The name Flux is derived from the word Fluxus, which means stream or flow, in Old French.
At the heart of a digital audience of 1.17 billion (source: Forbes), daily viewers are the creators who make it all possible. Of the 10 million active streamers today, 3 million (source: TwitchTracker) have turned their passion into a profession. Yet, the drive to succeed often leads to a breaking point, with 30-40% (source: Harvard University) of streamers experiencing extreme burnout due to the relentless demands of the always-on economy.
FluxIQ was inspired by these creators.
Being creators and streamers ourselves, with access to a huge community of streamers, we recognised the pressing need for real-time insights of our live streams and how they could help with metrics like viewer retention and churn. Our mission is to empower the next generation of streamers with real-time data and insights, ensuring that a career in content creation remains sustainable, healthy, and rewarding. FluxIQ is the tool we wish we had when we started, but it is also the co-pilot we absolutely need now.
Streaming has evolved from a hobby into a high-stakes digital workforce. However, the systems built to support this growth have absolutely neglected the human behind the camera.
One Peek At The Numbers
Recent data from 2024–2025 reveals a staggering shift in creator well-being:
-
Performance Obsession: 65% of creators report being obsessed with content performance and real-time analytics, leading to chronic anxiety.
-
The Identity Trap: 58% of streamers admit their self-worth declines immediately when a stream underperforms or viewership dips.
-
The Retention Cliff: While there are 7.3 million active channels on platforms like Twitch, the churn rate is massive, thousands of creators quit every month, citing mental exhaustion. It's also reported that new streamers are likely to quit after 6 months due to the insane demands.
-
Extreme Burnout: In specialised studies of full-time streamers, 62% experience burnout, and creators are twice as likely to report suicidal thoughts compared to the general population.
Why Existing Tools Fail?
Most streaming platforms provide Post-Stream Summaries. By the time a streamer sees they are losing audience interest or that the chat sentiment turned negative, the damage is already done. This retrospective data creates a cycle of Post-Stream Guilt rather than In-Stream Action.
FluxIQ transforms the chaotic stream of live data into a streamlined, actionable roadmap for creators. By integrating live audio processing with real-time sentiment tracking, we provide four pillar features designed to maximize growth while minimizing cognitive load. FluxIQ also focuses on being proactive instead of being reactive.
FluxIQ is an intelligent co-pilot designed to support live streamers by transforming chaotic real-time data into actionable insights. It tackles the primary driver of the creator mental health crisis — streamer burnout, by turning live streamer audio and chat velocity into a streamlined, AI-powered real-time decision engine.
We built FluxIQ because the demanding nature of streaming forces creators to make a choice, either obsess over analytics or focus on the show. By the time a streamer sees their post-stream report (what today's other stream analytics tools offer), the chance to pivot and to prevent viewer churn has passed. FluxIQ bridges that gap by being an AI digital manager that watches the data, so the creator streams stress-free.
Here’s how each feature addresses a real-world problem:
🎭 Live Sentiment & Vibe Check
The problem: Of the many stressors, streamers face audience anxiety, the fear that they are losing the room or that a few trolls are ruining the mood.
Our solution: A real-time engine powered by Confluent Cloud's Kafka stream processing and Gemini model's capability to aggregate markers like chat sentiment and velocity to show streamers a clear a vibe-score or sentiment score, allowing them to ignore outliers and lean into the positive energy of their community.
🎙️ Audio-to-Chat Correlation
The problem: Creators don't know which specific jokes, topics, or lines actually resonate with their fans and create engagement peaks.
Our solution: Using Confluent Cloud's ksqlDB, FlinkSQL and Kafka, we built a high-throughput pipeline that syncs the streamer’s spoken words with live audience reactions/ chats. This tells the streamer exactly which segments drove the most joy or engagement, including which kinds of chats (responses) were triggered by a given statement, providing a surgical level of content strategy in real time.
✂️ Automated Viral Clip Discovery
The problem: The post-stream grind of editing or even re-watching an 8-hour VOD to generate 60-second clips is soul-crushing and leads to rapid burnout and is definitely not the best use of anyone's time.
Our solution: FluxIQ monitors massive spikes in sentiment and engagement using data stored in Google Cloud's Firestore to automatically flag and package downloadable clips via FFmpeg subprocesses. High-potential viral moments are ready for Instagram, TikTok, or Shorts the second the stream ends, or at any time beforehand.
