![]()



GrammarViz 3.0 source code public repository. This code is released under GPL v.2.0.
For the detailed software description, please visit our demo site.
GrammarViz 3.0 is a software for time series exploratory analysis with GUI and CLI interfaces. The GUI enables interactive time series exploration workflow that allows for variable length recurrent and anomalous patterns discovery from time series [4]:
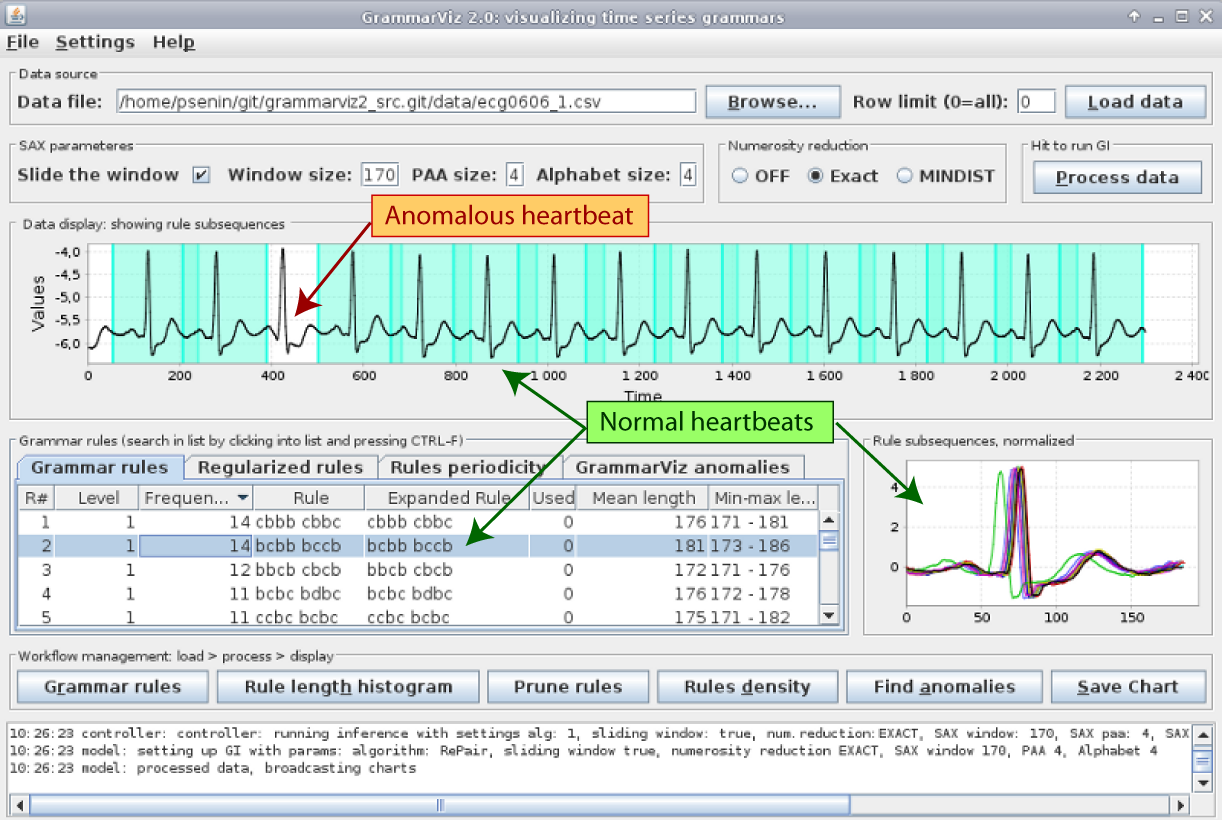
It is implemented in Java and is based on continuous signal discretization with SAX, Grammatical Inference with Sequitur and Re-Pair, and algorithmic (Kolmogorov) complexity.
