TECH-409: Add endpoint for building block in product (BE) #30
Conversation
| return { | ||
| add, | ||
| aggregateByProduct, | ||
| aggregateByProductId, |
There was a problem hiding this comment.
Why do aggregateByProduct and aggregateByProductId have different logic? I would expect them to do the same, the only difference being the expected argument (product vs product id). If we want them to act differently, we should name them appropriately - so that the naming describes what the method does.
There was a problem hiding this comment.
I changed those names to:
aggregateByProduct => aggregateCompatibilityByProduct
aggregateByProductId => aggregateBBDetailsByProductId
server/src/useCases/report/productTestCases/handleGetProductDetailsRequest.js
Outdated
Show resolved
Hide resolved
| const aggregatedResult = result[0]; | ||
|
|
||
| let tempItem = {}; | ||
| aggregatedResult.data = aggregatedResult.data.reduce((items, item) => { |
There was a problem hiding this comment.
this reduction is hard to understand for me, what the point is
can you make it a bit more clear, either with comments or better by splitting into smaller function, which names describe what is going on
There was a problem hiding this comment.
I added a comment
There was a problem hiding this comment.
I really have a hard time understanding the logic around tempItem, it took me a long time to get this, which mean this code is of poor quality I'm afraid.
First of, does the item consist of only two fields, passed and uri? If no, we are replacing just the boolean passed, without replacing the other values in item. Even if item is only two fields for now, it is cleaner to just replace, in case new fields will be added with time. Otherwise this might become confusing why some fields change while others don't.
Moreover, when doing an array reduction, mutating state outside of the reduce function is considered a bad practice (like you do with tempItem), primarily because you are mixing functional and imperative programming.
Next problem is that you are overwriting aggregatedResult.data - which you shouldn't after operations like this it's cleaner to create new variables rather than modify the ones coming from the db.
You are also assuming that we are ordering the results by endpoint. I will go with this for now.
Finally, you don't need to overcomplicate the final if - in reality you are just interested in putting an item where passed is failed into the result array, so you can just override that item even if wasn't passed.
I've rewritten your method and got something like this:
// reduce to one item per endpoint, where we always prefer the ones that didn't pass over the ones that did
const aggregatedData = aggregatedResult.data.reduce((items, item) => {
const lastItemIndex = items.length - 1;
const lastItem = items[lastItemIndex];
if (item.uri !== lastItem.uri) {
// add new item
items.push(item);
} else if (!item.passed) {
// replace with the failed item
items[lastItemIndex] = item;
}
return items;
}
Let me know if this would work as the aggregation.
There was a problem hiding this comment.
Thanks for the review @pgesek. Your method works, I just needed to edit in 2 places. This is how the response looks
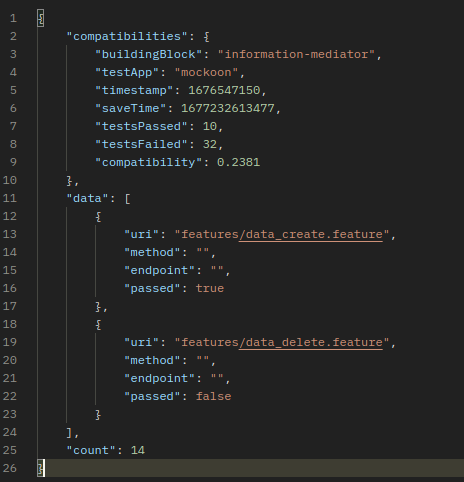
This contains all the data required for the second page. Let me know please if you think naming is bad, or it should be grouped differently in your opinion.
|
|
||
| Object.assign(aggregatedResult, { count: aggregatedResult.data.length }); | ||
|
|
||
| aggregatedResult.data = offset !== undefined |
There was a problem hiding this comment.
wouldn't it be more effective to reduce after slicing?
Moreover, shouldn't we be paginating in the database instead of in-memory? What data volume do we expect here?
There was a problem hiding this comment.
We can reduce before slicing, yes.
It's paginated after reduce because from the database we get multiple results for one endpoint,
example: data/create returns an element per scenario, let's say it has 3 scenarios ( 2 succeeded, 1 failed )
.reduce in this case creates smaller list from all of those examples (for each endpoint), and checks if any of them failed, if yes we set the .passed property to false. After the list is ready with 1 element per endpoint we paginate it.
Let me know if that's clear. If not I'll try to explain in better
There was a problem hiding this comment.
In general this whole endpoint seems very weird. Can you explain what are you trying to return? As in, how the json should look like and what's the point of this?
I've take a look at the ticket, but there's nothing there about these aggregations, slicing names, etc.
There was a problem hiding this comment.