🧠 Predictive Growth Insights
The problem: Decision fatigue. Streamers often stay live for hours too long or miss the exact moment their engagement peaks or dips because they are distracted by the act of performing.
Our solution: FluxIQ identifies patterns in viewer churn and engagement spikes in real time and uses Gemini to perform predictive modelling. It provides a single, actionable instruction like "Engagement is dropping; start your Q&A now" or "Audience highly active, do product promos if any", allowing the streamer to maximise impact without the guesswork.
⚡ Proactive Dashboards
The problem: Existing analytic tools are reactive; they offer data only after the stream ends, when it's too late to pivot. This creates a cycle of non-actionable insights, which the user cannot carry over to the next stream since streams are highly dynamic.
Our solution: FluxIQ is proactive. By processing data in Confluent Cloud + Gemini Model Pipelines in real time and fetching the data ingested into Google Cloud's Firestore, we provide in-stream interventions. Instead of analysing a viewership dip hours later, FluxIQ alerts you the moment sentiment shifts, allowing you to pivot your content immediately and stay in control.
🔒 Creator-First Privacy
The problem: Handling live stream audio and chat data requires immense trust and ultra-low latency. Creators are rightfully wary of how their personal data is processed.
Our solution: FluxIQ utilises Confluent Cloud’s enterprise-grade security to ensure all data in transit is encrypted and isolated. By using ephemeral Kafka topics with low retention times, audio processed via FFmpeg never touches a permanent database in raw form.
Since this project falls into the Confluent Track and also heavily uses AI to manipulate data (large amounts of it!) in motion we made use of every offering of Confluent Cloud like Kafka for stream processing, FlinkSQL for real-time batching and to maintain live state.
All our services are deployed to Google Cloud Run, and our data store is Google Cloud Firestore. We've also leveraged Google's Gemini Model for intelligent real-time processing, along with Google Cloud's Pub/Sub for communication between services.
🛠️ The FluxIQ Tech Stack
Backend & Data Pipeline
- Python 3.11 & Flask: Core application logic and API orchestration.
- yt-dlp: Used for high-speed metadata extraction and dynamic stream link acquisition.
- FFmpeg: The engine for real-time audio demuxing and stream processing.
- gRPC: High-performance, low-latency framework for persistent YouTube server connections.
- REST API: Standardised endpoints for frontend-to-backend communication.
- Confluent Cloud:
- Apache Kafka: The high-throughput backbone for all data in motion.
- FlinkSQL: Real-time stream processing and windowed data batching.
- ksqlDB: Stateful stream processing for complex joins (e.g., Audio + Chat).
- Confluent Python Client: The bridge between our Flask app and Kafka clusters.
- Google Cloud Integration
- Google Gemini (2.5 Flash): Our reasoning engine for predictive modelling, contextual correlation, and sentiment analysis.
- Google Cloud Pub/Sub: Asynchronous messaging to decouple stream ingestion from the main API.
- Google Speech-to-Text (STT) V2: Real-time conversion of live audio streams into transcripts.
- Google Firestore: NoSQL document database for storing processed insights and analytics.
- Google Secret Manager: Secure storage for sensitive API keys and incognito session cookies.
- Google Cloud Storage (GCS): High-availability buckets for video downloadable file staging.
- Google Cloud Observability: Comprehensive logging (Cloud Logging) and performance monitoring (Cloud Monitoring).
- Google Cloud IAM: Access control for secure communication between GCP and Confluent.
Frontend & UI/UX
- React & JavaScript: Modern component-based architecture for a responsive dashboard.
- Chakra UI: Accessible and modular component library for consistent styling.
- Redux Toolkit (RTK):
- Redux Store: Centralised global state management.
- RTK Query: Optimised data fetching and caching for real-time updates.
- Figma: Design and prototyping of our user interface.
Deployment & DevOps
- Google Cloud Run: For deploying containerised microservices, for 4 of our microservices
- GCS Hosting: Used for fast delivery of the React frontend build.
- Docker: Containerization of backend services to ensure parity between local and cloud environments.
