{kind=link}
{kind=link}
![]()
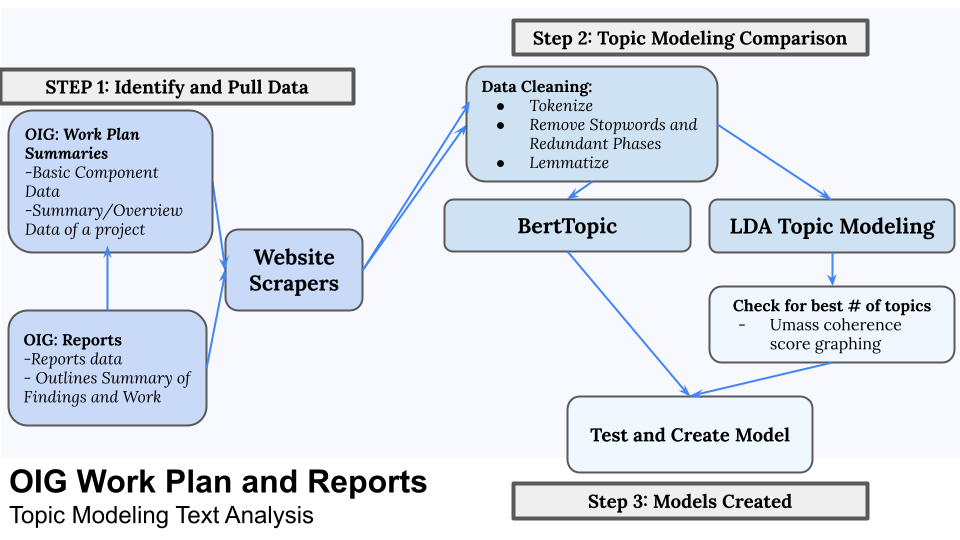
An overall picture of the project
| Initial/Final Project Proposal | https://github.com/Colsai/scott_data606/blob/main/Project_Proposal.md |
|---|
The Department of Health and Human Services- Office of Inspector General (HHS OIG) is the largest inspector general in the United States, and investigates and protects the public from bad actors in the health care sector. More specifically, HHS OIG was established in 1976, to protect the American public from fraud, waste, and abuse, with a central focus on Medicare and Medicaid programs.
Healthcare compliance officers, hospitals, and the public are interested in how HHS OIG protects them from issues. OIG's mission is to provide objective oversight to promote the economy, efficiency, effectiveness, and integrity of HHS programs, as well as the health and welfare of the people they serve. In their 2020-2025 strategic plan, OIG outline the primary focuses of their current and future work as:
- Safeguarding the Medicare Trust Funds
- Strengthening Medicaid protections against fraud, waste, and abuse
- Protecting beneficiaries from prescription drug abuse, including opioids
- Ensuring health and safety for children served by HHS programs
- Combatting cybersecurity threats within HHS and healthcare
- Promoting patient safety and accuracy of payments in home and community settings
- Leveraging technology as it intersects with HHS programs
- Ensuring HHS managed care and new healthcare models produce value
- Identifying opportunities to lower prescription drug spending for patients and programs
These priorities are of critical importance to HHS OIG- thus, a look at how actual work projects and completed work can shed light on their commitment to each of these separate focus areas.
This project aims linking these priorities to the unsupervised, NLP-based topic modeling of HHS OIG's public work that is outlined to the public, in terms of two major areas of work: work plans and reports that HHS OIG has produced from FY2018-present, found on the HHS OIG Work Plan ( https://oig.hhs.gov/reports-and-publications/workplan/index.asp).
To introduce the textual data that will be leveraged:
Work plan items are projects that HHS OIG declares to the public for addressing in their work; specifically with audits and evaluations and inspections that are performed. These items are identified, approved, posted, and work starts on their scope. Specifically, work plans are defined as, "...various projects including OIG audits and evaluations that are underway or planned to be addressed during the fiscal year and beyond by OIG's Office of Audit Services and Office of Evaluation and Inspections5"
After elements of a work plan are completed, a formal report is drafted and released to the public. HHS OIG's Reports describe the conclusions of their work on a specific topic, and include a rationale, methodology, findings, and recommendations. For the scope of this project, we will focus on the outlined Report-in-Brief (RIB) documents, hereafter referred to as a report, as these summary documents provide valuable summarizations of larger reports.
