I have been given 3 different data files(excel, csv, json) from Camdens Council about trees and their environment in the local area to determine if they can create 3 new initiatives:
* List of all trees in the borough
* Series of “Tree Walks” brochures with informations about interesting trees and parks locations in the area
* Enviroment Report of the total carbon and pollution benefit provided by all their trees with information about trees removed, trees planted and the net carbon and pollution impact of this activity
Additional informations:
* Trees data set is for public use and owned by Council(downloaded from website, excel file)
* Common Names data set is for public use and owned by Holiticultural Website(scraped from website, json file)
* Environment data set is for internal use and owned by Council(extracted from database, csv file)
⇨ Uploading three different data files(excel/ csv/ json) to our notebook and performing some simple checks(head/ shape/ columns/ dtypes) using Pandas Library with each data set to gain some knowlage about our data
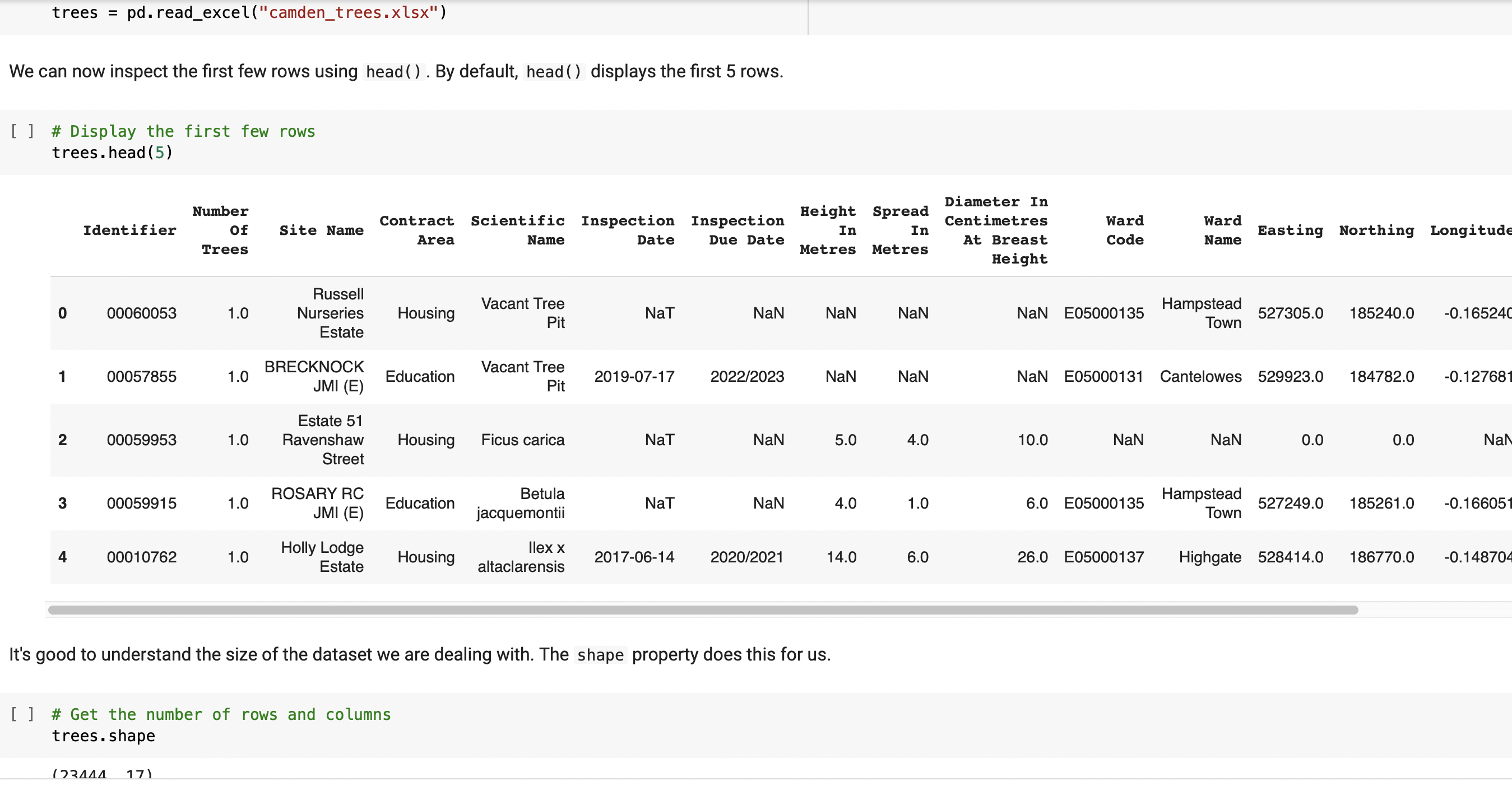