Our Endpoints
| Endpoint | Description |
|---|---|
/video_id |
For ingesting video-id to google cloud pub-sub from stream-server |
/analyze |
To query top chats, chat sentiment, active users from firestore |
/correlate |
To find records that have a correlation with audio and chat |
/download |
created the trigger for job to create key moments |
/video/poll |
to check status of video downloads from firestore |
/predict |
to predict future insights from previous data in firestore |
Now, let's examine each feature in greater technical detail:
#1 Live Sentiment & Vibe Check
User Flow
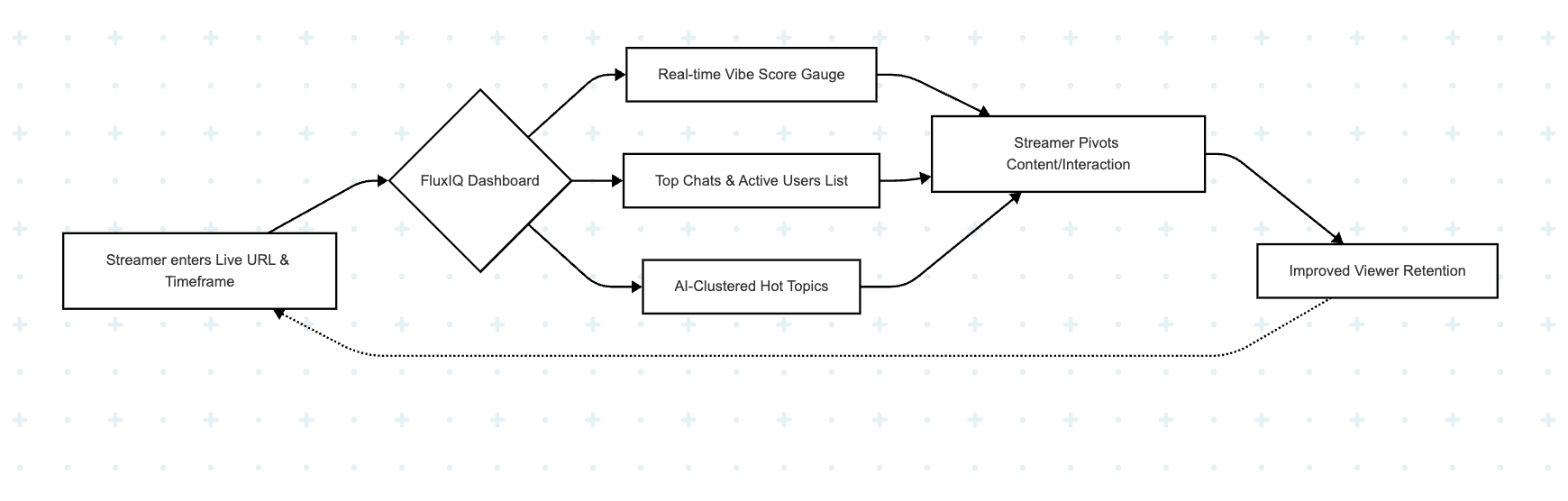
The streamer enters their Live URL and defines the desired Time Frame on the FluxIQ dashboard. Instantly, the interface transitions into a live command center, populating with real-time sentiment scores and engagement metrics. The user sees a granular breakdown of the stream's health, including a dynamic Vibe Score, a list of Top Chats that are driving the current energy, identification of Most Active Users, and AI-clustered Hot Topics. This allows the streamer to immediately understand the audience's mood and pivot their content without ever leaving the broadcast.
Technical & Authority Flow
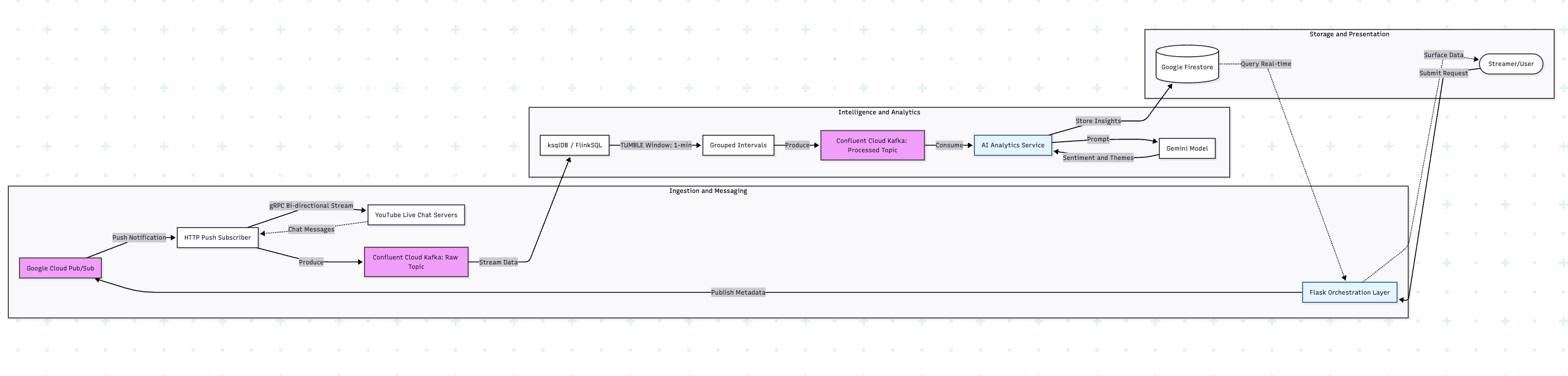
When a request is submitted, it hits a Flask server which acts as the orchestration layer, publishing the video metadata to a Google Cloud Pub/Sub topic. This decouples the initial request from the task of data ingestion, allowing the system to scale for thousands of concurrent streamers. HTTP Push Subscribers consume these messages and establish high-speed gRPC connections to the YouTube servers to fetch live chats. gRPC is utilised here for its superior efficiency over traditional REST; it provides a bi-directional, low-latency stream that ensures no messages are dropped during high-velocity chat bursts. These chats are then ingested into a Confluent Cloud Kafka Topic, which serves as the resilient backbone of the pipeline, easily handling ingestion rates of 90–200 messages per second.