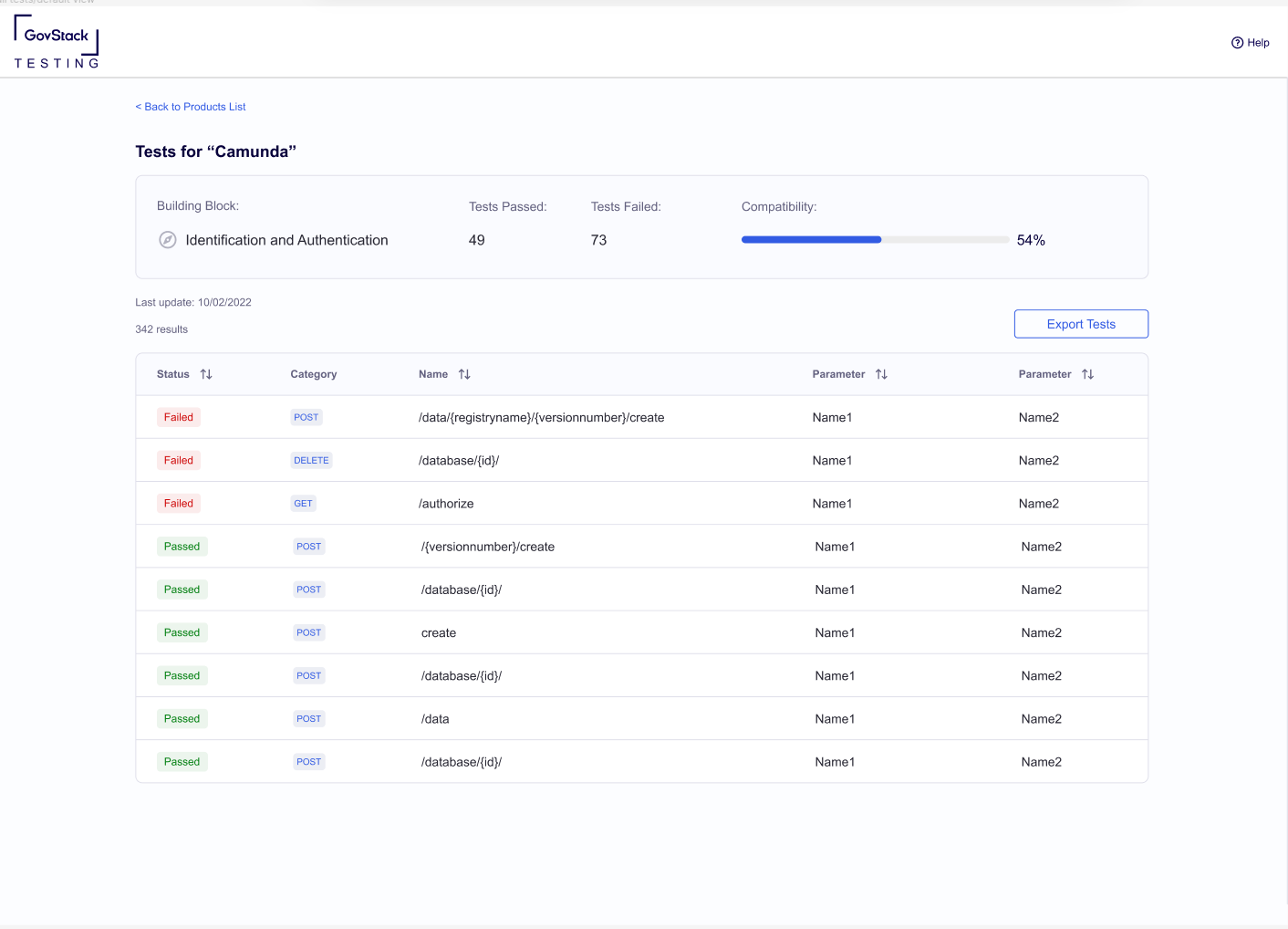
It should return all necessary data for this page.
There was a problem hiding this comment.
I sliced it because in the database endpoint and method are stored as tags from gherkin file scenario.
etc @method=GET. Do you think we should send it as it comes?
There was a problem hiding this comment.
I think in that case that's fine, we should probably move this slicing logic to some utility class reused globally though
There was a problem hiding this comment.
regarding the data:
- is method used anywhere for example? if not we should probably drop it
If you are building a new data model here and not returning as is from the database - you should explicitly build a new model in the reduce method, not reuse what you have (but in a way that switches up some fields)
There was a problem hiding this comment.
one more thing - if you build a util that will do this string clean up for you, you can just use it in the reduce method as you're putting this data together - in order to save the iterations needed
There was a problem hiding this comment.
method is used in 2 places - if you mean @method=
I added slicing those strings to mondodb aggregation.
I'm not sure if i completely understood If you are building a new data model here and not returning as is from the database - you should explicitly build a new model in the reduce method, not reuse what you have (but in a way that switches up some fields) could you provide more information? For now i decided to build the object after pagination.
| // eslint-disable-next-line class-methods-use-this, no-unused-vars | ||
| const { ObjectId } = mongoose.Types; | ||
|
|
||
| // class-methods-use-this |
There was a problem hiding this comment.
what does this mean? isn't this from eslint?