These work plan items and reports are all public data, and data has been collected on all work plan items from the audit and evaluation teams since 2017. Each of these work plans also have an attached report on the findings: some work plan items have many reports associated, and others have only one.
Bhutta describes topic modeling as an unsupervised machine learning technique for scanning documents and determining patterns for clustering by finding word and phrase patterns (https://www.analyticssteps.com/blogs/what-topic-modelling-nlp).
Because we do not assume any initial labels per each topic, we will utilize unsupervised learning techniques, defined as algorithms to discover hidden patterns or data groupings without the need for human intervention. (https://www.ibm.com/cloud/learn/unsupervised-learning)
Essentially, topic modeling is a natural language processing technique that ingests text data and returns a logical classification of topics that are frequent across each of the texts- we are using text cleaning and clustering techniques to tell us what topics appear most-frequently within a body of texts.
As the aforementioned work plan and report data we have is untagged and exploratory, we believe that topic modeling can provide significant opportunity for identifying thematic similarities and clusters so that we can extract logic and insight about the major themes of OIG's current work, in a way that would be far more difficult, and less accurate by manual tagging. We will aim to test and leverage two topic modeling algorithms: Latent Dirichlet Allocation and BERTopic (see 4. Modeling for more details on each area), for making sense of these corpuses of text data.
After generating our topic models, we will focus our model creation around 5 central questions:
- What are common themes/trends within the scope of work we can view from looking at the projects that OIG is undertaking?
- Do we (and how do we) see the influence of major health events, such as COVID, within the scope of OIG's work?
- How do we connect these plans and outcomes to OIG's priority outcomes and larger mission (see Project Focus)
- Are plans (work plans) and findings (reports) similar in terms of topics identified and scope?
- Are there any topics that appear to be underrepresented from the reports and data?
| Work Plan & Report Scraper | https://github.com/Colsai/scott_data606/blob/main/Scrapers/HHSOIG_WP_Scraper_final.ipynb |
|---|
To begin our journey into utilizing topic modeling to provide insights into public-facing text data, we are looking for the two sets of text data: work plans and reports. The data for the text and reports data were taken from the HHS OIG Work Plan, the Office of Inspector General's website that contains all of OIG's publically-declared audits, evaluations/inspections.
While all active items are available on HHS OIG Work Plan Active Table, we are looking for all items available on the work plan (publically-facing). After digging into some of the work plan's implementation, we can source this data from utilizing the HTML address patterns for previously-completed items as well as current items with the requests and bs4/beautifulsoup packages.
OIG Work Plans are a combination of several data elements- agency, expected date, component, status, title, and summary. Each work plan is essentially an outline of work scope and focus of work to be undertaken, as well as links/connections to completed reports.

Work Plan Scraping is mostly straightforward: the summaries were scraped by using a pattern in the HTML address that was identified by the way that the pages are structured. Each page is individually added in a sequential order from 0 through around ~700 (currently). One caveat is that these summaries may also not include any work plans that were removed from being public-facing; thus, the data that is scraped is a representation of only HHS OIG's public-facing data.
There were occasionally gaps between each summary page number, but this was rectified by testing counts through 750, to ensure that all pages were captured. Each of the work plan html summary pages contain an html table (which contains identifier information), and a text summary, the goal of our scraping for topic modeling. The work plan's html table is easily scraped with Pandas' inbuilt read_html function.
workplan_website = f"https://oig.hhs.gov/reports-and-publications/workplan/summary/wp-summary-{summ_num}.asp"
df = pd.read_html(workplan_website)[0]
One missing data element is most important for scraping, however- the summary text data. As the summary is within the paragraph tags in the work plan, it is found by utilizing bs4 with searching for paragraph tags, capturing the data within, concatenating it as a single string, then cleaning the html paragraph tags by replacement:
wp_summary = ''.join(str(soup.find_all('p')[3:num_para_elements])).replace("<p>", "").replace("</p>","")[1:-1]
Another important data element here are the connected reports that are contained within the Report Number(s) field. For work plans, these items also capture any connected work that was completed on the work plan. This is found in each of their 'Report Number(s)' fields, a combination of the work plan number, as well as any attributed reports. We can identify reports as:
Audits
- AUDITS/OAS: A-XX-XX-XXXXX (different from their work plan number)
- EVALUATIONS/OEI: OEI-XX-XX-XXXXX (identical to their work plan number)
and disregard:
- AUDITS/OAS: W-XX-XX-XXXXX (W-numbers are only work plans)
After the scrape of each summary page, these report numbers are added into a list, and used to generate the reports through their website addresses (See below).
