression, respectively, which can significantly improve the performance and simplify the training process. Click to expandWithout any bells and whistles, PolarMask achieves 32.9% in mask mAP with single-model and single-scale training/testing on challenging COCO dataset. For the first time, we demonstrate a much simpler and flexible instance segmentation framework achieving competitive accuracy. We hope that the proposed PolarMask framework can serve as a fundamental and strong baseline for single shot instance segmentation tasks. |
| 4. |  
|
End-to-end Animal Image Matting
Abstract. Extracting accurate foreground animals from natural animal images benefits many downstream applications such as film production and augmented reality. However, the various appearance and furry characteristics of animals challenge existing matting methods, which usually require extra user inputs such as trimap or scribbles. To resolve these problems, we study the distinct roles of semantics and details for image matting and decompose the task into two parallel sub-tasks: high-level semantic segmentation and low-level details matting. Specifically, we propose a novel Glance and Focus Matting network (GFM), which employs a shared encoder and two separate decoders to learn both tasks in a collaborative manner for end-to-end animal image matting. Click to expandBesides, we establish a novel Animal Matting dataset (AM-2k) containing 2,000 high-resolution natural animal images from 20 categories along with manually labeled alpha mattes. Furthermore, we investigate the domain gap issue between composite images and natural images systematically by conducting comprehensive analyses of various discrepancies between foreground and background images. We find that a carefully designed composition route RSSN that aims to reduce the discrepancies can lead to a better model with remarkable generalization ability. Comprehensive empirical studies on AM-2k demonstrate that GFM outperforms state-of-the-art methods and effectively reduces the generalization error.
|
| 3. |
GhostNet: GhostNet: More Features from Cheap Operations
Abstract. Deploying convolutional neural networks (CNNs) on embedded devices is difficult due to the limited memory and computation resources. The redundancy in feature maps is an important characteristic of those successful CNNs, but has rarely been investigated in neural architecture design. This paper proposes a novel Ghost module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. Click to expandThe proposed Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. Ghost bottlenecks are designed to stack Ghost modules, and then the lightweight GhostNet can be easily established. Experiments conducted on benchmarks demonstrate that the proposed Ghost module is an impressive alternative of convolution layers in baseline models, and our GhostNet can achieve higher recognition performance (e.g. 75.7% top-1 accuracy) than MobileNetV3 with similar computational cost on the ImageNet ILSVRC-2012 classification dataset.
|
|
| 2. |  
|
StegaStamp: Invisible Hyperlinks in Physical Photographs
Abstract. Printed and digitally displayed photos have the ability to hide imperceptible digital data that can be accessed throughinternet-connected imaging systems. Another way to think about this is physical photographs that have unique QR codes invisibly embedded within them. This paper presentsan architecture, algorithms, and a prototype implementation addressing this vision. Our key technical contribution is StegaStamp, a learned steganographic algorithm to enable robust encoding and decoding of arbitrary hyperlink bitstrings into photos in a manner that approaches perceptual invisibility. StegaStamp comprises a deep neural network that learns an encoding/decoding algorithm robust to image perturbations approximating the space of distortions resulting from real printing and photography. Click to expandWe demonstrates real-time decoding of hyperlinks in photos from in-the-wild videos that contain variation in lighting, shadows, perspective, occlusion and viewing distance. Our prototype system robustly retrieves 56 bit hyperlinks after error correction – sufficient to embed a unique code within every photo on the internet.
|
| 1. | 
|
CA-GAN: Weakly Supervised Color Aware GAN for Controllable Makeup Transfer
Abstract. While existing makeup style transfer models perform an image synthesis whose results cannot be explicitly controlled, the ability to modify makeup color continuously is a desirable property for virtual try-on applications. We propose a new formulation for the makeup style transfer task, with the objective to learn a color controllable makeup style synthesis. We introduce CA-GAN, a generative model that learns to modify the color of specific objects (e.g. lips or eyes) in the image to an arbitrary target color while preserving background. Since color labels are rare and costly to acquire, Click to expandour method leverages weakly supervised learning for conditional GANs. This enables to learn a controllable synthesis of complex objects, and only requires a weak proxy of the image attribute that we desire to modify. Finally, we present for the first time a quantitative analysis of makeup style transfer and color control performance.Keywords: Image Synthesis, GANs, Weakly Supervised Learning, Makeup Style Transfer
|