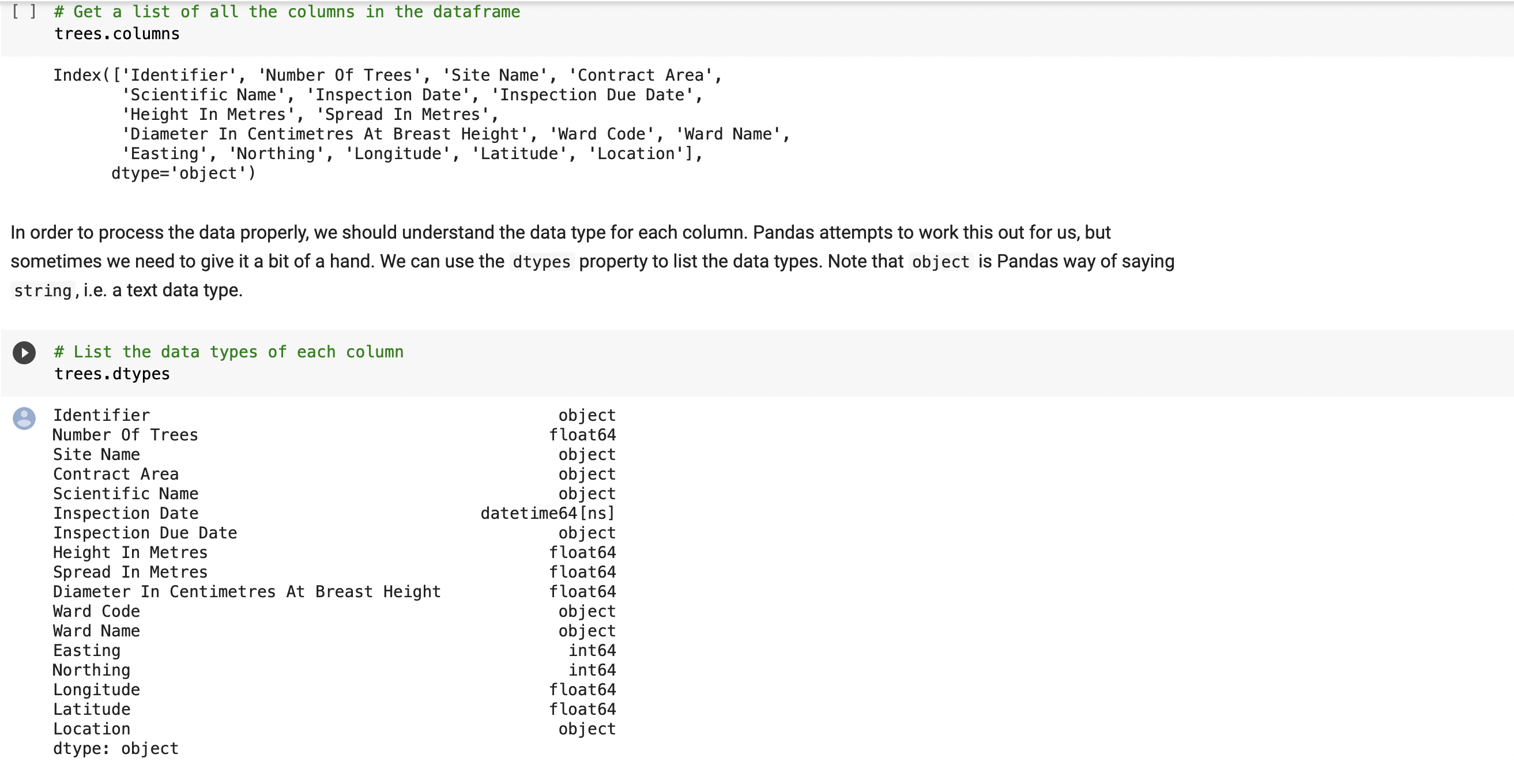
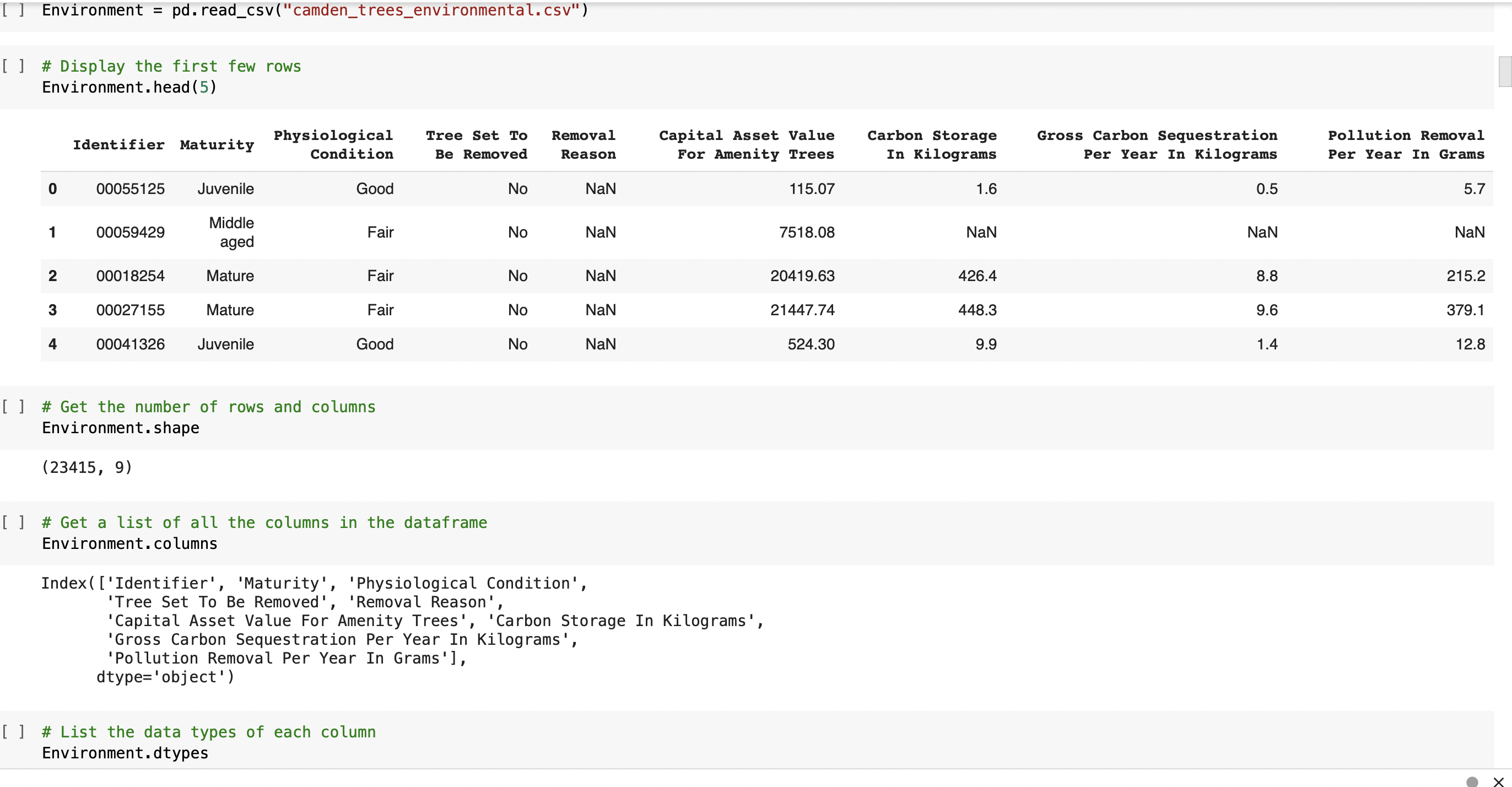
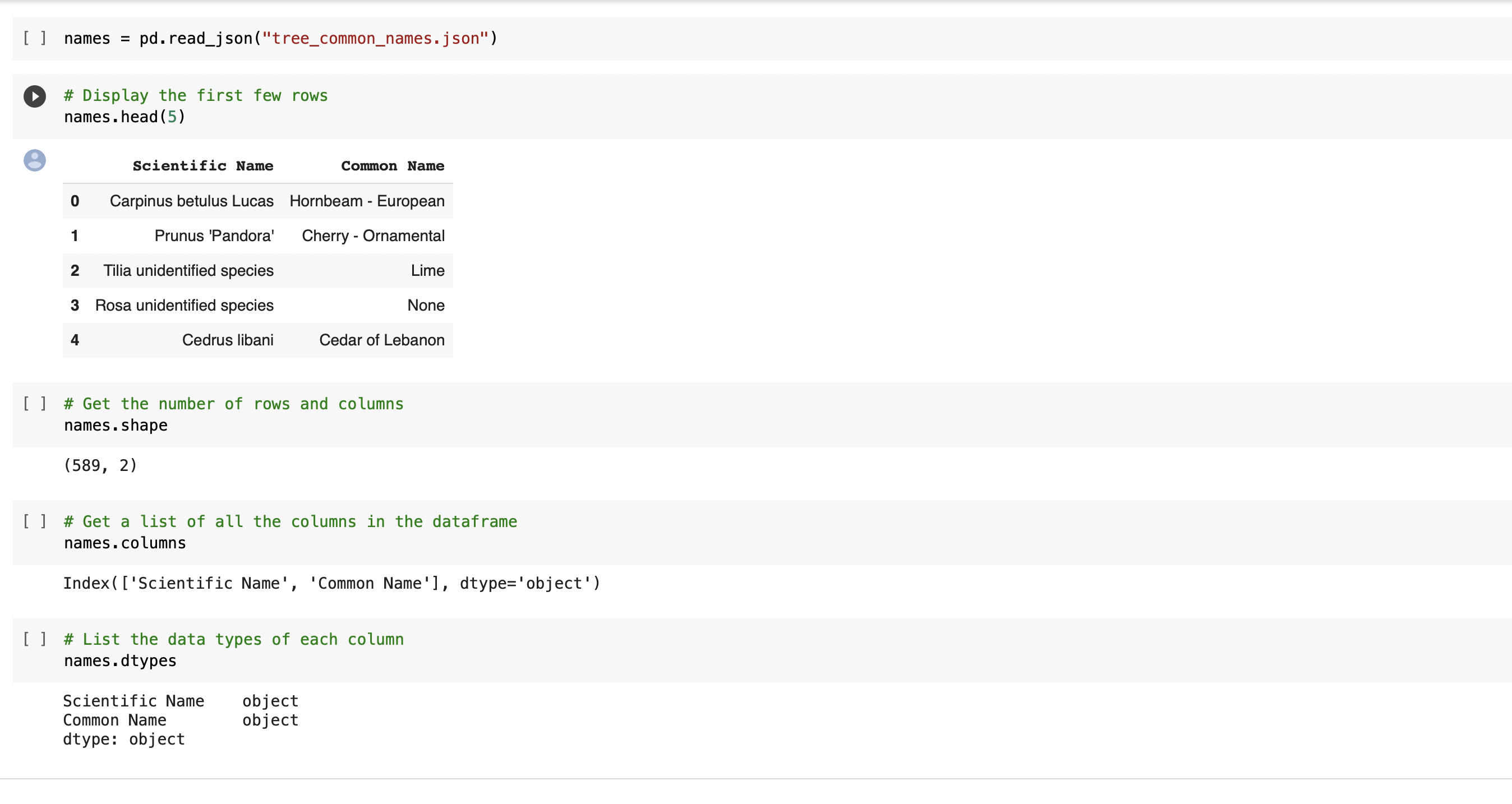
⇨ Performing further data checks (value_counts/ describe/ unique) to understand with what kind of data we'll dealing - qualitative(nominal/ ordinal/ binary) or quantitative (discrete/ continous). Wider check of our float data types to look for missing