For the full dataset of summaries, these were scraped into .csv format (see links at end of section).
OIG Reports are longer text files/websites. They are issued after work is completed and yields results, where OIG releases a corresponding report that is added to a work plan (in Report Number(s) field). Rports contain Summaries, findings, methodology, and recommendations, and provide a more-specific picture of the work that was accomplished. In this case, we are actually looking at Report-in-brief(RIB) documents, presented as active server pages (.asp) on HHS OIG's websites. Essentially, these RIBs are summaries of a larger report and communication log that OIG also publishes, and are more useful as they highlight only key information.

To understand the method of report scraping, all identified work plans and reports were captured using any potential report number as a possible report, then tested against the html addresses for their corresponding procuts. If the address exists, the corresponding report is scraped, otherwise it returns as an empty string (""). The identified HTML patterns per websites are as follows:
#OAS (Audits) use region number (a part of the A-number code), and the full work plan number
OAS_prod_website = f"https://oig.hhs.gov/oas/reports/region{REGION_NUMBER}/{REPORT_NUMBER}.asp"
#OEI numbers simply use the full string
OEI_prod_website = f"https://oig.hhs.gov/oei/reports/{REPORT_NUMBER}.asp"
Upon checking the report number against the website, we test whether or not that page exists. While we would expect A-numbers to always have a website, OEI- numbers may not, since the work plan and report number are shared- there is no easy way to know whether or not the report actually exists. Therefore, we test with the requests package to see whether or not the website exists before attempting to scrape it.
If it does, we use similar content identification based on the page tags. In order to prevent issues with overloading the server, we also add a one-second pause per item.
response = requests.get(OAS_prod_website)
#If the response is positive, scrape the page.
if str(response) == '<Response [200]>':
soup = BeautifulSoup(response.text, 'html.parser')
wp_item_title = str(soup.find_all('title')[0]).replace('<title>','').replace('</title>','')
wp_item_summary = str(soup.find_all('p')[5::]).replace("[","").replace("]","").replace("<p>","").replace("</p>","")
time.sleep(1)
This test and attempt at scraping is iterated across the entire set of possible report numbers, then all existing Reports are added to a pandas dataframe. Finally, the file is exported into .csv format.
Here are the total numbers of work plans/reports:

| Work Plans | https://github.com/Colsai/scott_data606/blob/main/Data_Sources/HHS_OIG_workplans.csv |
|---|---|
| Reports | https://github.com/Colsai/scott_data606/blob/main/Data_Sources/HHS_OIG_Reports.csv |
After the work plan scraping was performed, a number of text cleaning steps were performed for preparing the corpuses for both EDA and usage within the LDA model. These steps utilized much of NLTK's in-built text cleaning functionalities, such as English stopwords. The process is as follows:
- We tokenize items using Regexptokenizer, which removed punctuation within summaries, so that these tokens would not affect the model and be interpreted by the model as a token:
regex_tokenizer = RegexpTokenizer(r'\w+')
- We remove stopwords from the work plan/report text data, in order to exclude low/no-meaning words within our corpuses. This project used the base NLTK English stopwords list, but additionally included several other words ('on', 'or', etc., and domain-specific words, such as 'oig', 'hhs', as these words did not provide any helpful information for the scope of the topic modeling that followed. This was to retain only useful language for the model.
tokenized_sums = [[i for i in regex_tokenizer.tokenize(sent) if i not in stopwords]
for sent in wp_init_srs]
- We utilize a simple regex stemmer. Because of many acronyms and domain-specific words, initial tests of modeling with more-restrictive stemmers performed more poorly for topic modeling. The Regex stemmer was chosen, as attempts at more-intrusive stemmers appeared to affect the LDA model later on, and it was determined that retaining a simple model (rather than Snowball Stemmer would perform better for work plan and report topic modeling)
Reg_stemmer = RegexpStemmer("ing$|s$|ies$")
tokenized_stemmed_sums = [[Reg_stemmer.stem(word) for word in sent] for sent in tokenized_sums]
As we are looking for comparing results across the two models, the same procedures were applied to both the work plans and reports datasets. After these text cleaning steps were performed, we can move on to our Exploratory Data Analysis.