To transform this raw data into intelligence, we use ksqlDB powered by FlinkSQL to group the messages into 1-minute intervals using a TUMBLE window. A Tumbling window is the optimal choice here because it creates fixed-size, non-overlapping, and contiguous time blocks. These grouped batches are pushed into a secondary Kafka topic, where a dedicated service consumes them and passes the organised text to the Gemini Model for deep sentiment and thematic analysis. The processed insights, including the Vibe Score, Hot Topics, Top chats, etc, are stored in Google Firestore, which the Flask server queries to surface real-time, actionable data on the streamer's frontend. All in real-time!
#2. Audio-to-Chat Correlation
User Flow
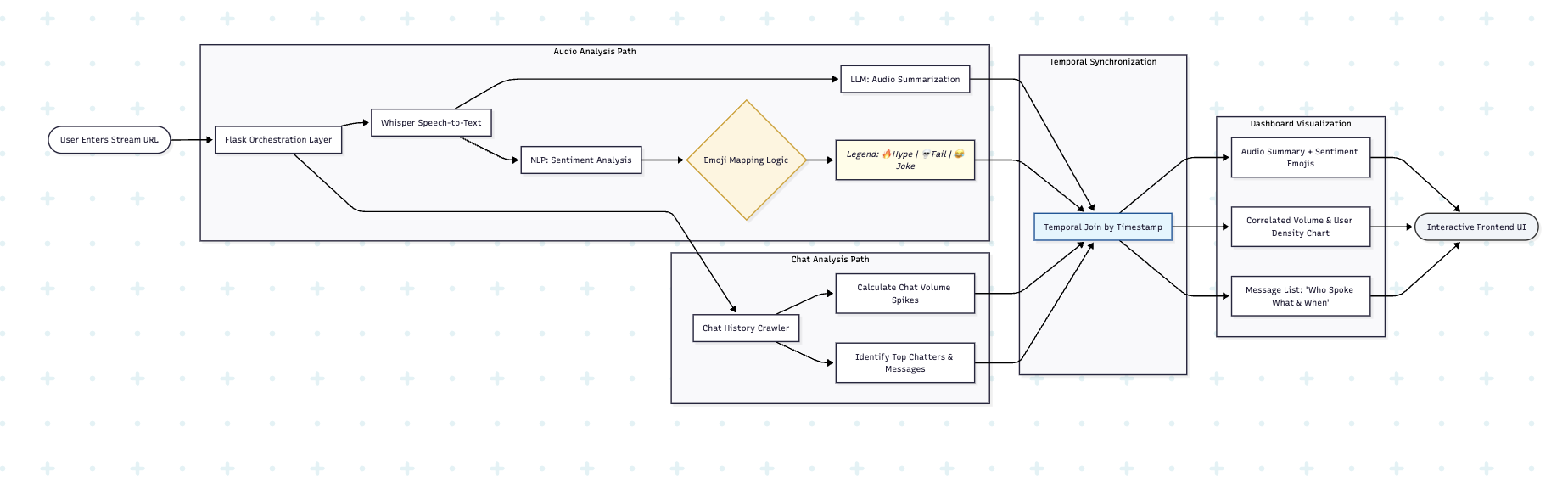
The streamer enters their Live URL and selects the Time Frame for analysis. The dashboard generates a synchronised timeline where every sentence spoken by the streamer is displayed alongside its specific chat correlation. The user can see the exact chat volume and sentiment triggered by specific topics, jokes, or statements. This allows the creator to identify high-impact moments with surgical precision, understanding not just that the audience cheered, but exactly which word caused the roar.
