{kind=link}
A deep learning–based document classification system built using TensorFlow, NLP preprocessing, and Streamlit.
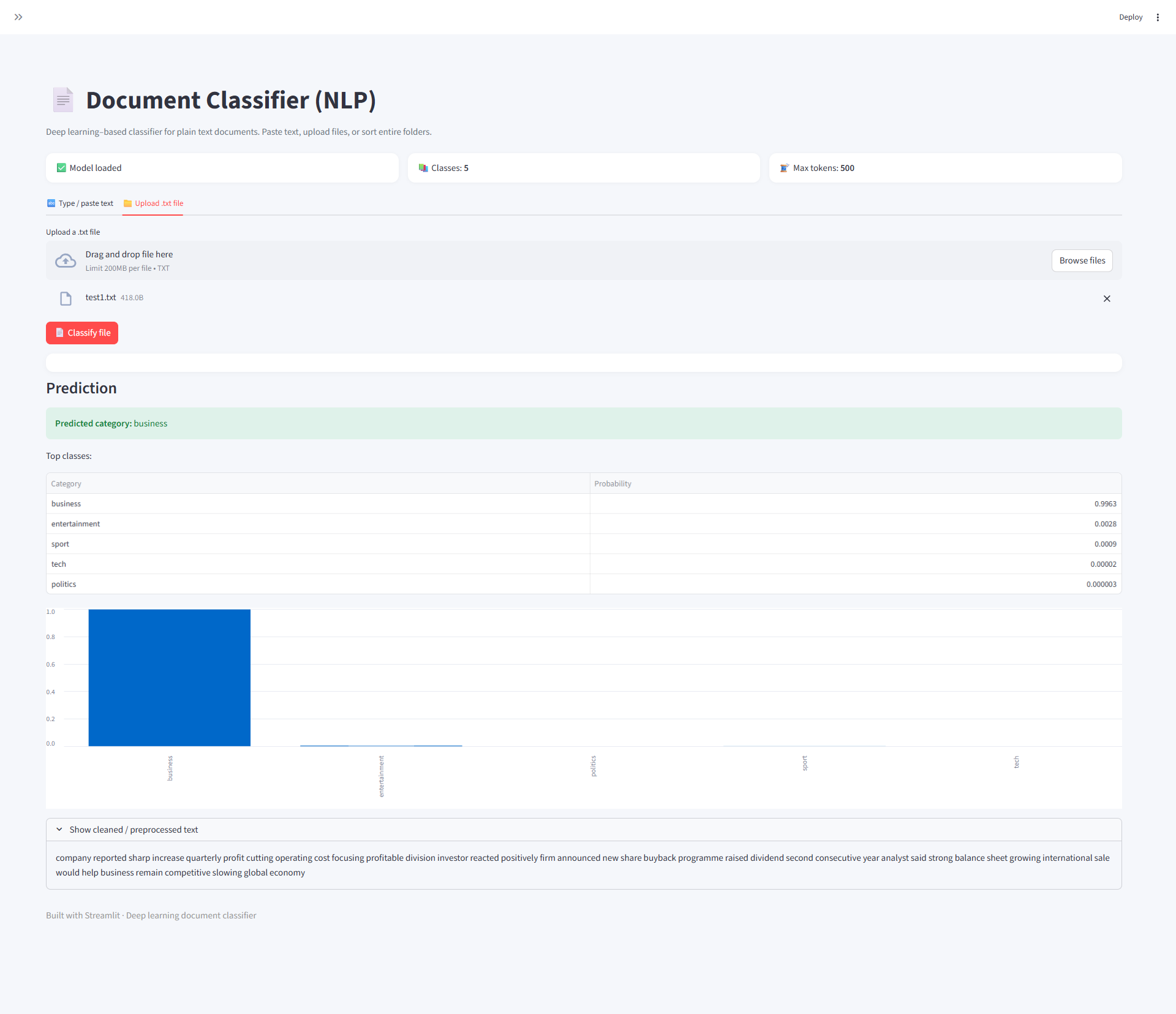
This project classifies raw text and .txt files into predefined categories and also supports bulk file sorting into folders based on predicted labels.
- ✅ Classify typed or pasted text
- ✅ Upload and classify .txt files
- ✅ Batch document classification from a folder
- ✅ Automatic file sorting into category folders
- ✅ Deep learning–based prediction using a trained neural network
- ✅ Interactive Streamlit web interface
- ✅ Displays class probabilities
- Python 3.10
- TensorFlow / Keras
- NLTK
- Streamlit
- NumPy & Pandas
- Regex for text cleaning
document-classifier-nlp/
│
├── Data/ # Training data
├── New_Files/ # New test files
├── UI_ScreenShot.png # App preview image
├── app.py # Streamlit app
├── basic_dl_doc_classification.ipynb # Training notebook
├── meta_basic.json # Model metadata (categories, max_len)
├── news_basic_dl_model.h5 # Trained deep learning model
└── requirements.txt # Required dependencies
conda create -n docclass python=3.10 -y
conda activate docclasspip install -r requirements.txtThe app automatically downloads:
- stopwords
- punkt
- wordnet
python -m streamlit run app.pyThen open the browser link shown in terminal, for example:
http://localhost:8501
This project uses:
- A trained deep learning model (
.h5) - A saved tokenizer (
.pkl)
⚠️ These files are not included in the repository due to size and security. You must place your trained model and tokenizer in the project root to run predictions.
- Type or paste text
- Upload
.txtfiles - Get predicted category + probability scores
- Input a folder path
- Automatically sorts
.txtfiles into category folders