There was a problem hiding this comment.
removed
| ]; | ||
| } | ||
|
|
||
| // class-methods-use-this |
There was a problem hiding this comment.
removed
| const aggregatedResult = result[0]; | ||
|
|
||
| let tempItem = {}; | ||
| aggregatedResult.data = aggregatedResult.data.reduce((items, item) => { |
There was a problem hiding this comment.
I really have a hard time understanding the logic around tempItem, it took me a long time to get this, which mean this code is of poor quality I'm afraid.
First of, does the item consist of only two fields, passed and uri? If no, we are replacing just the boolean passed, without replacing the other values in item. Even if item is only two fields for now, it is cleaner to just replace, in case new fields will be added with time. Otherwise this might become confusing why some fields change while others don't.
Moreover, when doing an array reduction, mutating state outside of the reduce function is considered a bad practice (like you do with tempItem), primarily because you are mixing functional and imperative programming.
Next problem is that you are overwriting aggregatedResult.data - which you shouldn't after operations like this it's cleaner to create new variables rather than modify the ones coming from the db.
You are also assuming that we are ordering the results by endpoint. I will go with this for now.
Finally, you don't need to overcomplicate the final if - in reality you are just interested in putting an item where passed is failed into the result array, so you can just override that item even if wasn't passed.
I've rewritten your method and got something like this:
// reduce to one item per endpoint, where we always prefer the ones that didn't pass over the ones that did
const aggregatedData = aggregatedResult.data.reduce((items, item) => {
const lastItemIndex = items.length - 1;
const lastItem = items[lastItemIndex];
if (item.uri !== lastItem.uri) {
// add new item
items.push(item);
} else if (!item.passed) {
// replace with the failed item
items[lastItemIndex] = item;
}
return items;
}
Let me know if this would work as the aggregation.
| aggregatedResult.data.forEach((item) => { | ||
| const { method, endpoint } = item; | ||
| // slice by @method= length | ||
| item.method = method.length > 0 ? method[0].slice(8) : ''; |
There was a problem hiding this comment.
why are we slicing this btw?
|
|
||
| Object.assign(aggregatedResult, { count: aggregatedResult.data.length }); | ||
|
|
||
| aggregatedResult.data = offset !== undefined |
There was a problem hiding this comment.
In general this whole endpoint seems very weird. Can you explain what are you trying to return? As in, how the json should look like and what's the point of this?
I've take a look at the ticket, but there's nothing there about these aggregations, slicing names, etc.
| const lastItemIndex = items.length - 1; | ||
| const lastItem = items[lastItemIndex]; | ||
|
|
||
| if (lastItem === undefined || item.uri !== lastItem.uri) { |
There was a problem hiding this comment.
I imagine the undefined check is for the first time we run?
I would prefer to modify the lastItem assignment then - = lastItemIndex < 0 ? null : items{lastItemIndex[
the current way probably works, but it's because of JS quirks - I wouldn't count it on being 100% portable
| ? aggregatedData.slice(offset, limit + offset) : aggregatedData.slice(0, limit); | ||
|
|
||
| // build response object | ||
| const finalResult = {}; |
There was a problem hiding this comment.
So you removed the slicing of strings? I though it will become a util?
There was a problem hiding this comment.
I added it in the Mongodb aggregation instead
Added endpoint to get bb details for a product. Response example:
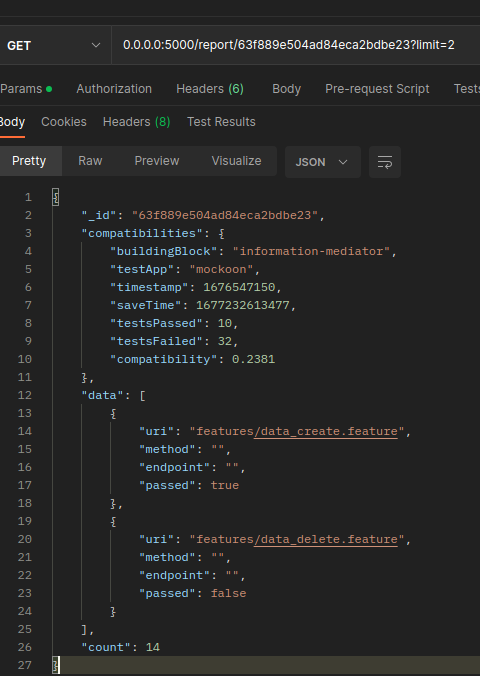
Description:
Mock: https://www.figma.com/file/9XudBIl7YAt3aH1nMBoO4L/govstack?node-id=41%3A2210&t=xjFQf3YJda8qpGhc-0
Acceptance criteria:
it’s possible to send a request to get a list of tests
each test contains the necessary fields to display information from mock
request supports pagination
TICKET: https://govstack-global.atlassian.net/browse/TECH-409