After defining the scope of our corpus as two sets of documents: OIG's work plans and reports, we can proceed with a high-level look of the texts themselves. Using Matplotlib/Seaborn, and Wordcloud packages in conjunction with Pandas, we can intuit some high-level insight into the datasets and corpuses.
- The 'Announced or Revised' column serves as the status for that item, identifying 266/659 work plans as Completed, and 70 as Completed Partial. From the current work plan website, ~280 items were identified as currently ongoing (changes per month with updates).
- A majority of work plans were specifically for Centers for Medicare and Medicaid work (415 work plans out of 655). Other major agencies that HHS OIG indicated work on included ACF, NIH, FDA, CDC, IHS, and OS. Some items were multi-agency work plans as well.
- OAS work (and therefore, audits), made up about 65% of the total work (423 work plans); OEI work (evaluations and inspections), made up the other 35%.
- As work plans can recur (and repeat year-to-year), there were duplicates. However, as language and scope of these projects can change year-to-year, duplicates were not removed to retain actual work being completed.
- Any item with that had identical report numbers was removed, as this would indicate an exact duplicate.
- Reports, connected to work plans, were not attached to every work plan. Due to the logic of the numbering system, it is difficult to tell exactly how many work plans are fully complete.
- Between audits and evaluations, the actual length of work plan texts was very similar, as shown:
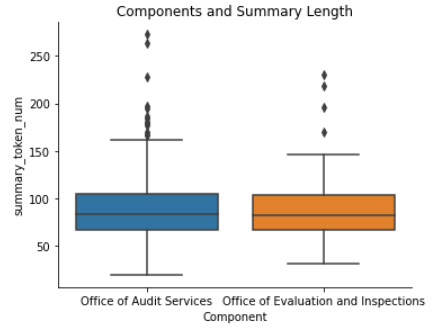
- Reports were noticeably longer (257 total tokens/avg) in textual length than work plans (88 total tokens/avg).
Overall, when looking through the tokenized work plans and reports, obvious similarities were present in the scope of analysis:
Top-100 Words, Work Plans

A quick glance at these two word clouds identifies how similar the language contained in the work plans and reports appears to be. Medicare, Medicaid, Hospital, program and Provider, obvious words that connect to OIG's CMS-heavy focus. However, there is some distinguishing language, such as reports containing language highlighting the end-stage of their work, ie filed report, publication, and reviewed.
In the next step, topic modeling, we'll utilize topic modeling to cluster around high-frequency terms.
A deeper look into the EDA performed on both datasets can be found here:
| EDA | https://github.com/Colsai/scott_data606/blob/main/data_preparation_eda/OIGworkplan_Initial_EDA.ipynb |
|---|---|
As we have defined our data, explored it, and prepared it for modeling, we can begin to use our data within the topic modeling algorithms. In this case, we use two fully-unsupervised topic model algorithms for clustering our topics.
Two unsupervised topic models were used for topic modeling the two cleaned reports: LDA and BerTopic.
The LDA model was created by David Blei, Andrew Ng, and Michael Jordan, is an unsupervised, generative model. It introduces a way to attach topical content to text documents. Each document is viewed as a mix of multiple distinct topics. In this project, we utilize the Gensim package and its LDA functions to capture the topic model for this project.
To provide some context on the BERTopic Topic Model, BERT is short for "Bidirectional Encoder Representations Using Transformers". Transformers are an attention mechanism that learns context from the relations between the words and subwords within texts (https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270).
While BERT has a number of potential uses, such as sentence predictions, named entity recognition, or question answering tasks, in this case we utilize the language model with BERTtopic. BERTopic is a topic modeling technique that leverages BERT embeddings and a class-based TF-IDF to create dense clusters allowing for easily interpretable topics whilst keeping important words in the topic descriptions (Grootendorst). A novel and recent technique, we utilize Grootendorst's extension of the BERT NLP model, created for topic modeling.