Technical & Authority Flow

Similar to the previous feature, the process begins with a GCP Pub/Sub push trigger that activates a specialised ingestion worker. This worker uses yt-dlp to extract dynamic stream links, which are then fed to an FFmpeg subprocess running in a background thread. This subprocess captures the live HLS audio stream (.m3u8) in real time. The raw audio is immediately processed by the Google Speech-to-Text (STT V2) API, converting spoken words into high-fidelity transcripts. These transcripts are ingested into a dedicated Confluent Cloud Kafka Topic at a massive scale of 500–600 events per second.
The intelligence happens in ksqlDB, where we use FlinkSQL to perform a complex Left Join between the audio transcript stream and the live chat stream. Both streams are synchronised using 1-minute TUMBLE windows, ensuring that every sentence is perfectly aligned with the chat messages sent in that same window. This joined, high-context data is pushed to a secondary Kafka topic, where a service consumes the batches and feeds them to the Gemini Model. Gemini performs contextual correlation, identifying which specific spoken phrases drove the correlated chats and correlated users. The final output is stored in Firestore, where it is queried by the Flask server to render the synchronised timeline on the frontend.
#3. Predictive Insights
User Flow
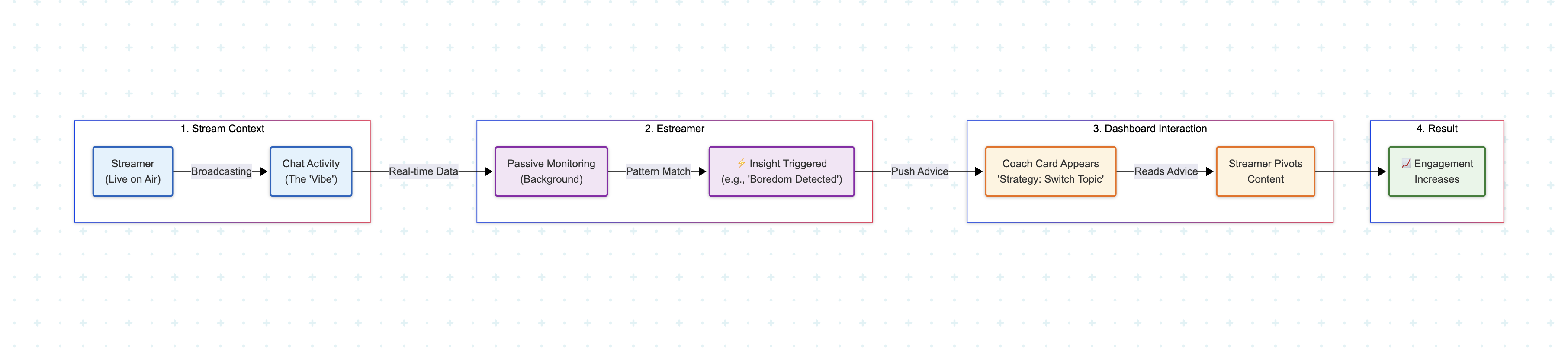
Imagine having a professional TV producer whispering in your ear, telling you exactly when the audience is getting bored or when excitement is peaking. This our FluxIQ. As you stream, the AI silently analyzes the chat's speed and mood in the background. Instead of making you read every single message, the dashboard gives you a simple forecast. It might say, "Energy is dropping, try switching games," or "Chat is loving this story, keep going!" This allows you to adjust your content in real-time to keep your audience hooked, without needing to be a data scientist.