values. Classifying data type in all columns from all data sets
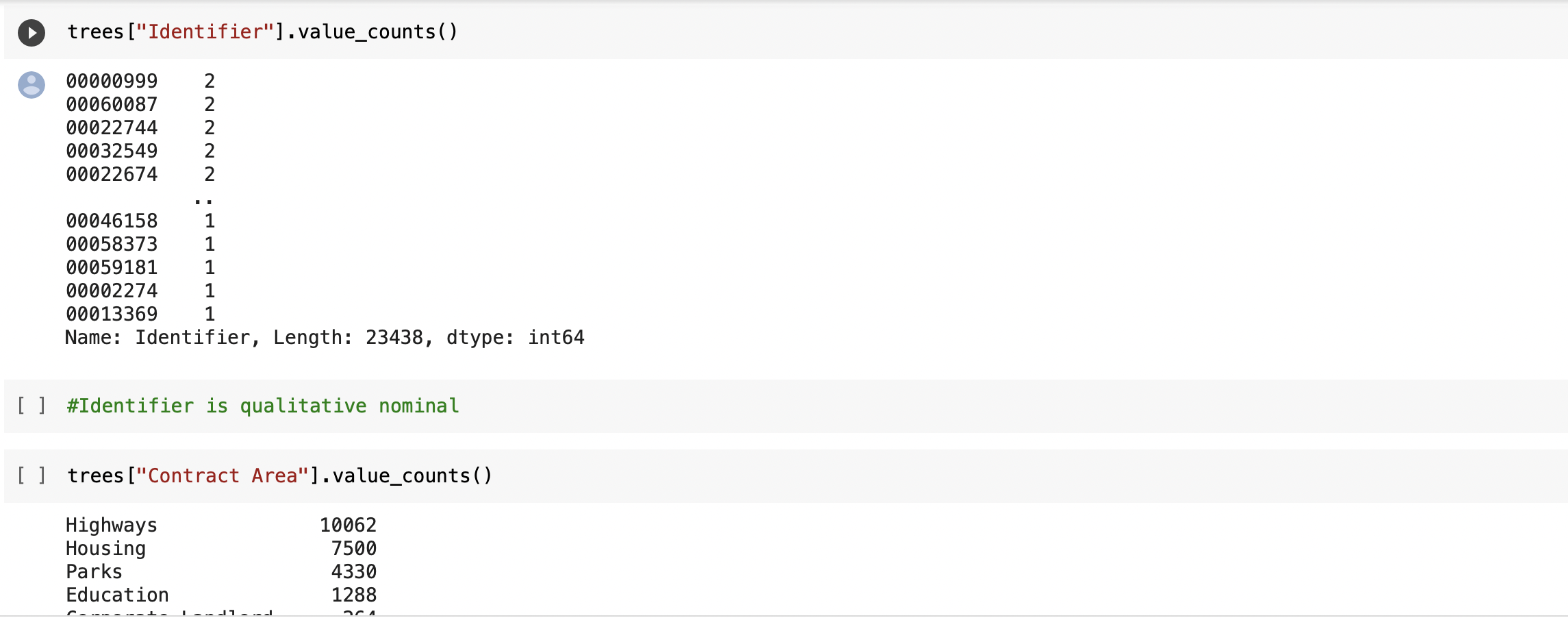
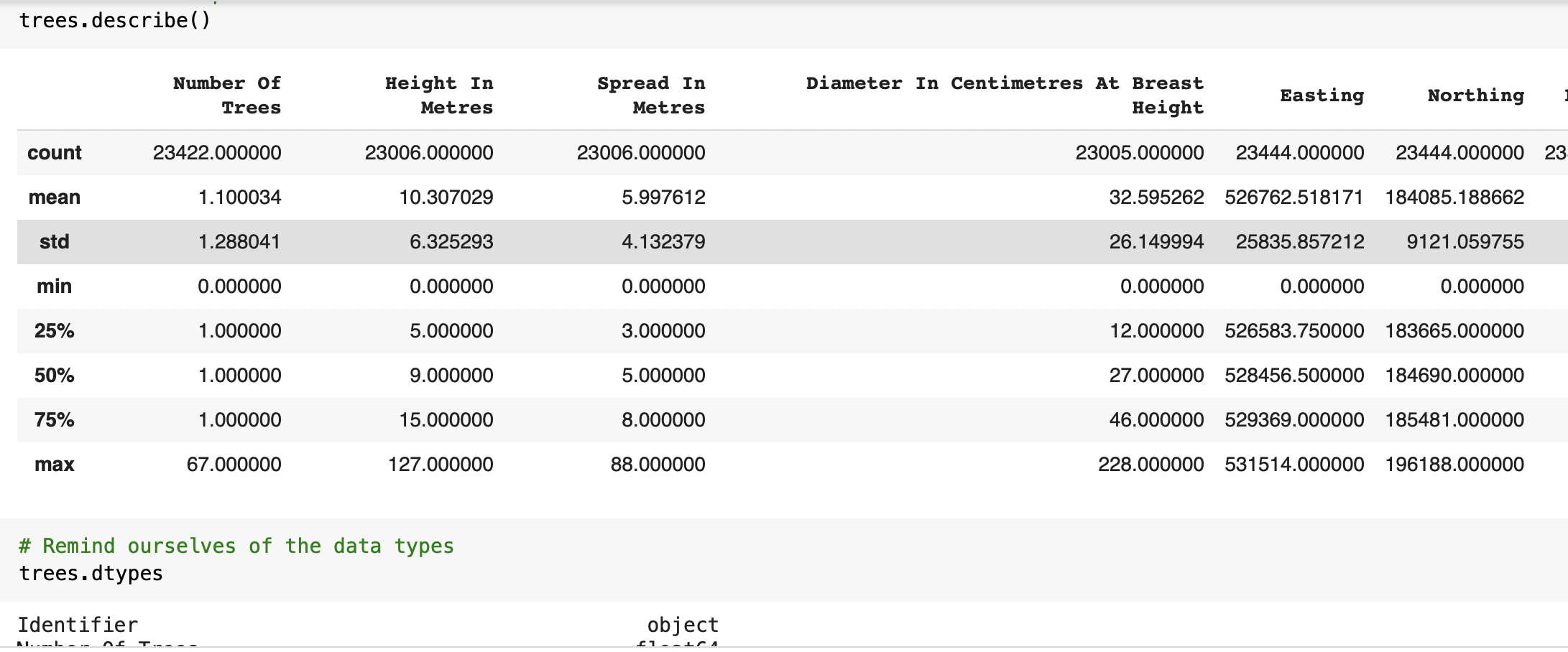
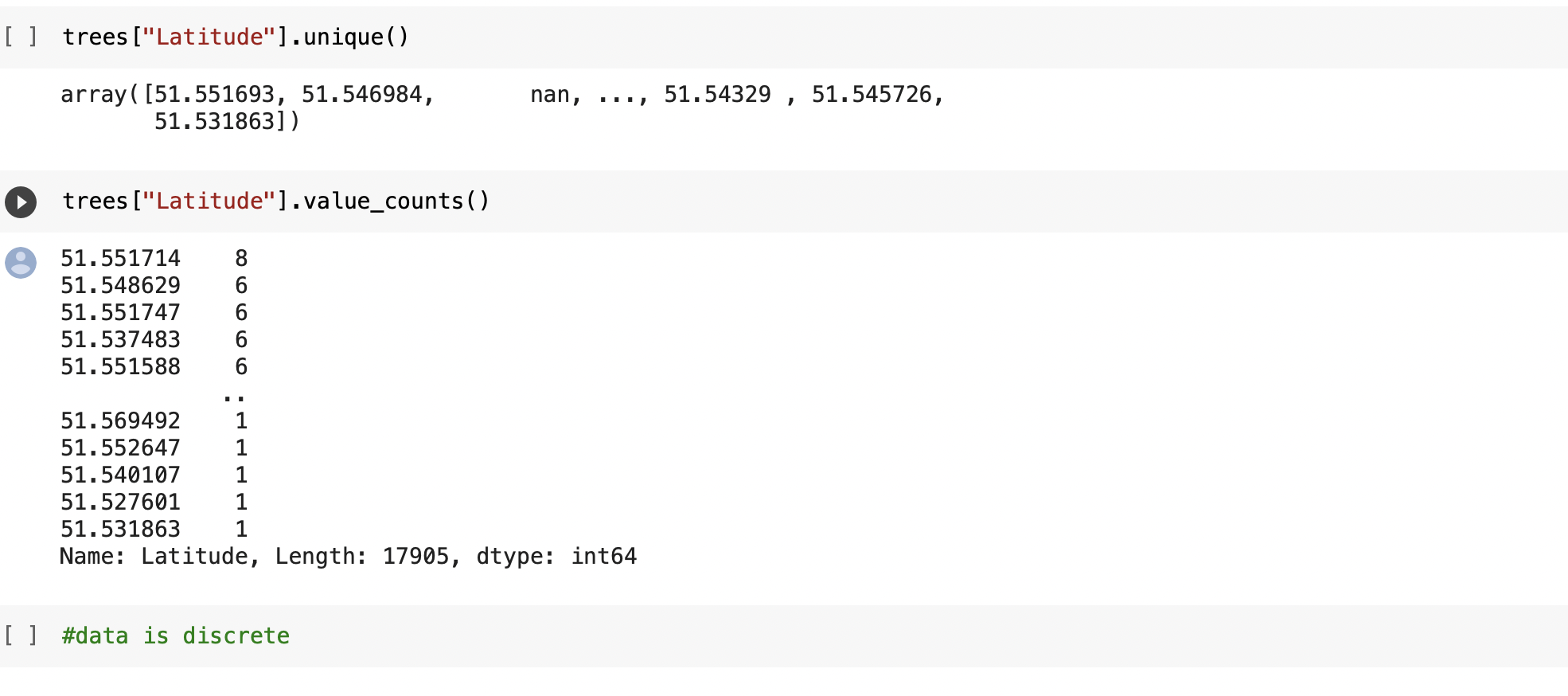
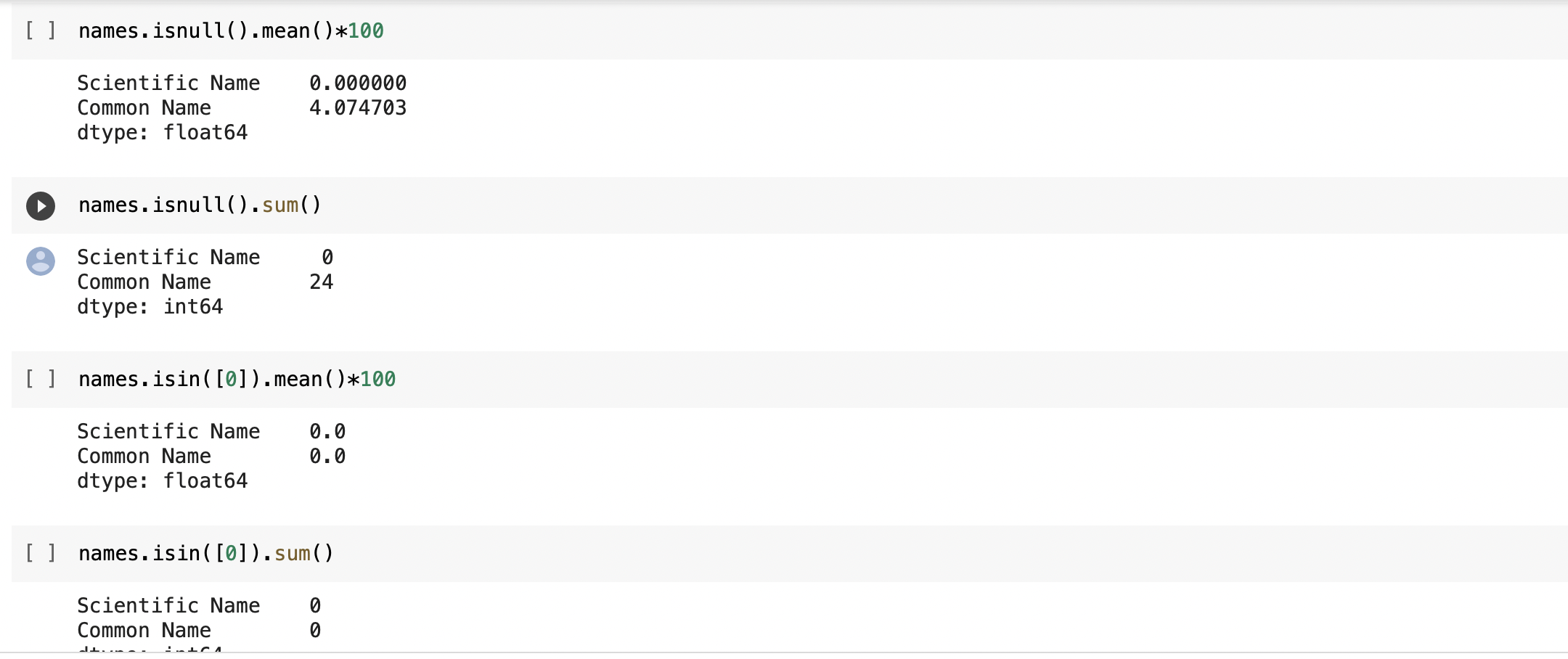
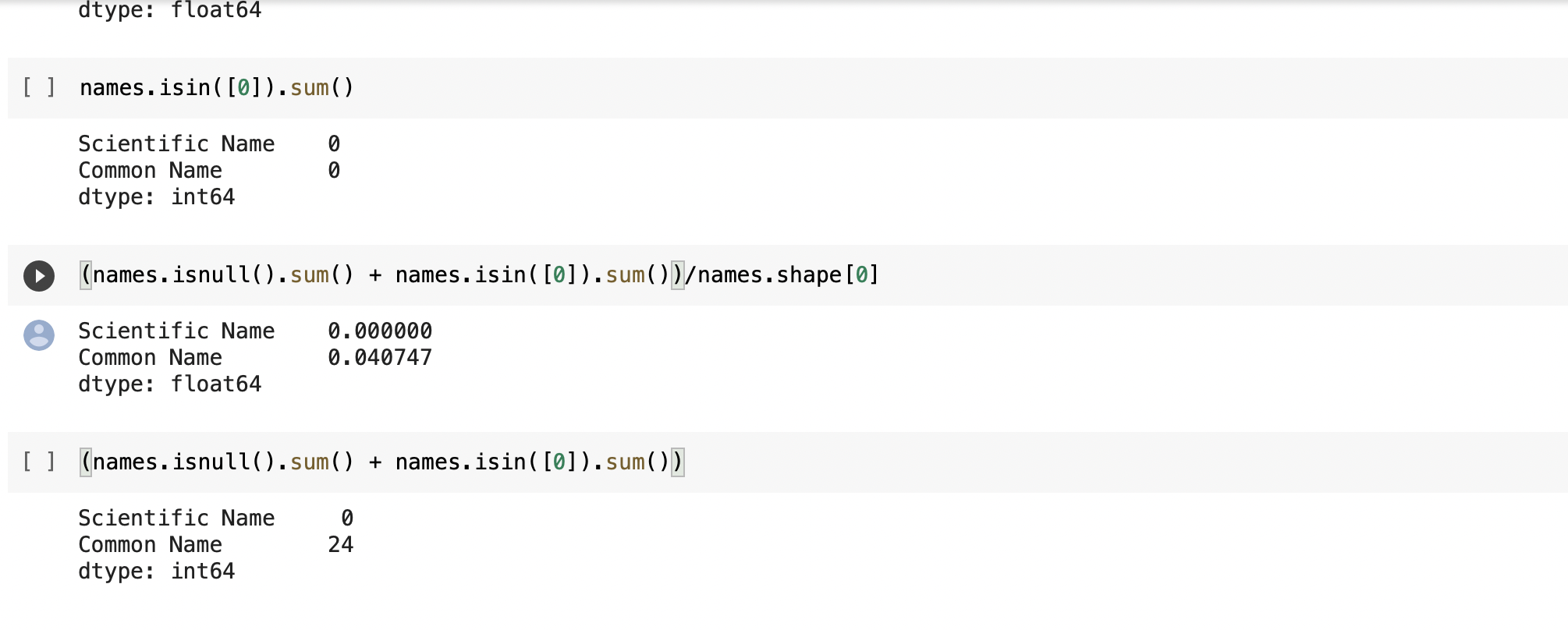
⇨ Checking all data sets for nulls and zero values to find out how big of a problem we having with missing values