Grootendoorst writes that the BERTopic model runs through three major steps:
-
Embedding documents- Document embeddings are created through sentence transformers. For BERTopic, the model is the Huggingface tarnsformer model, specifically using:
all-MiniLM-L6-v2This sentence transformers model maps sentences and paragraphs to a 384 dimensional space, and is considered to be a performant, useful model (https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2). -
Clustering Documents: Grootendoorst's BERTopic model uses the Uniform Manifold Approximation and Projection (UMAP) dimmensinality reduction technique, a 'fast and scalable' dimensionality reduction technique to use on the dataset (https://umap-learn.readthedocs.io/en/latest/how_umap_works.html#:~:text=UMAP%20is%20an%20algorithm%20for,also%20provide%20specific%20concrete%20realizations.)
-
Creating Topic Representation: BERTopic utilizes a class-based TF-IDF model on the dimensionality-reduced data. In this case, it looks for term importance within each of the topics, to pull the most important terms and generate a topic.
The preparation steps of each model differs greatly. For LDA, text must be cleaned, prepared, and tokenized. This model is then run against a variable number of topics, chosen optimally by graphing umass coherence score against number of topics.
These LDA models use LdaMulticore, an optimized Gensim LDA modeling technique for multiple cores (None specifes all available cores). Because of the smaller size of the corpus, we modifiy the iterations/passes within the LDAMulticore function- 200 iterations across the dataset was for the iterantions parameter, chosen for better model performance, and 10 passes through.
for topic_num in range(1,30,3):
lda_model = LdaMulticore(corpus=corpus,
id2word=dictionary,
iterations=200,
num_topics=topic_num,
workers = None,
passes=10)
#LDA Model Coherence Score
cm = CoherenceModel(model=lda_model,
corpus=corpus,
coherence="u_mass")
This coherence score is added to a list of values, then displayed to the number of topics. In the case of the work plans, we chose 17 topics for our LDA topic number for workplans, as umass score appears to spike at this number, and we would expect at least 10 topics (as similar to, or higher than the number of OIG's strategic priorities).
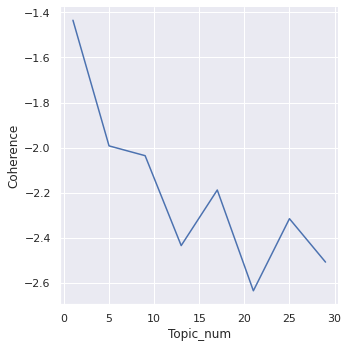
For Reports, we chose 10 topics for LDA, as a coherence score spike appeared at that topic number.
In contrast, BERTopic requires little text preparation, and we skip most text cleaning and lemmatization. Since the BERT technique relies on word context. Grootendoorst writes, "in general... you do not need to preprocess your data... keeping the original structure of the text is especially important for transformer-based models to understand the context." (MaartenGr/BERTopic#40)
However, initial attempts with the BERTopic model on the work plan and reports dataset appeared to occasionally run into issues with clear topics, as it appeared small issues with the summaries were causing issues (potentially, the html tags and special characters within the reports and work plan summaries).
Therefore, in this case, we can add a lemmatization and stopwords function through CountVectorizer to improve BERTopic from simply throwing the current corpus at the modeling.