In contrast with 2.0, GrammarViz 3.0 introduces an approach for the grammar rule pruning and the automated discretization parameters selection procedure based on the greedy grammar rule pruning and MDL -- by sampling a possible parameters space, it finds a parameters set which produces the most concise grammar describing the observed time series the best, which often is close to the optimal. (here concise and describing are based on other specific criteria).
It also implements the "Rule Density Curve" and "Rare Rule Anomaly (RRA)" algorithms for time series anomaly discovery [5], that significantly outperform HOT-SAX algorithm for time series discord discovery, which is current state of the art. In the table below, the algorithms performance is measured in the amount of calls to the distance function (less is better). The last column shows the RRA performance improvement over HOT-SAX:
| Dataset and SAX parameters | Dataset size | Brute Force | HOT-SAX | RRA | Reduction |
|---|---|---|---|---|---|
| Daily commute (350,15,4) | 17,175 | 271,442,101 | 879,067 | 112,405 | 87.2% |
| Dutch power demand (750,6,3) | 35,040 | 1.13 * 10^9 | 6,196,356 | 327,950 | 95.7% |
| ECG 0606 (120,4,4) | 2,300 | 4,241,541 | 72,390 | 16,717 | 76.9% |
| ECG 308 (300,4,4) | 5,400 | 23,044,801 | 327,454 | 14,655 | 95.5% |
| ECG 15 (300,4,4) | 15,000 | 207,374,401 | 1,434,665 | 111,348 | 92.2% |
| ECG 108 (300,4,4) | 21,600 | 441,021,001 | 6,041,145 | 150,184 | 97.5% |
| ECG 300 (300,4,4) | 536,976 | 288 * 10^9 | 101,427,254 | 17,712,845 | 82.6% |
| ECG 318 (300,4,4) | 586,086 | 343 * 10^9 | 45,513,790 | 10,000,632 | 78.0% |
| Respiration, NPRS 43 (128,5,4) | 4,000 | 14,021,281 | 89,570 | 45,352 | 49.3% |
| Respiration, NPRS 44 (128,5,4) | 24,125 | 569,753,031 | 1,146,145 | 257,529 | 77.5% |
| Video dataset (150,5,3) | 11,251 | 119,935,353 | 758,456 | 69,910 | 90.8% |
| Shuttle telemetry, TEK14 (128,4,4) | 5,000 | 22,510,281 | 691,194 | 48,226 | 93.0% |
| Shuttle telemetry, TEK16 (128,4,4) | 5,000 | 22,491,306 | 61,682 | 15,573 | 74.8% |
| Shuttle telemetry, TEK17 (128,4,4) | 5,000 | 22,491,306 | 164,225 | 78,211 | 52.4% |
[1] Lin, J., Keogh, E., Wei, L. and Lonardi, S., Experiencing SAX: a Novel Symbolic Representation of Time Series. DMKD Journal, 2007.
[2] Nevill-Manning, C.G., Witten, I.H., Identifying Hierarchical Structure in Sequences: A linear-time algorithm. arXiv:cs/9709102, 1997.
[3] Larsson, N. J., Moffat, A., Offline Dictionary-Based Compression, IEEE 88 (11): 1722–1732, doi:10.1109/5.892708, 2000.
[4] Pavel Senin, Jessica Lin, Xing Wang, Tim Oates, Sunil Gandhi, Arnold P. Boedihardjo, Crystal Chen, and Susan Frankenstein. 2018. GrammarViz 3.0: Interactive Discovery of Variable-Length Time Series Patterns. ACM Trans. Knowl. Discov. Data 12, 1, Article 10 (February 2018), 28 pages. DOI: https://doi.org/10.1145/3051126
[5] Senin, P., Lin, J., Wang, X., Oates, T., Gandhi, S., Boedihardjo, A.P., Chen, C., Frankenstein, S., Lerner, M., Time series anomaly discovery with grammar-based compression, The International Conference on Extending Database Technology, EDBT 15.