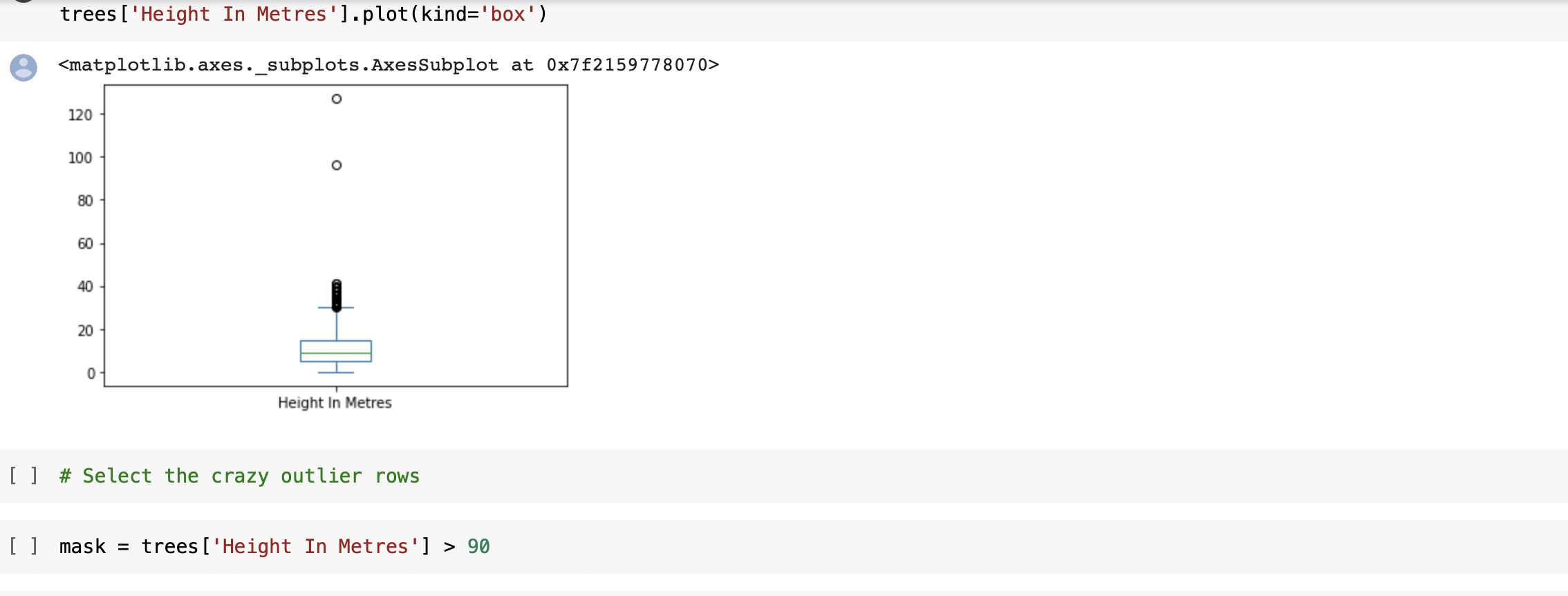
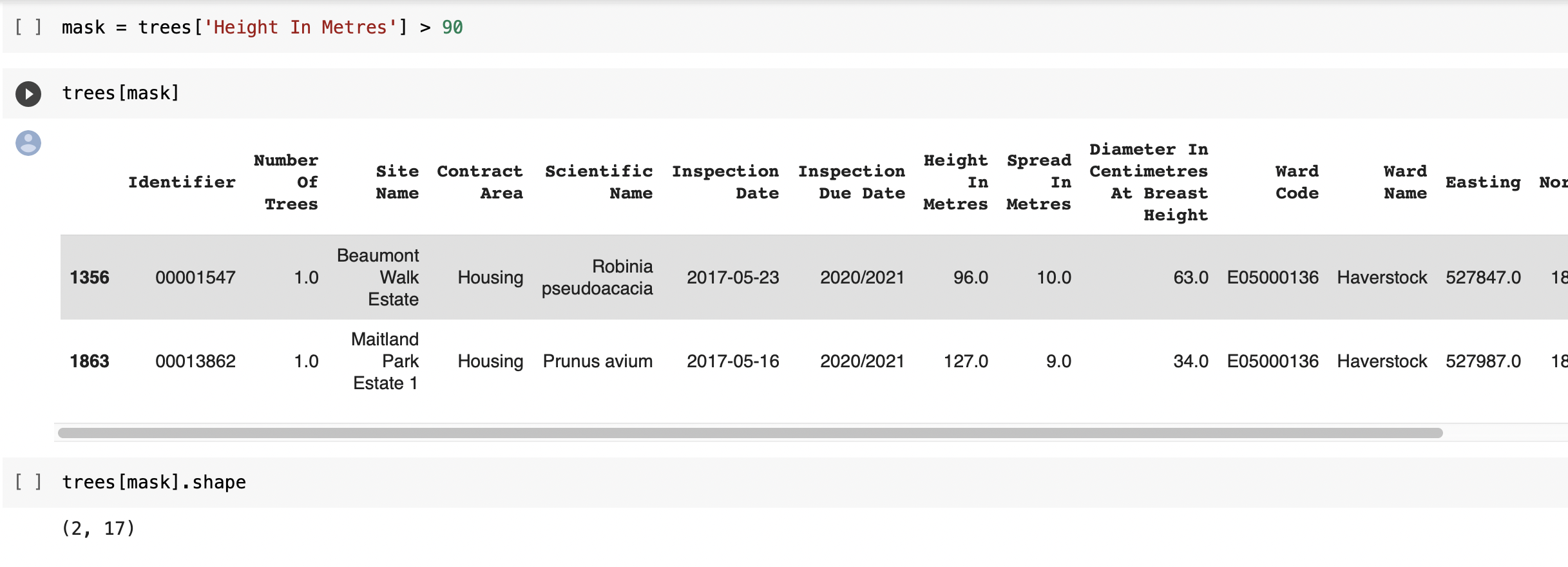
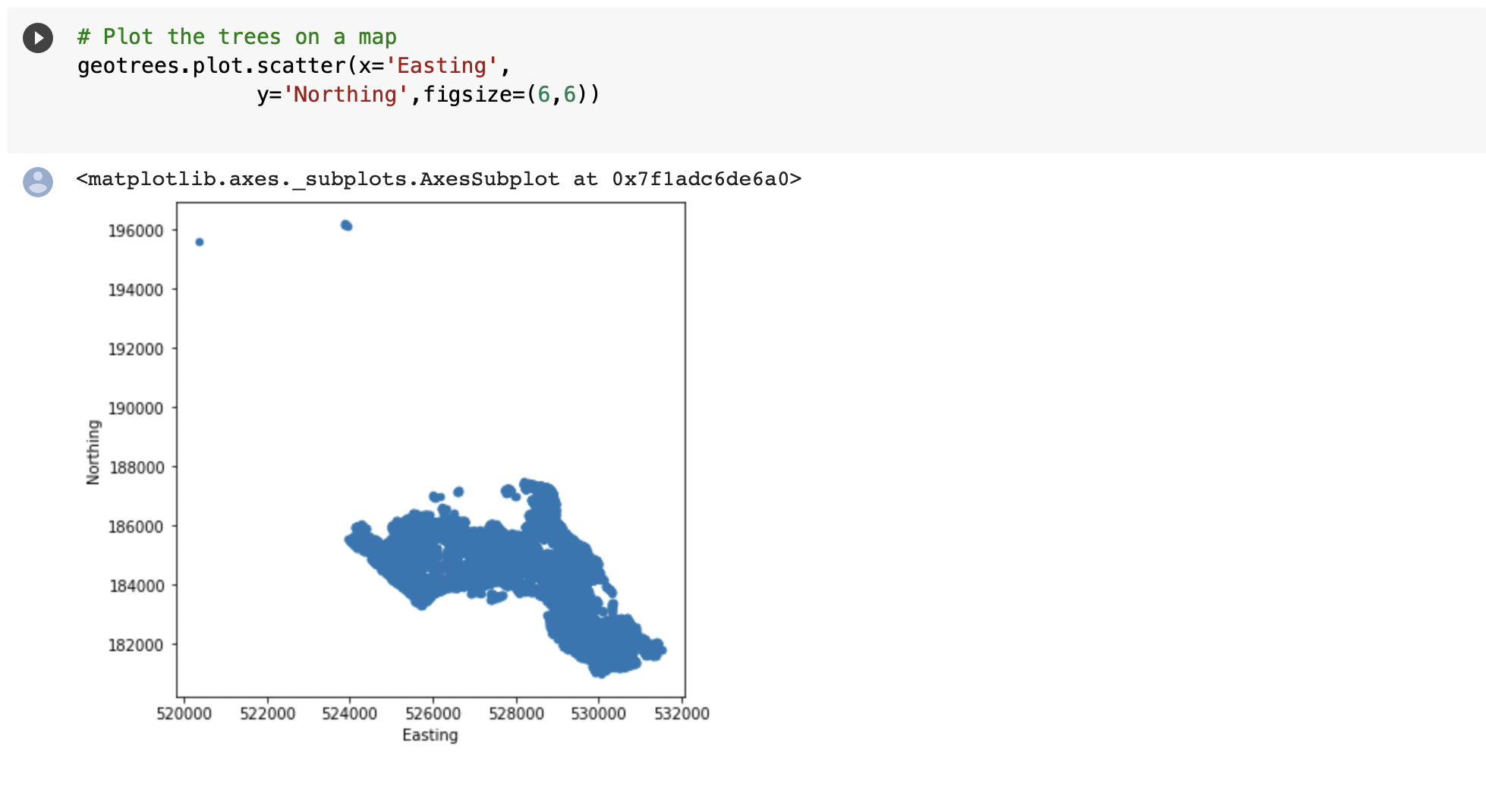
⇨ Identifying crazy outliers in all datasets using boxplot to check potential errors
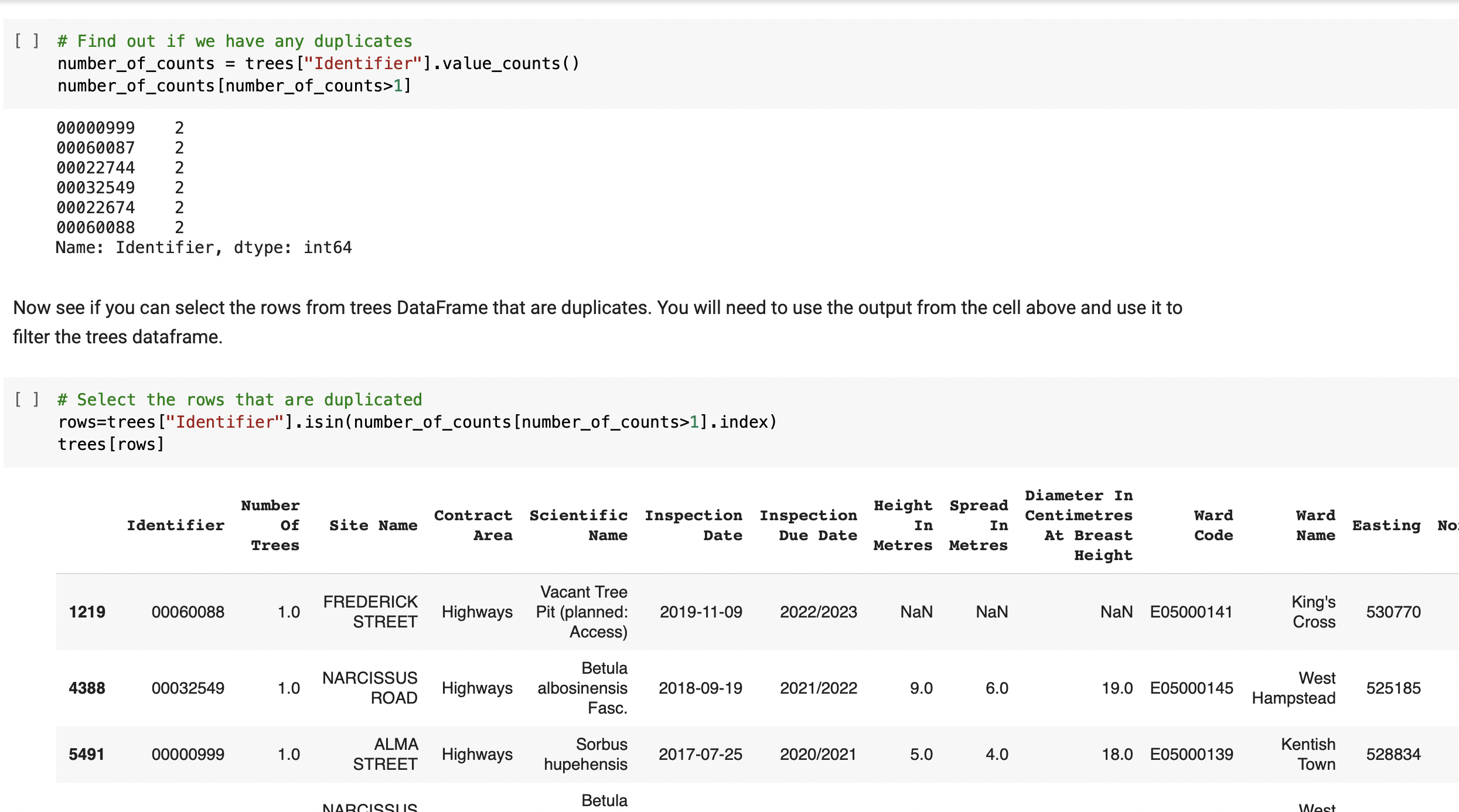
⇨ Identifying duplicates
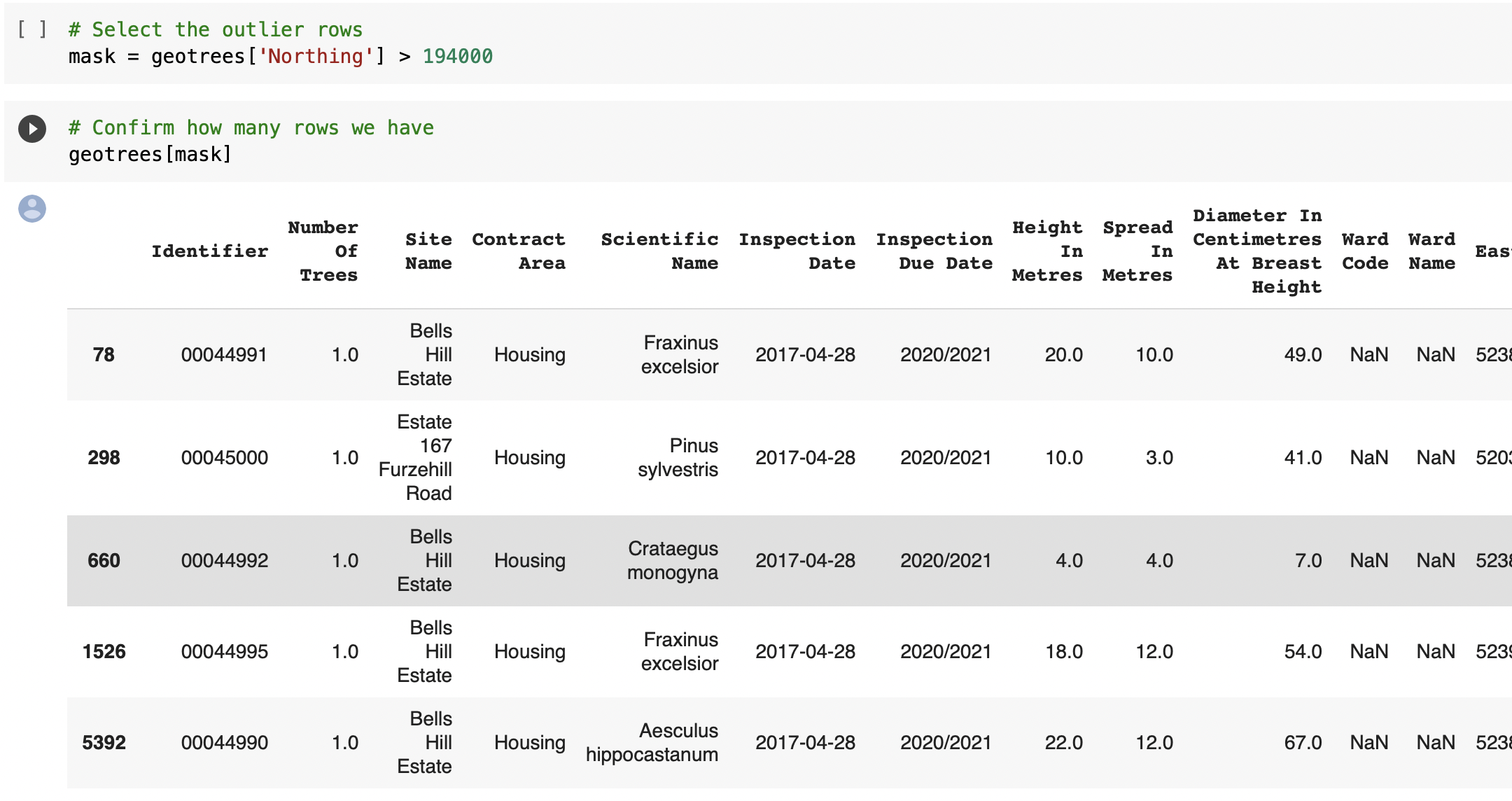
⇨ Identifying geolocation issues to find data for trees outside our area