#Lemmatizer for cleaning text
class LemmaTokenizer:
def __init__(self):
self.wnl = WordNetLemmatizer()
def __call__(self, doc):
return [self.wnl.lemmatize(t) for t in word_tokenize(doc)]
#Set docs as workplan summaries
docs = workplan_df["Summary"].reset_index(drop = True)
#Vectorizer model for adding in Stopwords and Lemmatization
vectorizer_model = CountVectorizer(ngram_range=(1, 2),
stop_words=stopwords,
tokenizer=LemmaTokenizer())
In terms of the full model, we can use get_params to show the exact parameters of the BERTopic model:
{'calculate_probabilities': False,
'diversity': None,
'embedding_model': <bertopic.backend._sentencetransformers.SentenceTransformerBackend at 0x7ff0d90f8950>,
'hdbscan_model': HDBSCAN(min_cluster_size=10, prediction_data=True),
'language': 'english',
'low_memory': False,
'min_topic_size': 10,
'n_gram_range': (1, 2),
'nr_topics': None,
'seed_topic_list': None,
'top_n_words': 10,
'umap_model': UMAP(angular_rp_forest=True, low_memory=False, metric='cosine', min_dist=0.0, n_components=5, tqdm_kwds={'bar_format': '{desc}: {percentage:3.0f}%| {bar} {n_fmt}/{total_fmt} [{elapsed}]', 'desc': 'Epochs completed', 'disable': True}),
'vectorizer_model': CountVectorizer(ngram_range=(1, 2),
stop_words=['i', 'me', 'my', 'myself', 'we', 'our', 'ours',
'ourselves', 'you', "you're", "you've", "you'll",
"you'd", 'your', 'yours', 'yourself', 'yourselves',
'he', 'him', 'his', 'himself', 'she', "she's",
'her', 'hers', 'herself', 'it', "it's", 'its',
'itself', ...],
tokenizer=<__main__.LemmaTokenizer object at 0x7ff0d9af9850>),
'verbose': False}
After running the work plan and reports data through this data preparation stage, we fit the BERTopic model to the data. After the BERTopic model finishes, several in-built packages allow us to logically analyze the results. First, we can test the topics with:
#Skip the first element [-1], as the -1 topic captures any non-topic words
bert_model.get_topic_info()[1:]
In this case, we can see that the most-common work plan topic was a medicare,payment,hospital,service... topic, which is identified in 91 work plans.

While we tested both LDA and BERTopic models, by reviewing each model, we decide to move forward with utilizing BERTopic's insights over LDA, primarily because the topics generated by the BERTopic model are far more comparable (18 work plan topics/19 report topics), over LDA's (13/10). Manual review of topics generated by BERTopic additionally show BERTopic's proposed topics to appear to be unique per topic, as well.
A full picture of the work and code can be seen here:
Of additional note is that, in the final section, we analyze two saved BERTopic models. Saved topic models were used for the work plan and report data, as multiple run-throughs of unsupervised models can create different clusters.
Thus, the saved models are applied to the final analysis- it is possible that these insights may vary slightly, model-to-model, as applied across different iterations of the model themselves.
| Analysis/Models Folder | [Saved Models: Github Folder](https://github.com/Colsai/scott_data606/tree/main/Saved_Models) |
|---|---|
Within this project, we performed an end-to-end project for scraping a novel dataset of public work products in order to analyze the larger work scope of a major US government oversight agency to generate two topic models for the reports and work plans. Through that work, we have created two topic models using BERTopic on OIG's work plans and reports. By taking a look at the insights that were created by the model, let's finally re-apply the identified topics to the initial questions:
- What are common themes/trends within the scope of work we can view from looking at the projects that OIG is undertaking?
Medicare, Medicaid, protection for children, and opioid work were significant themes from the projects. Most priorities were represented significantly, though see questions 3-5 for more insight.
- Do we (and how do we) see the influence of major health events, such as COVID, within the scope of OIG's work?
Yes, we did. COVID-19 was a significant priority that was not a specific strategic priority, but was identified in several of the work plan topics that HHS OIG has produced. Similarly, nursing home oversight (more specific than simply 'group homes') was a topic identified by the models. Closer examinations with the models show several additional topics as not within the scope of HHS OIG's priorities, but of focus- general audits, IHS work, etc.
- Are plans (work plans) and findings (reports) similar in terms of topics identified and scope?
Yes, medicare, medicaid, opioids, and drug rebates were all major focuses in work plans and their reports, and most topics had equivalents between work plans and reports (see .csv).However, there were some differences:
- The financial audit topic may have been too general, but did not have any obvious match to a reports topic.
- Work plans included a distinct topic on information and cybersecurity that was not captured in the scope of the reports.
- How closely do the topics of work identified in the models connect to the priorities outlined by HHS OIG?
The topic connected well overall. The first four priorities were represented highly for both work plans and reports.Additionally, the BERTopic model identified Covid, IHS, and Nursing Homes as other categories of priorities for HHS OIG. However, priorities five (cybersecurity), and 7 (leveraging technology) were not identified frequently within the topic modeling, suggesting more future focus to align with the strategic priorities.