Technical & Authority Flow
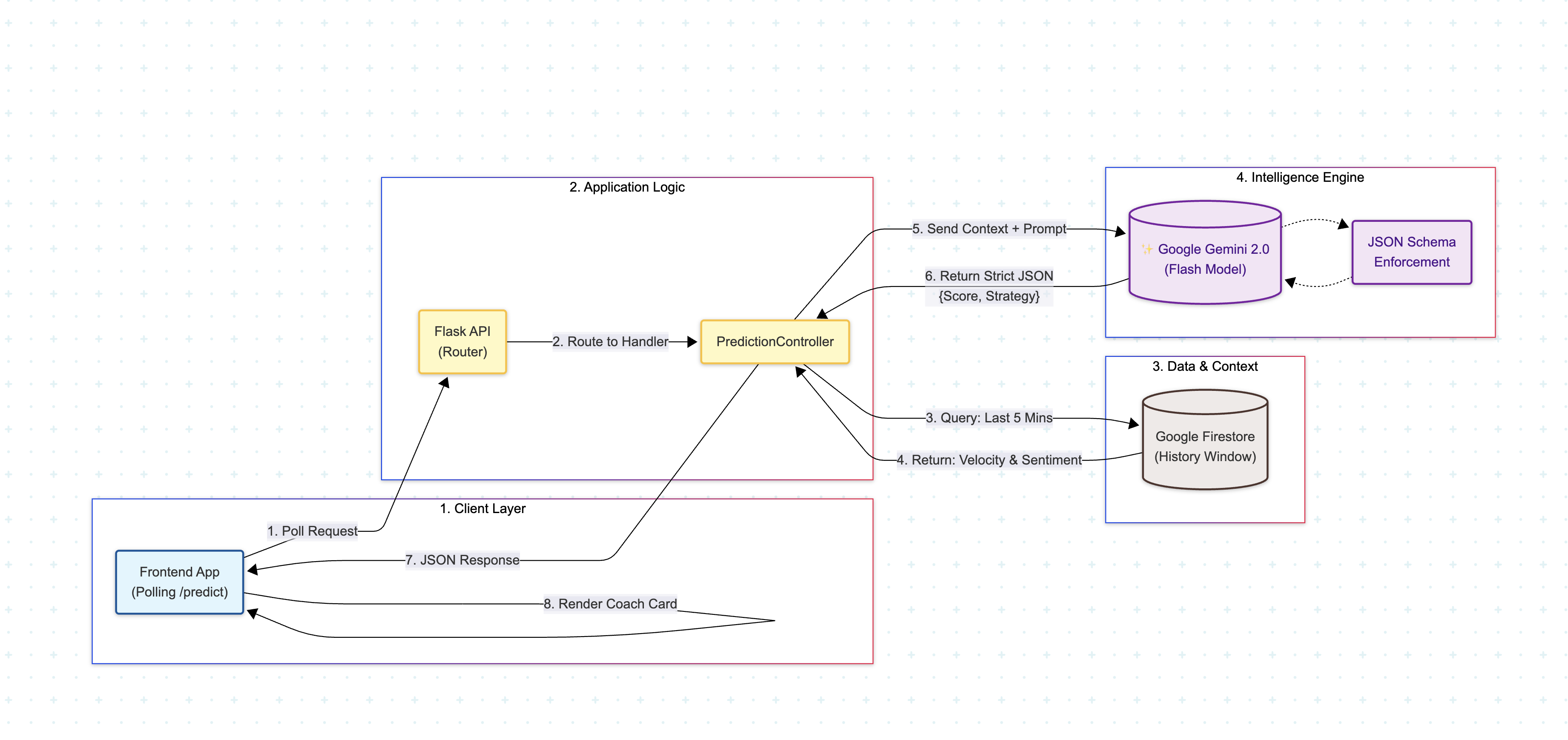
When the frontend polls the /predict endpoint, the PredictionController executes a high-performance query against Google Firestore, aggregating the last five minutes of granular data—such as message velocity, sentiment variance, and top keywords—into a chronological "Context Window." This serialized context is then injected into Google Gemini 2.0 Flash, where a strict JSON Schema enforces the model to return a structured output containing a sentiment_score, strategy, and reasoning, ensuring crash-proof reliability. The resulting JSON is delivered to the client in under 800ms, allowing the frontend to instantly render a sentiment trend line and display the "Coach Card" for immediate, data-backed strategic advice.