⇨ Identyfying unmatched data to find trees without matching environmental data
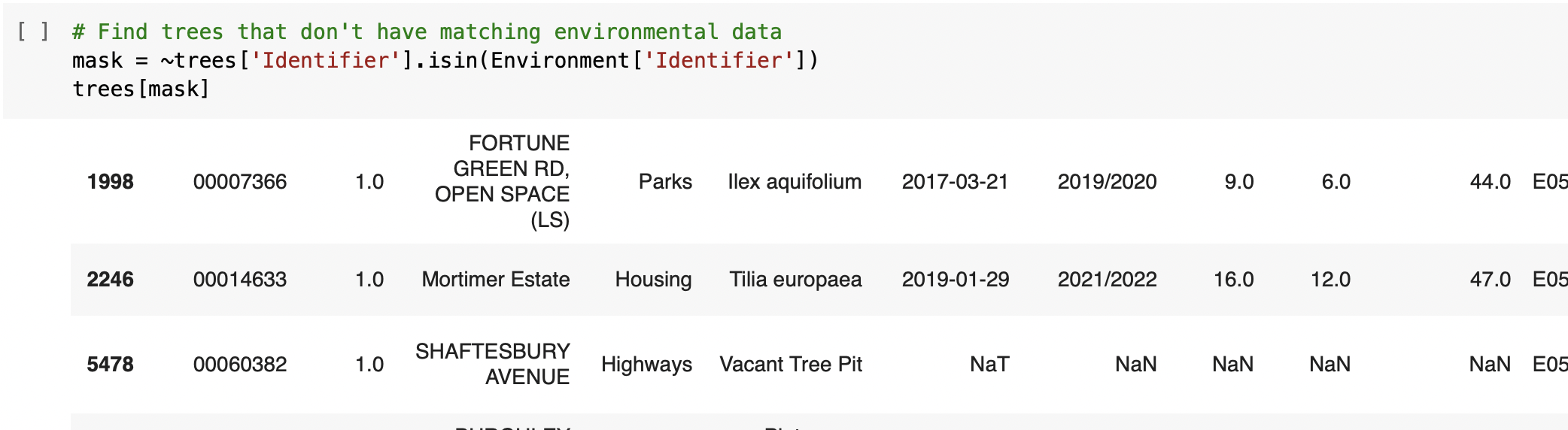
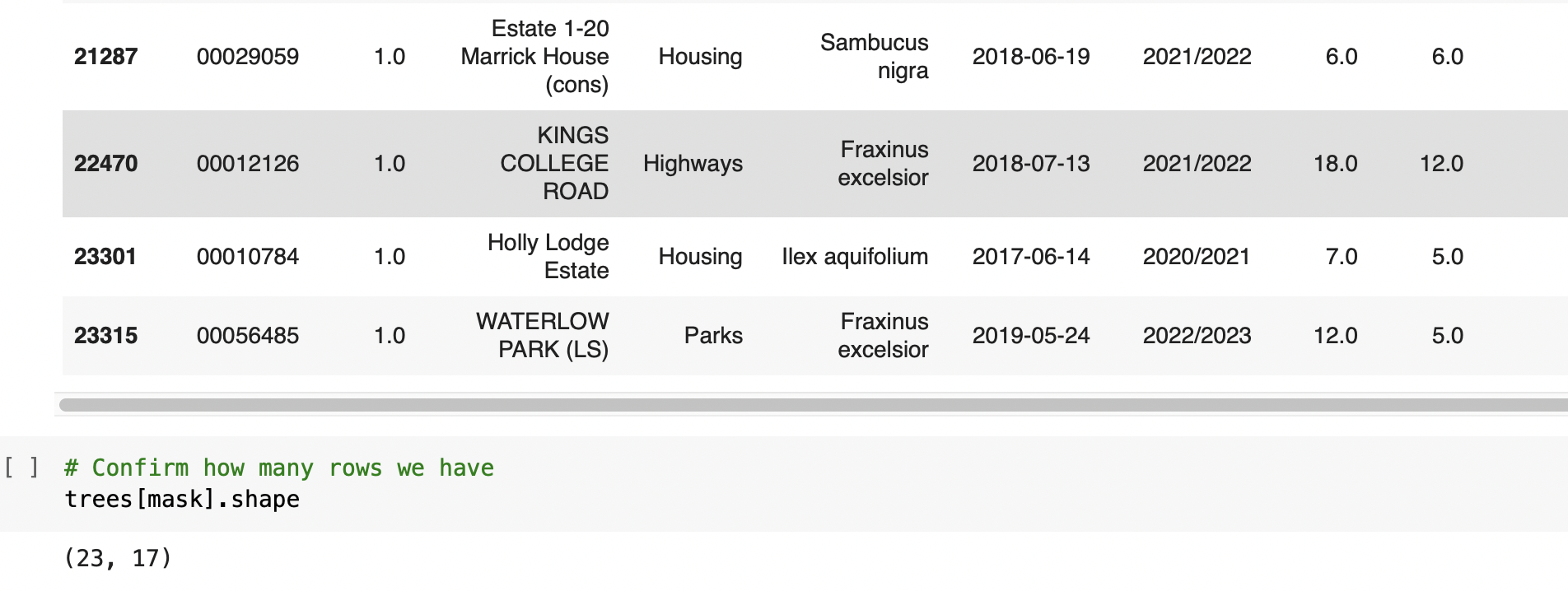
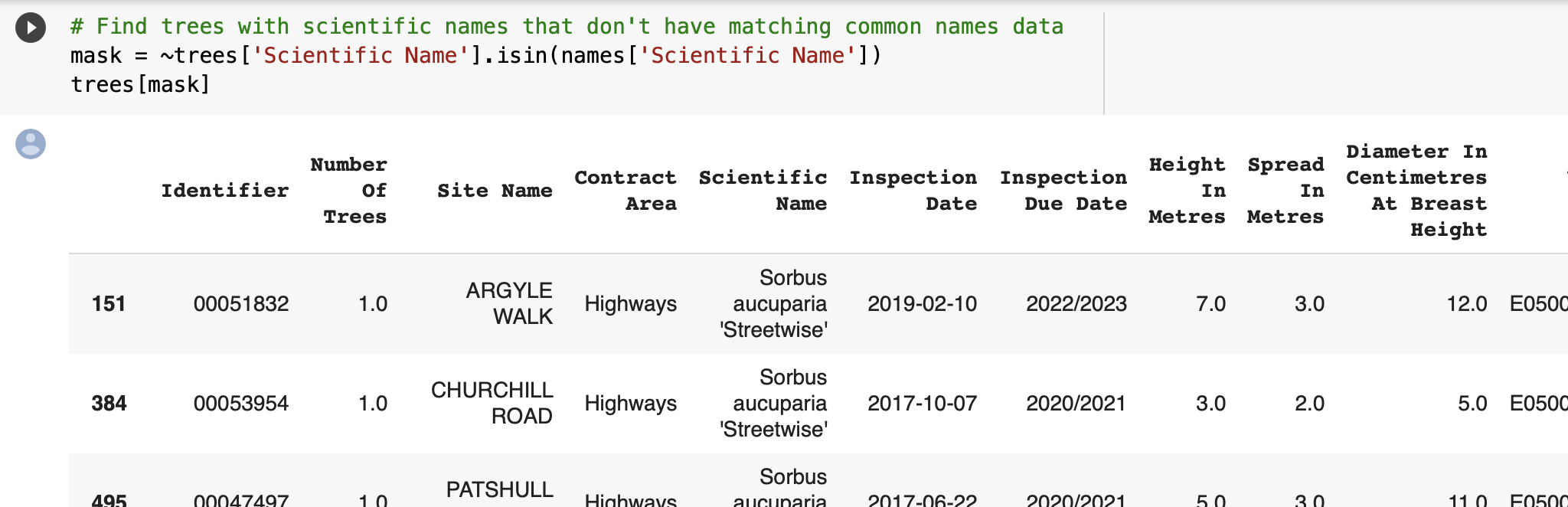
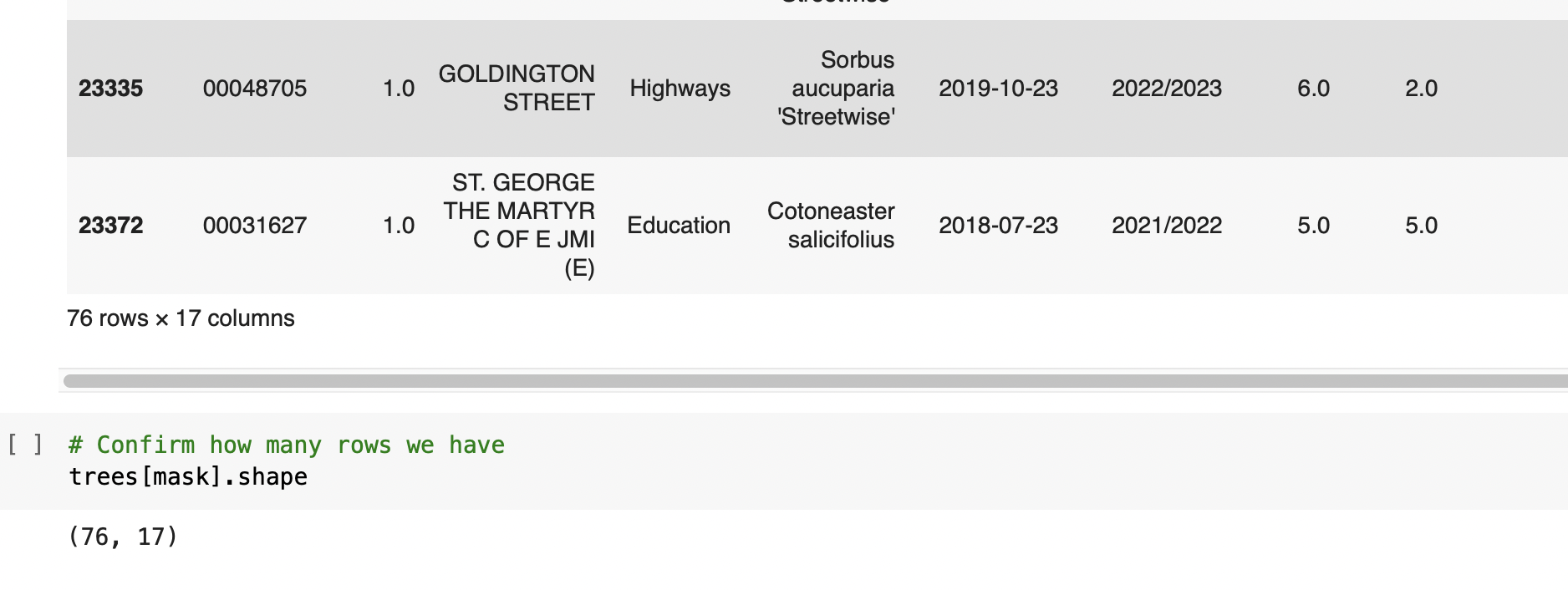
✔️ Problem with Data Quality (lots of missing values, outliers which we can classify like errors, some duplicated data, unmached data within data sets)
✔️ Problem with Data Sensitivity(data scraped from website without permission, data from council databases for internal use)
✔️ Not enough informations to complete cauncil initiatives(about park locations, interesting or planted trees)
✔️ Importance of Data Quality
✔️ Importance of Data Sensitivity and Ownership