- Are there any topics that appear to be underrepresented from the reports and data?
Cybersecurity and technology work did not seem to factor strongly into either the current work plans or reports that BerTopic identified. This indicates that OIG should consider greater investment into those fields in terms of future projects and current focus of work, should they place high emphasis on this strategic priority.
Interestingly, one topic that was missed was IHS (Indian Health Service work. While not a specific priority, it was obvious from the scope of the topics that IHS oversight was an important area of work for OIG, and may be considered for elevation into stategic priorities, should this emphasis continue.
Another missing topic was the significance of focus on nursing homes. HHS OIG outlines their prioritization of nursing homes on their website, but may be a consideration for outlining a future priority with specific regards to that work. This also aligns with the larger federal goal of protection on nursing homes, seniors, and people with disabilities (https://www.whitehouse.gov/briefing-room/statements-releases/2022/02/28/fact-sheet-protecting-seniors-and-people-with-disabilities-by-improving-safety-and-quality-of-care-in-the-nations-nursing-homes/).
COVID-19 oversight was also not outlined as a specific priority in the strategic plan, although it was an obvious scope of work, heavily into the work that OIG is committing to. Further research revealed that COVID was designated as another priority area with specific asks (https://oig.hhs.gov/coronavirus/). However, it did not appear as significantly in OIG’s reports- indicating a likelihood in ongoing work for the future, which makes sense due to the relative recency of the pandemic and its impact.
While we were able to create and analyze the initial topic models for the two datasets, we did not push the current model into a web-based environment. Thus, our next steps would be to consider an environment to produce the models in, so that stakeholders could better-analyze this data.
Additionally, there appears to be broad application for topic modeling within the public sector, with many large text documents often difficult to classify, distill, and understand. As shown, topic modeling can be an effective strategy for comprehension, logical organization, and better characterization of project and report data in other spaces, as well. From this project and its initial findings, we are excited about the possibilities that topic modeling could lead to.
Budget Basics: Medicare. https://www.pgpf.org/budget-basics/medicare. Accessed 12 June 2022.
February 2022 Medicaid & CHIP Enrollment Data Highlights | Medicaid. https://www.medicaid.gov/medicaid/program-information/medicaid-and-chip-enrollment-data/report-highlights/index.html. Accessed 12 June 2022.
“Medicare Program Is the United State’s Single Largest Health Program.” Health Management Associates, https://www.healthmanagement.com/services/government-programs-uninsured/medicare-program/. Accessed 12 June 2022.
“What You Need to Know About OIG Audits.” Journal of AHIMA, https://journal.ahima.org/page/what-you-need-to-know-about-oig-audits. Accessed 8 June 2022.
Work Plan | Office of Inspector General | U.S. Department of Health and Human Services. https://oig.hhs.gov/reports-and-publications/workplan/index.asp. Accessed 8 June 2022.
Kapadia, Shashank. “Topic Modeling in Python: Latent Dirichlet Allocation (LDA).” Medium, 29 Dec. 2020, https://towardsdatascience.com/end-to-end-topic-modeling-in-python-latent-dirichlet-allocation-lda-35ce4ed6b3e0.
Kelechava, Marc. “Using LDA Topic Models as a Classification Model Input.” Medium, 6 Aug. 2020, https://towardsdatascience.com/unsupervised-nlp-topic-models-as-a-supervised-learning-input-cf8ee9e5cf28.
Khalid, Irfan Alghani. “Implement Your Topic Modeling Using The BERTopic Library.” Medium, 25 Jan. 2022, https://towardsdatascience.com/implement-your-topic-modeling-using-the-bertopic-library-d6708baa78fe.
“PyLDAvis: Topic Modelling Exploration Tool That Every NLP Data Scientist Should Know.” Neptune.Ai, 16 Nov. 2020, https://neptune.ai/blog/pyldavis-topic-modelling-exploration-tool-that-every-nlp-data-scientist-should-know.
Yadav, Kajal. “The Complete Practical Guide to Topic Modelling.” Medium, 22 Jan. 2022, https://towardsdatascience.com/topic-modelling-f51e5ebfb40a.