#4. Automated Viral Clip Discovery
User Flow
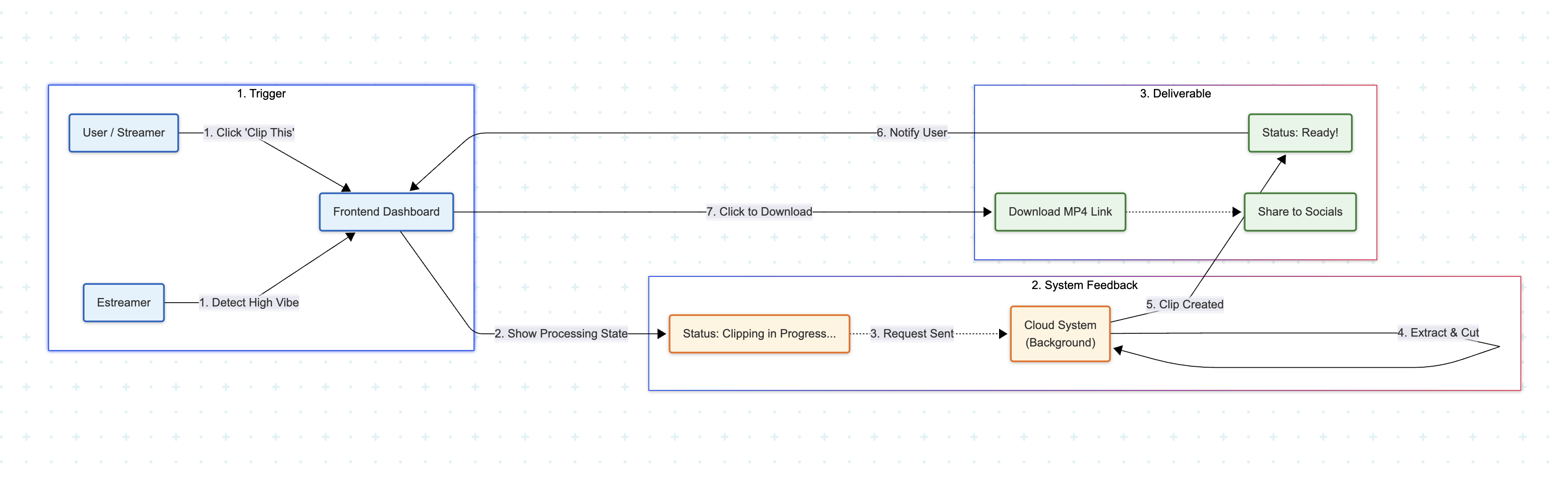
When a big moment happens, whether our AI spots it or you click the button, the system instantly gets to work. You don't need to pause your game, worry about recording software, or slow down your computer. You just keep streaming. Within moments, the status changes to "Ready," and your clip is waiting for you. You get a downloadable video file immediately, allowing you to turn a live moment into a viral social media post while the hype is still fresh.
Technical & Authority Flow
Deep in the backend, a Google Cloud Run worker acts as the consumer. It utilizes a secure injection of cookies.txt from Google Secret Manager to authenticate requests, bypassing age restrictions and bot detection systems. We utilize a highly customized implementation of yt-dlp configured to bypass Cloud Run’s read-only filesystem restrictions and enforce IPv4 networking to fetch the highest quality raw stream URL. This URL is fed into FFmpeg, which performs a precise, lossless cut of the video segment.
Finally, the processed MP4 is uploaded to Google Cloud Storage (GCS) for durable hosting. Upon completion, the worker publishes a result message to a secondary video-status Kafka topic. A background listener consumes this status and updates Firestore, triggering a real-time UI update on the client. This entire cycle from Kafka ingestion to cloud storage demonstrates a robust, fault tolerant architecture capable of handling concurrent clip requests without dropping a frame.
Building a real-time data pipeline of this scale always presents hurdles. We also ran into quite a lot of them!
We've elaborated them here:
1️⃣ Deployment Environment Variable Issue
Initial attempts to automate deployment using a terminal-based script (./deploy.sh) to host services on Google Cloud Run failed due to persistent environment variable injection issues. We pivoted to a manual configuration strategy via the Google Cloud Console, ensuring all secure variables were correctly mapped to allow for a stable, production-ready cloud deployment.
2️⃣ Temporal Data Alignment in Confluent
As first-time users of FlinkSQL and ksqlDB, we discovered that Confluent Cloud is highly sensitive to timestamp formats. Our initial ingestion used ISO-8601 strings for time-related data, which resulted in null values when running a query or join. After deep-diving into the documentation, we re-engineered our ingestion service to ingest data in epoch milliseconds, enabling seamless windowed queries and temporal consistency.
3️⃣ Handling Silent Window Edge Case
We encountered an edge case where audio-less streams or silent segments broke our inner join logic between audio and chat. To ensure a persistent output even during silence, we transitioned to a Left Join strategy within ksqlDB. This ensures that highly active live chat data is still captured and analysed even if the audio stream is momentarily inactive.