We use Maven and Java 8 to build an executable. However, Github actions designed to test the build using a matrix of Linux, Windows, and MacOS hosting Java 8, 11, and 17 -- check the builds by clicking "Java CI with Maven" badge at the README top. Below is the build trace from my windows machine:
$ java -version openjdk version "1.8.0_292" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_292-b10) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.292-b10, mixed mode) $ mvn -version Apache Maven 3.8.4 (9b656c72d54e5bacbed989b64718c159fe39b537) Maven home: C:\ProgramData\chocolatey\lib\maven\apache-maven-3.8.4 Java version: 1.8.0_302, vendor: ojdkbuild, runtime: C:\Program Files\ojdkbuild\java-1.8.0-openjdk-1.8.0.302-1\jre Default locale: en_US, platform encoding: Cp1252 OS name: "windows 10", version: "10.0", arch: "amd64", family: "windows" $ mvn package -Psingle [INFO] Scanning for projects... .... [INFO] ------------------------------------------------------- [INFO] T E S T S [INFO] ------------------------------------------------------- [INFO] Running net.seninp.grammarviz.anomaly.TestRRAanomaly brute force discord '#0', distance: 9.949874371066695, position: 363, info: position 363, NN distance 9.949874371066695, elapsed time: 0d0h0m2s868ms, distance calls: 1957201 hotsax hash discord 'bca', distance: 9.949874371066695, position: 363, info: position 363, NN distance 9.949874371066695, elapsed time: 0d0h0m0s175ms, distance calls: 9289 10:49:39.684 [main] DEBUG net.seninp.gi.sequitur.SequiturFactory - Discretizing time series... 10:49:39.701 [main] DEBUG net.seninp.gi.sequitur.SequiturFactory - Inferring the grammar... 10:49:39.763 [main] DEBUG net.seninp.gi.sequitur.SequiturFactory - Collecting the grammar rules statistics and expanding the rules... 10:49:39.779 [main] DEBUG net.seninp.gi.sequitur.SequiturFactory - Mapping expanded rules to time-series intervals... 10:49:40.059 [main] DEBUG net.seninp.grammarviz.anomaly.RRAImplementation - position 366, length 101, NN distance 0.09900990099010303, elapsed time: 0d0h0m0s235ms, distance calls: 11553 10:49:40.059 [main] INFO net.seninp.grammarviz.anomaly.RRAImplementation - 1 discords found in 0d0h0m0s235ms RRA discords 'pos,calls,len,rule 366 11553 101 7', distance: 0.09900990099010303, position: 366, info: position 366, length 101, NN distance 0.09900990099010303, elapsed time: 0d0h0m0s235ms, distance calls: 11553 [INFO] Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 4.165 s - in net.seninp.grammarviz.anomaly.TestRRAanomaly [INFO] Running net.seninp.tinker.TestInterval [INFO] Tests run: 5, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.003 s - in net.seninp.tinker.TestInterval [INFO] [INFO] Results: [INFO] [INFO] Tests run: 6, Failures: 0, Errors: 0, Skipped: 0 [INFO] [INFO] [INFO] --- jacoco-maven-plugin:0.8.7:report (report) @ grammarviz2 --- [INFO] Loading execution data file C:\Users\seninp\git\grammarviz2_src\target\jacoco.exec [INFO] Analyzed bundle 'GrammarViz2' with 25 classes [INFO] [INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ grammarviz2 --- [INFO] [INFO] --- maven-assembly-plugin:3.3.0:single (make-assembly) @ grammarviz2 --- [INFO] Building jar: C:\Users\seninp\git\grammarviz2_src\target\grammarviz2-1.0.0-SNAPSHOT-jar-with-dependencies.jar [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 35.551 s [INFO] Finished at: 2021-12-29T10:49:59+01:00 [INFO] ------------------------------------------------------------------------
To run the GrammarViz 3.0 GUI use net.seninp.grammarviz.GrammarVizGUI class, or run the jar from the command line: $ java -Xmx4g -jar target/grammarviz2-0.0.1-SNAPSHOT-jar-with-dependencies.jar (here I have allocated max of 4Gb of memory for Grammarviz).
By using CLI as discussed in these tutorials, it is possible to save the inferred grammar, motifs, and discords.