4️⃣ YouTube Ingestion & Bot Mitigation
Fetching live data via yt-dlp on a remote server (GCP Cloud Run) triggered YouTube’s bot detection, a problem that didn't exist in local testing and by the time it was detected we were slightly running short on time. After evaluating residential proxies that rotate IP addresses (turned out to be a bit harsh on our pockets!), we implemented a solution using incognito-generated cookies for longer-lived sessions, which were passed as an option to yt-dlp. This allowed our Google Cloud Run services to maintain stable connections without being flagged as automated traffic.
5️⃣ Persistent Audio Streaming & API Resiliency
Maintaining a live, long-running connection to YouTube via FFmpeg was technically demanding due to frequent network errors and a strict 300-second timeout on the Google Speech-to-Text (STT) API despite an active stream. We engineered a self-healing pipeline by running the FFmpeg worker on a persistent background thread wrapped in a custom retry_with_backoff function to handle network instability. To bypass the Google Cloud API limits, we implemented a timer-based conditional that monitors the session age; if the connection exceeds 290 seconds, it proactively re-alives the session to ensure a continuous inflow of audio data into our Confluent Cloud Kafka topics.
Almost every aspect of the project, from making a persistent connection to the YouTube server to deploying the services, was an accomplishment for us. Here's one that stands out:
We built a production-grade, high-throughput pipeline for real-time data processing at massive scale. Some of our test data included chat messages at 106 messages/sec and audio stream transcripts at 543 events/sec, and our data pipeline handled them with millisecond latency.
Although we've been working with software for a few years, deployment is always scary. For this project, we built the full lifecycle of FluxIQ with a microservices architecture and a robust CI/CD strategy. We deployed four containerised services to Google Cloud Run, orchestrating a communication layer where Google Cloud Pub/Sub handles asynchronous event signalling, and Kafka manages the high-velocity data backbone and any intermediate communication. By hosting the React frontend on Google Cloud Storage and integrating Google Cloud Observability, we established a fully self-hosted, observable pipeline, entirely on our own.
Here are some of our key learnings, especially from technologies we were dealing with for the first time:
1️⃣ We discovered the efficiency of the Fan-Out architecture. We learned how to configure a single topic to push a single video-id message across multiple independent subscribers simultaneously. This allowed our various microservices to trigger their specific ingestion and analysis tasks in parallel with minimal configuration, reinforcing the value of decoupled, asynchronous communication.
2️⃣ Working with FlinkSQL for the first time was a deep dive into real-time stream processing. We spent days understanding the docs, so that we would be able to build the best possible pipeline and batch data efficiently. We learned about Tumble Windows vs. Sliding Windows and ultimately chose Tumble Windows to prevent data overlap and ensure clean, non-redundant batches for the Gemini model. We also learnt about different types of joins to get the best batched set.
3️⃣ As a team of two managing four separate services, we learned that API contracts are non-negotiable. By establishing strict schema discipline early on, we were able to build the frontend, router, and ingestion workers concurrently without integration friction.
4️⃣ Working on the frontend was a really enlightening process for us! What we initially thought was a low-priority task that could be offloaded to an AI turned out not to be so. We spent time understanding the two most efficient ways of showing data in real time, including smart polling and web sockets. We eventually decided on polling. We also had to brainstorm and learn how to show video download progress in real time.
We want to take FluxIQ to heights and reach every streamer out there, hoping to ease their lives in any magnitude possible. These are some next milestones for FluxIQ:
Transition to Full-Duplex WebSockets
While smart polling served our MVP, the next architectural leap is moving to a persistent WebSocket-based frontend. This will eliminate the overhead of HTTP request-response cycles, delivering true sub-second latency.
Omni-Platform Support
We plan to expand our ingestion engine beyond YouTube to support Twitch, TikTok Live, and Instagram Live. By abstracting our ingestion layer, we can provide a unified command centre for creators who multi-stream across different ecosystems.
Multimodal Emotion AI
Beyond text and speech, we aim to integrate visual sentiment analysis. By processing the streamer’s webcam feed (facial landmarks and body language) + using Gemini to read the video contents, FluxIQ will be able to correlate audience sentiment with the creator’s physical energy, offering a 360-degree view of the broadcast's health.
Support for emojis, multi-language support
We do currently offer support for emojis as well as various different languages, but we would like to make it better and fine-tune models to handle these cases more efficiently.